Аналитика и статистика в Telegram любого канала и чата

Количество активных пользователей Telegram достигло 200 млн человек в месяц. Маркетологам важно знать, что делают эти люди: какие каналы читают, как активно переписываются.
Разбираемся, как анализировать площадки в Telegram и смотреть статистику с помощью бесплатных инструментов.
Какие площадки и метрики есть в Telegram
В Telegram есть два вида площадок — каналы и чаты. У них свои метрики и возможности их аналитики.
Канал — место, где появляются сообщения только от авторов.
Показатели для измерения в каналах:
- Подписчики;
- Просмотры.
Группа/Чат — диалоги с большим количеством участников.
Показатели для измерения:
- Количество участников.
- Количество сообщений в день, в месяц и т.д.
- Активность каждого участника.
Инструменты для анализа Telegram
На рынке создано несколько инструментов для аналитики Telegram. Рассмотрим три из них: для анализа каналов, анализа чатов и контента.
Аналитика каналов в Telegram: Tgstat
Это некоммерческий проект, где собраны данные более 10 000 русскоязычных Telegram каналов. При этом вся статистика Telegram каналов открыта, ее может смотреть любой желающий. Данные автоматически обновляются каждый день.
На сайте проекта также создан рейтинг Telegram-каналов, где площадки разделены по разным категориям и сравниваются между собой по нескольким параметрам: подписчики, скорость прироста, просмотры, индекс цитирования. При планировании рекламы можно использовать эти данные Telegram аналитики.
Tgstat дает следующую статистику Telegram каналов:
- Количество подписчиков.
- Средний охват публикации (при расчете учитываются только собственные записи канала, без репостов).
- Среднее количество просмотров за сутки (также без расчета репостов).
- Количество репостов — сколько раз другие публичные каналы, участвующие в рейтинге, сделали репост записей канала.
- Количество упоминаний — сколько раз другие публичные каналы из рейтинга упоминали анализируемый канал.
- Частота публикаций в день.
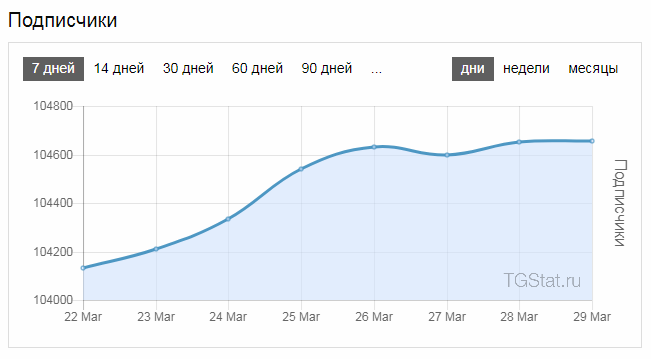
Инструмент строит графики на основании статистическиих данных аналитики Telegram. Их можно перестроить за разные периоды времени.
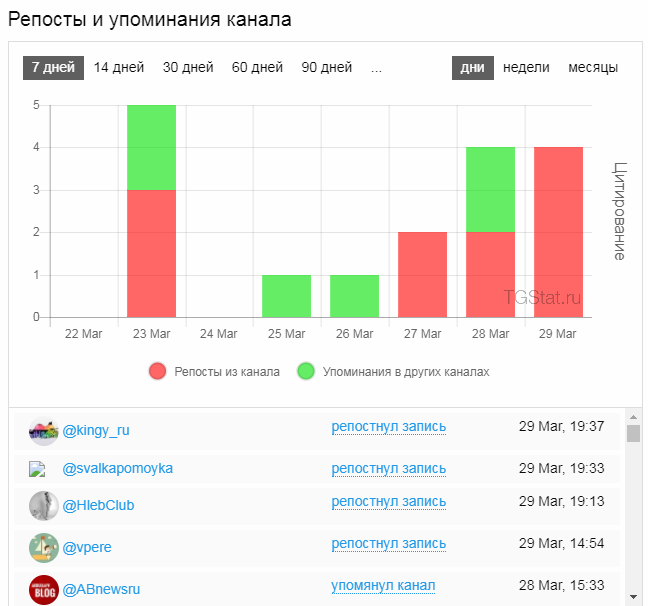
Ограниченный функционал сервиса доступен в боте @TGStat_Bot. Здесь собирается сводная статистика по Telegram.
Аналитика чатов в Telegram: Combot
Для анализа чата, добавьте в него Combot. Инструмент анализирует активность участников и популярность чата.
В Telegram вы сможете найти его по ссылке: @combot. Чтобы увидеть статистику чатов в Telegram, вызовите бота в переписке по команде /stat. Он отправит ссылку на статистику для вашей группы. Статистика Телеграм канала расширится на порядок.
Combot дает статистику по следующим показателям:
- Количество сообщений (за все время, в среднем в день, в среднем в час).
- Активность пользователей (количество активных пользователей за выбранный период, среднее количество активных пользователей в день).
- Активность чата: график строится на основании количества и длины сообщений.
- Активность по времени суток.
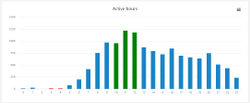
Также Combot показывает в Telegram статистику для каждого пользователя, определяет самых активных участников, количество дней, когда пользователи проявляют активность.
У сервиса есть свой рейтинг чатов. Здесь списки чатов разделены по странам, а также есть общий рейтинг для площадок со всего мира.
Аналитика контента в Telegram: Popsters
Чтобы найти самые популярные публикации и понять, какой контент лучше работает на канале, используйте Popsters. Сервис работает со всеми существующими каналами. Вам не нужно быть администратором или устанавливать бота, чтобы провести анализ. Благодаря этому можно сравнивать между данные статистики разных Телеграм каналов: например, чтобы оценить активность конкурентов или подобрать каналы для размещения рекламы.
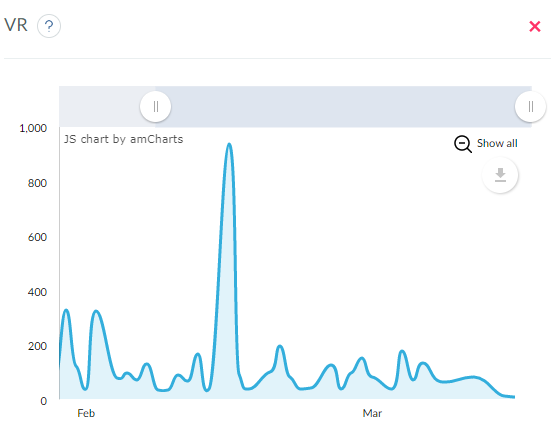
Инструмент находит посты, которые набрали больше всего просмотров или получили самый высокий VR (Visibility Rate). Эта метрика Telegram аналитики оценивает степень видимости публикаций, то есть, какой процент подписчиков видели пост.
В Popsters.ru можно узнать и оценить самые удачные дни недели и время суток для публикации.
А еще в Popsters можно выгрузить весь контент канала за нужный период.
Кроме того, сервис анализирует:
- VR по типу контента.
- VR по длине текста.
- Количество публикаций по длине текста.
- Количество публикаций по типу контента.
- Относительная активность по длине текста и типу контента.
- Просмотры публикации.
Вы можете изучить каждую метрику за необходимый период:
Выводы
- В Telegram есть разные виды площадок: каналы и группы (чаты).
- В Telegram не много показателей для оценки. У каналов это подписчики и просмотры, у чатов — участники и активность.
- Чтобы проанализировать канал в Telegram, используйте сервис Тгстат. Он показывает статистику Telegram: о просмотрах, подписчиках, репостах и упоминаниях канала.
- Для анализа чата используйте Комбот. Он считает активность каждого пользователя и общую активность переписки.
- Для оценки контента используйте Popsters. Он находит самые популярные публикации и анализирует успешность публикаций относительно разных параметров — времени, когда запись была опубликована, длины текста, формата контента.
Попробуйте бесплатный пробный тариф Popsters чтобы получить статистику активности до 10 любых страниц в следующие 7 дней
Как найти все сообщения в чате телеграма от конкретного человека
Иногда вам может понадобится найти все свои сообщения в чате телеграма или сообщения от какого-то конкретного пользователя. Это довольно просто сделать, разберем по шагам.
Шаг 1: Зайдите в нужный вам чат и кликните на иконку поиска сверху справа, как показано на скриншоте

Шаг 2: Теперь на левой панели вверху найдите и кликните иконку юзера

Шаг 3: В открывшемся окне будут показаны все участники этого чата рассортированные по дате последнего посещения. Найдите нужного и кликните на него

Шаг 4: В результате, в левой панели будут показаны все результаты поиска сортированные по дате. Кликнув на сообщение, чат промотается до вашего поста

Этот порядок действий работает и в приложении на телефон, но удобнее работать на десктопе. Ссылка, чтобы скачать приложение тут.
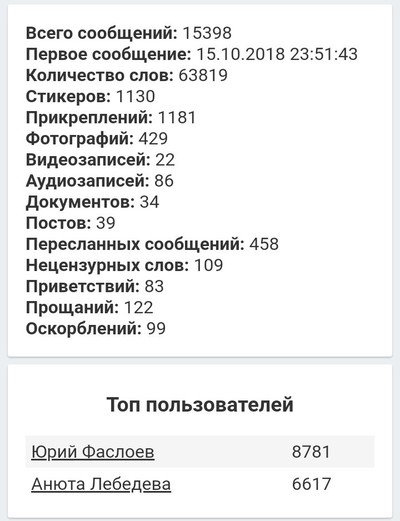
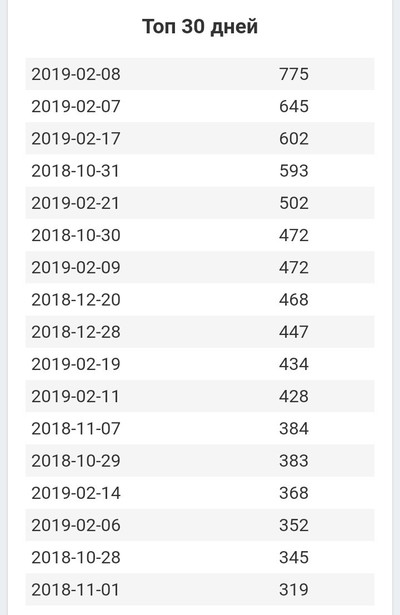
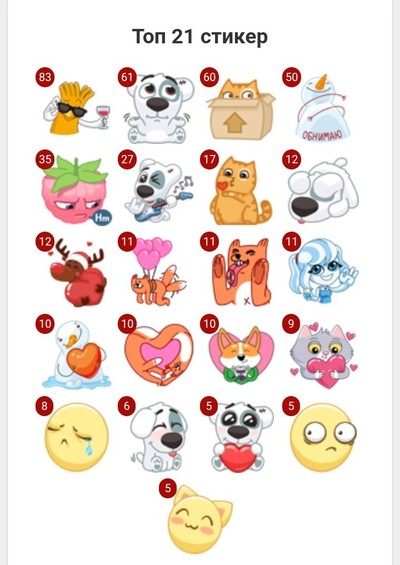
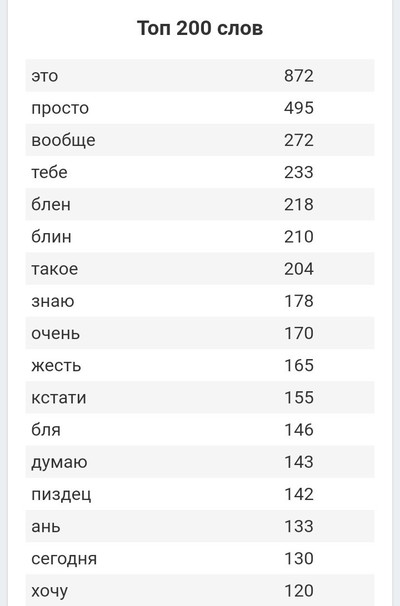
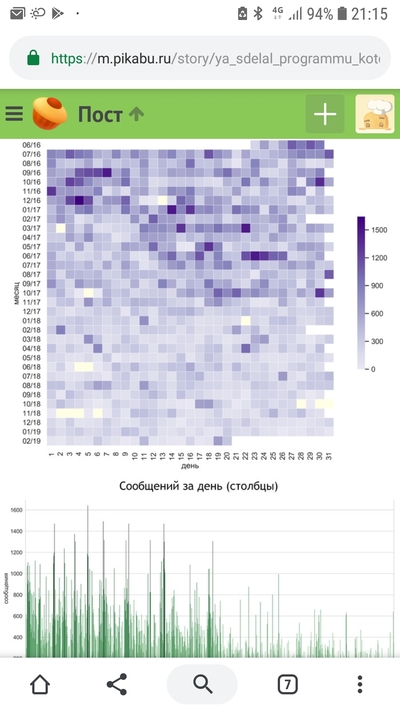
Я сделал программу, которая анализирует историю сообщений в Telegram и/или ВК. Вот визуализация отношений на расстоянии с моей девушкой

• Все данные взяты с нашей с девушкой переписки в Telegram и ВКонтакте. Мы перешли на Telegram где-то в мае 2017.
• Если хотите попробовать на своей переписке, то все инструкции можно найти в файле README на репозитории. Необходима будет установка Python3.6+ и нескольких пакетов для него, с кодом можно не работать — я добавил простенький графический интерфейс. Сама программа делает немного больше чем то, что я вместил в пост.
• Слова в посте перед визуализацией были профильрованные вручную мной так, что остались только наиболее употребляемые и наполненные смыслом слова (без «я», «ну», «да» и так далее). А также я перевел их с украинского на русский 🙂
• Несколько слов насчет самих графиков. Я приезжал в родной город к девушке где-то раз в месяц и на зимние/летние каникулы в университете (скачки вниз в графике в эти периоды). Этой осенью она сама приехала учиться в мой город и университет, поэтому мы стали больше времени проводить вместе. Это и то, что мы уже почти все о друг-друге знаем, обьясняет постепенное падение в количестве сообщений.

633 поста 2.9K подписчиков
Правила сообщества
1. Не нарушать правил pikabu
2. Постить контент относящийся к теме сообщества
Капец, за 1 день больше сообщений с 1 человеком чем у меня за год со всеми



хех, у меня тут было бы везде по нулям
1600 сообщений в день. Если брать день без сна в 16 часов то это 100 сообщений в час. Почти 2 сообщения в минуту, весь день. Капец
Батя использовалось чаще, чем люблю? Это прекрасно!
График сообщений за минуту странный. Или он показывает самый активный период времени?
В среднем 365 сообщений в день? Пиздец.
Ну у нас с мужем самые часто употребляемые слова в ватцапе:
Никакого интима еще не было как я понял 😀
«Работу вы проделали большую, сложную и никому не нужную.» (с)
Алексей Максимович Пешков (Горький)
Батя завтра понял хочу сегодня спать очень сейчас немного

• Все данные взяты с нашей с девушкой переписки в Telegram и ВКонтакте. Мы перешли на Telegram где-то в мае 2017.
• Если хотите попробовать на своей переписке, то все инструкции можно найти в файле README на репозитории. Необходима будет установка Python3.6+ и нескольких пакетов для него, с кодом можно не работать — я добавил простенький графический интерфейс. Сама программа делает немного больше чем то, что я вместил в пост.
• Слова в посте перед визуализацией были профильрованные вручную мной так, что остались только наиболее употребляемые и наполненные смыслом слова (без «я», «ну», «да» и так далее). А также я перевел их с украинского на русский 🙂
• Несколько слов насчет самих графиков. Я приезжал в родной город к девушке где-то раз в месяц и на зимние/летние каникулы в университете (скачки вниз в графике в эти периоды). Этой осенью она сама приехала учиться в мой город и университет, поэтому мы стали больше времени проводить вместе. Это и то, что мы уже почти все о друг-друге знаем, обьясняет постепенное падение в количестве сообщений.

Почему-то довольно часто вспоминаю свои отношения на расстоянии. Я тут поныть собираюсь, если что, так что дольше можно не читать. Захлёстывает чувство ностальгии, и я снова начинаю вспоминать редкие моменты встреч, чувство бессилия от того, что ты не можешь сорваться и приехать поддержать когда угодно, долгие ночные переписки, пока кто-то один не уснёт с телефоном в руках. Я всё жду, когда меня отпустит, но пока с этим никак. Да, образ размывается со временем, но сам факт его существования заставляет предаваться грёзам. Плюс ещё это «ах, если бы. «. Может, проблема в том, что ни к кому больше я таких чувств не испытывал. Мне приходится поглощать слезливые фильмы, дешёвенькое (или не очень) чтиво, чтобы проникнуться хотя бы чувствами героев, но это всё уходит, и я снова замыкаюсь на своих воспоминаниях.
Я знаю, что время вылечит меня окончательно, но просто устал. Это стрёмно. Плюс ещё весна надвигается. Мороз и яркое весеннее солнце, холодный ветер и подтаявший снег снова будут напоминать мне о наших прогулках по набережной, о том, как мы сидели на льду и обсуждали то, что с нами происходит. Вся моя жизнь окружена маяками, которые снова и снова заводят мои мысли в уже иссохшее русло, и с этим поделать ничего я не могу. Я просто устал. Надеюсь, когда-нибудь это пройдёт окончательно. Выговорился, спасибо за внимание.
«соскучился» есть, а «соскучилась» нет, ТС, стоит задуматься)

Заметил словосочетания дома хорошо и жди долго )
Я делал примерно тоже самое только в стиле таймлапс и на Unity https://vk.com/video40749676_456239018
Здорово, но длиннопосты уже как года два можно не делать одной картинкой
Я просто хочу сказать спасибо за внезапно пробудившееся чувство прекрасного. Теперь у меня есть новый фон для рабочего стола:
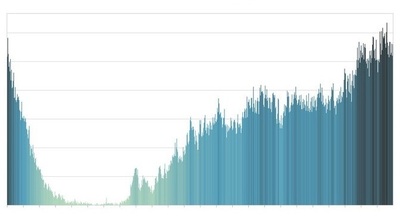
Опираясь на эту аналитику, можно сделать вывод, насколько пользователя устраивают отношения и сделать фичи для улучшения.
Дорогой программист @EomEr, а можно подробную инструкцию для тех, кто со всем этим не просто на «Вы», а на «Мой господин»? Я даже зарегистрировался на Пикабу ради этой просьбы.
Автор, почему может не воспринимать имена? Копирую имена с файла сформированного Vkopt, но при анализе останавливается на первом с ошибкой, что не соответствует ни одному имени
Можешь добавить функционал экспорта всей истории для создания облака слов? Пофиг, что будут местоимения, так хоть будет файл, с которым можно будет работать.
А еще лучше три таких файла Собственный/собеседника/общий
Это просто великолепно. А можно анализировать не с одним человеком,а сразу со всеми?
Шикарно, сам обожаю заниматься подобным, правда, у меня оно в основном только в голове или в таблицах в Экселе)
Только «по частоте», а не «за частотой».
сегодня очень сейчас спать — прям про мое состояние пермоментное
Можно было и в IT проекты Пикабушников)
Может, она комбат?
Аааа, тяжело быть тупым, ничегошеньки не понятно, как тут что нужно настроить 🙁
Дико извиняюсь, что веду себя, как блондинка, но я не знаю, что еще делать
Компухтер мне говорит, что «ValueError: source code string cannot contain null bytes»
Можешь посоветовать, что делать, если будет относительно свободная минута?
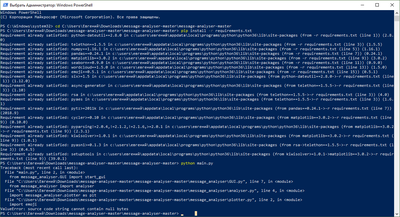
Вот такая ошибка, кто-нибудь сталкивался?
Батя знает что хочу спать.
c телегой не вышло ничего (скрины) https://i.imgur.com/KCUi5Iw.png (тут я всё стер, вбивал вручную копипаст не работает, но вбивал несколько раз) https://i.imgur.com/3kdu7dk.png (терминал)
и можно возможность складывать истории вк страниц и телеграмма
а то у меня 3 лога в целом, с какого-то времени на другую страницу вк перешли, а потом в телегу
хотелось бы сложить целиком (и возможность делить на промежутки тоже бы не помешала, но тут легче)
как долго он будет визуализировать сообщения? У меня все остановилось на
А дальше хз что делал
@EomEr, почему-то смайлы в barplot_emojis идут текстом, и не строится картинка по словам: OSError: cannot open resource
Благодарю за программу! (:
Без особых усилий разобрался что и как подключить, получил графики и статистику. Понял, что мы почти не общаемся голосовыми сообщениями, будем исправлять
Завтра проблемы, хочу спать. Как жизненно то
Как раз искал что нибудь, с чего начать изучать питон, заодно и аналитику посмотрю.
А у меня вордклауд не генерится
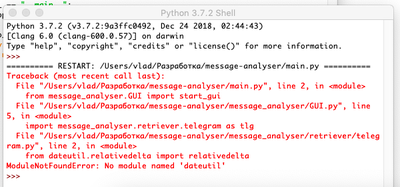
@EomEr помоги, пожалуйста. Всё сделал по инструкции, на этапе ввода api id и api hash, ввёл телефон, выдал ошибку о том, что нет интернет соединения и появилась красная надпись проверьте соединение. Нажав заново продолжить выдаёт такую ошибку:
Task exception was never retrieved
future: <Task finished coro=<MessageAnalyserGUI.raise_telegram_auth_frame.<local
s>.try_sign_in_and_continue() done, defined at C:\Users\Анна\Desktop\message-ana
lyser-master\message_analyser\ GUI.py:318 > exception=OperationalError(‘database i
Traceback (most recent call last):
line 325, in try_sign_in_and_continue
\ telegram.py «, line 46, in get_sign_in_results
client = TelegramClient(session_name, api_id, api_hash, loop=loop)
s\telethon\client\ telegrambaseclient.py «, line 223, in __init__
s\telethon\sessions\ sqlite.py «, line 186, in set_dc
s\telethon\sessions\ sqlite.py «, line 207, in _update_session_table
c.execute(‘delete from sessions’)
sqlite3.OperationalError: database is locked
в момент ввода api и номера телефона запрашиваются code и password
не подскажете, откуда мы их берем?)
ну сделал и сделал, а как таким пользоваться? часа три убил на ковыряние, но по итогу все равно ниче не понял
При запуске пустое окно с тремя галочками (скрин скинуть не могу). Всё по инструкции, python 3.6.8. Памахити :3
Привет, каким-то невероятным образом запустил это все, но после сохранения сообщений выдает return MyMessage(msg.message + (msg.sticker.attributes[1].alt if msg.sticker is not None else »),
AttributeError: ‘DocumentAttributeFilename’ object has no attribute ‘alt’
Можно узнать как пофиксить? Очень надо, готов задонатить
Привет) Если ты здесь и может помочь, помоги. Когда программа подводит итоги, она говорит, что за всё время писал только я , как это исправить?
а как ни будь перевести можно автоматом или только в переводчик кидать?
не знаю, тут ли автор, но был бы очень признателен если бы мне помогли осилить запуск сей программы. сделал все, что смог и пытался разобраться, но у меня либо не появляется ничего от слова совсем (просто пропадет консоль) либо в джупитер ноутбук выдает: «RuntimeError: Cannot close a running event loop».
помогите пожалуйста, если кто-нибудь знает, как ))
Привет! Я читала, что ты уже не поддерживаешь этот проект, но, может, есть решение.
У меня несколько раз загружается только до 64% и останавливается 🙁
У нас диалог точно меньше вашего, у вас около 300К сообщений, а у нас 140К всего. То есть, не очень много
Очень хотела парня обрадовать картинками со статистикой. Хотя всё запустила, дальше 64% теперь не идёт. Перезапускала, ждала полчаса — на том же месте. Я уже очень радовалась, что смогла запустить, а тут так :<
Что можно сделать?
@EomEr, программа на удивление работает, но вот вопрос, можно ли как то программу показать статистику в цифрах вместо графиков?
Привет, что об этом скажешь?
telethon.errors.rpcerrorlist.SessionPasswordNeededError: Two-steps verification is enabled and a password is required (caused by SignInRequest)
При вводе проверочного кода присылается еще один код
И да, или я тупой, или надо сделать возможность вставки в текстовые поля: вводить апи-хеш от телеги руками это больно
Такая вот штука, и как такое можно решить?)
@EomEr можно это чудо на git?
тэкс, Расстались что-ли? С 21 февраля нет ничего.
Только собрался изучить связку numpy и pandas, как на тебе — свеженькое, опенсорсное)))
Кстати, что насчет использования лемматизатора? Что-нибудь типа spaCy или textacy
Мда полная фигня от задумки до реализации + автор не хочет (не умеет?) сделать программу адекватной в плане использования. Выглядит максимум как диплом студента в какой-то украинской шараге.
Получилось очень забавно 🙂
Вот ещё занятная штука
можешь натренировать генератор и сделать автоответчик 🙂
«Она сказала слишком педантичный. И это после 267 половых актов!»

365 сообщений каждый день, о чем можно столько общаться?
Я видимо социофоб и социопат(
Охренеть. 365 сообщений в день. За 16 часов бодрствования это 22 сообщения в час. Т.е. примерно одно сообщение КАЖДЫЕ три минуты в течении суток. Это пытка какая-то, а не отношения.
Объясните мне, дремучему, а на*хуя это вот все?:)))
Пссс, может кто помочь с запуском? Интересно до жути но не умею в питон(
Слово «хочу» самое частое. Нынче такое у многих
В облаке нет ни одного матерного слова?
Ну пиздец. Как вообще так можно общаться?! (высшая степень удивления. )
Думаю, тебе стоит сделать пост на r/dataisbeautiful/.
Хочу сейчас спать
Народ, может ли кто-то запилить инструкцию для младенцев по установке всего этого?
Ты прям как Маршалл Эриксон:обожаешь графики.Он на работе нашёл отдел,который печатает для сотрудников графики(для презентаций или отчётов) и стал там заказывать графики по любому поводу.Была даже серия,где его,словно от курения отучали от графиков.Классный короче сериал (как я встретил вашу маму)

«Именно Батя завтра понял сегодня знает очень хочу сейчас спать немного»
Тов.Майор спасибо, но нет.
охуенно,ты крут ,чувак!
теперь проверю себя. Нет, не проанализировав свою переписку с парнем,а разобравшись в твоей проге,и как это замутить у себя..
она ни разу не сказала, что «соскучилась»
365 сообщений в день? Пиздец
Ты очень мало материшься, очень мало
Я вообще никакие переписки не храню. Все мессенджеры чисты
А где же виртуальный секс и ругачки?) Мои двухлетние виртуальные отношения совсем другими словами отображались бы, получается. )
знаки. они повсюду))

Судя по 2 графику ваши отношения скоро закончатся
ТС, сделай такой же график, про секс. И отдельно статистику как часто она на свидании смотрит в телефон
охренеть просто, неужели не жалко спускать свою жизнь в унитаз? в мире столько всего интересного, а ты вместо этого ежедневно бесконечно жамкаешь по экрану не получая с этого ровно ничего. 20 лет — это такой прекрасный возраст, не разменивай себя на бесполезные вещи
А полезное что-то можешь создать? Или продолжишь херней заниматься?
Первая секунда будильника в понедельник: «Хочу знаю лучше сегодня очень сейчас дома спать долго хорошо»
Сколько вам лет?
Судя по графикам, у меня для тебя плохие новости: или вы что-то поменяете вместе, или что-то поменяет один из вас.
бля, как же с девушками нелегко. с пингвинами на компах проще.

Разработчики на ретроспективе, когда нужно отвечать на вопрос «А что пошло не так?»

Как научиться программированию? 4 ключевых ошибки
Давно назревала мысль написать такой пост, но тут почитал последние посты под тегом «Программирование», и понял, что время пришло. Так что оторву вас на 5 минут от Степиков и прочих Ютьюбов, а взамен сэкономлю несколько месяцев, которые могли быть потрачены на неправильное обучение.
В общем, встречайте: статья для всех, кто уже давно сидит на Stepik, пересмотрел сотни видео на YouTube, перечитал много книг, но до сих пор не научился программировать.

Ошибка №1: изучать язык вместо того, чтобы учиться программировать
Вот ситуация, которую я постоянно вижу у новичков на код-ревью: студент прошёл несколько курсов на Stepik, Udemy или Coursera, иногда даже документацию на docs.python.org успел почитать. Он легко может перечислить параметры любой встроенной функции или перечень зарезервированных слов в алфавитном порядке. Но при этом простейшая задачка на 50-60 строк кода вгоняет его в ступор, на решение уходит несколько часов, а получившийся код выглядит как жуткое месиво из прошлогоднего салата и человеческих останков.
Алгоритма нет, задача решалась на ходу и в процессе переписывалась 5 раз. Функции и переменные названы как попало, да и остальные правила написания чистого кода тоже соблюдались весьма условно. Зато синтаксис языка изучен на 100 из 100 баллов. Вот только пользы это не принесло.
А как правильно?
Пишите больше кода. Составляйте алгоритмы. Думайте над задачами. Соотношение «практика / теория» должно быть 5-к-1 или ещё больше. Недостающую теорию вы всегда можете загуглить, но если вы сфокусируетесь на изучении мельчайших деталей языка, а не на написании кода, то не научитесь никогда.
Ошибка №2: искать лёгкие пути и избегать трудных заданий
«Ой, эта задача сложная, её пока пока что пропущу, решу что-нибудь полегче. Такой проект я пока не потяну, лучше напишу что-нибудь попроще». Делаете так? Тогда поздравляю, вы попали во вторую по популярности ловушку для новичков.
Представьте себе бегуна, который хочет побеждать в соревнованиях, но на тренировках никогда не разгоняется до максимальной скорости, а иногда вообще ограничивается лишь разминкой, и потом с чувством выполненного долга идёт домой. Он никогда не потеет и не устаёт, круто! Вот только настоящим бегуном так никогда и не станет, и в соревнованиях никогда не победит — ни спустя год, ни спустя 10 лет.
То же самое и в программировании. Можно решить 50 несложных задач, а можно и 5 000. Но в обоих случаях вы столкнётесь с одинаковыми трудностями, когда перейдёте к более серьёзным задачам. Только времени во второй ситуации потратите в 100 раз больше.
А как правильно?
Постоянно бросайте себе вызовы и пробуйте решать более сложные задачи. Не получилось — отложите задачу на день-два и затем снова попробуйте её решить. Повторяйте до тех пор, пока не получится, а потом снова повышайте планку.
Для того, чтобы закрепиться на определённом уровне, не нужно решать сотни однотипных задач. Пары десятков более чем достаточно, а потом нужно двигаться дальше.
Ошибка №3: изучать всё, что попадётся под руку
Сегодня изучаем Python, потому что на нём пишется красивый код, а ещё он используется в Google. Завтра Javascript, потому что на нём можно написать и бэк, и фронт. Послезавтра Go, потому что он перспективный и современный. Потом возвращаемся к Python и 2 месяца пытаемся изучить Django, а в итоге понимаем, что без хорошего знания Python и хотя бы базового знания SQL Django в голову вообще не ложится. Знакомая картина?
На самом деле, так вполне можно научиться программировать. Проблема лишь в том, что на это уйдёт в несколько раз больше времени и сил, чем при правильном подходе.
А как правильно?
Подготовьте чёткий план обучения. Естественно, знаний для того, чтобы составить его с нуля, у вас пока что не хватит, поэтому воспользуйтесь готовым или просто запишитесь в хорошую школу программирования, где всё это уже сделано и весь необходимый материал уже подготовлен. В нашу, например 🙂
После того, как план составлен, не отклоняйтесь от него. Даже если в процессе обучения вы внезапно узнали про новый суперкрутой и ультраперспективный язык, оставьте его в покое и продолжайте уверенно двигаться по ранее намеченному пути.
Ошибка №4: рассчитывать на то, что за 6-7 месяцев вы станете Middle-разработчиком
Я испытываю странную смесь уважения и негодования к маркетологам кое-каких онлайн-школ за то, что они сумели внушить людям такую мысль. Дар убеждения у них определённо есть. К сожалению, в обещании обучить с 0 до middle за полгода правды не больше, чем в обещании стабильно выплачивать проценты вкладчикам МММ.
Прежде всего, грейд «middle» подразумевает, что разработчик уже имеет опыт работы на реальном проекте. Причём этот опыт, как правило, должен быть не менее тех самых 6-7 месяцев, а скорее даже не менее 1 года. То есть мидлом без реального опыта стать нельзя по определению.
Более того, в современном мире даже к Junior-разработчикам предъявляются такие требования, что на обучение стоит закладывать около 700-900 часов, то есть примерно 1 год. Это при условии, что вы идёте по чётко намеченной программе, не тратите время на поиск материалов, и у вас есть ментор, который вовремя вернёт вас на нужные рельсы, если вы с них сойдёте.
Если же вы учитесь полностью самостоятельно, перебираете разные материалы в поисках качественного и не получаете обратной связи от более опытных разработчиков, то смело поднимайте планку до 1500 часов.
А как правильно?
Настраивайте себя на то, что учиться придётся долго. Более того, учиться придётся даже после того, как устроитесь на работу, потому что отрасль IT очень быстро развивается и изменяется. Если не готовы к долгому марафону, то не надейтесь на чудо и не тратьте своё время.
2. Не избегайте сложных задач, а стремитесь к ним;
3. Двигайтесь по намеченному пути, без метаний из стороны в сторону;
4. Готовьтесь к тому, что учиться придётся долго.
Статья получилась немного пессимистичной, как будто программирование — это сплошная боль и печаль. На самом деле всё далеко не так плохо 🙂 Программирование — это очень интересно. Оно развивает мозг, дарит радость от решения сложных задач и позволяет приносить пользу другим людям. Так что если вам нравится программировать — следуйте этим несложным советам, и всё получится. Удачи!
Интересный Python #14: визуализируем данные
Сегодня напишем вот такое приложение всего в 53 строки кода. Да, всего 53, без шуток. И всё благодаря Streamlit.

Что такое Streamlit?
Streamlit — это библиотека, которая позволяет создавать веб-интерфейс для приложений, работающих с данными. Так что если вы работаете с Pandas, используете Matplotlib, Bokeh, Altair и подобные инструменты, то с помощью Streamlit сможете оборачивать свои скрипты в интерактивные веб-интерфейсы и делиться ими с другими пользователями.
Для кого этот пост?
Для тех, кто уже неплохо знаком с Python и часто работает с данными. Для начинающих многие вещи будут сложноватыми.
Как установить Streamlit
1. Откройте терминал (командную строку);
2. Если умеете пользоваться виртуальным окружением, то создайте и активируйте его. Если нет, то пропустите этот шаг;
3. Выполните команду pip install streamlit.
Документация
Документация просто великолепная, очень удобная и красивая. Ознакомиться с ней можно здесь.
Для начала соберём интерфейс приложения. Он будет состоять из:
— формы (контейнера для других элементов);
— пары полей для ввода чисел;
Для каждого из этих элементов в Streamlit есть отдельный класс.
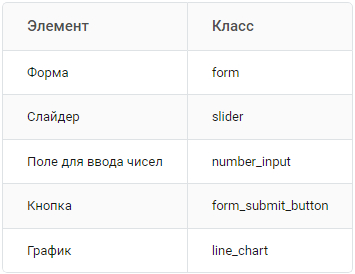
Форма нужна для того, чтобы скрипт не перезапускался полностью при каждом изменении слайдера или поля для ввода (по умолчанию в Streamlit реализовано именно такое поведение).
Задаём настройки страницы, добавляем заголовок «Симулятор ставок» и создаём форму с элементами.
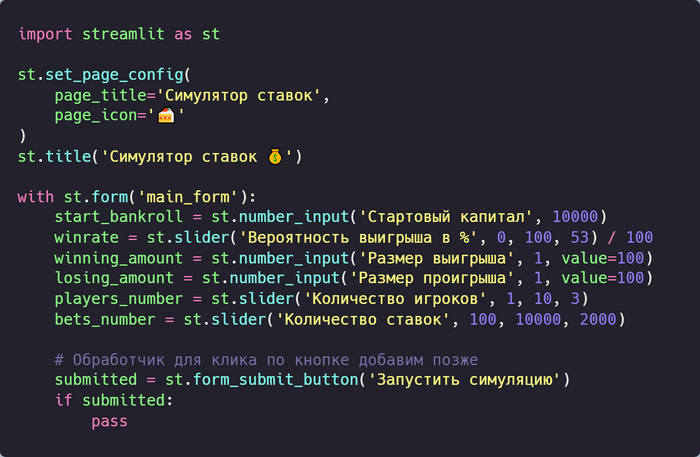
Запускаем сервер
Чтобы запустить сервер Streamlit, выполните в терминале следующую команду:
Вместо main.py , конечно же, укажите имя вашего основного модуля.
Если всё сделано правильно, то спустя несколько секунд откроется окно браузера, в котором отрисуется интерфейс.
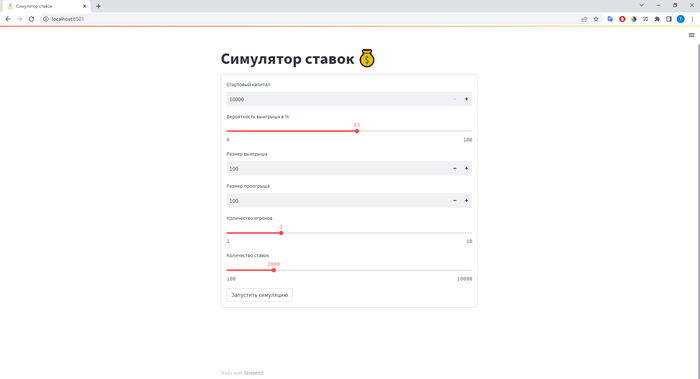
Важно: запускать программу с помощью интерпретатора Python не нужно, сервер Streamlit сам это сделает. Если вы внесёте изменения в исходный код, то достаточно будет просто обновить страницу, чтобы изменения вступили в силу.
Теперь реализуем внутреннюю логику. Нужно будет при каждом нажатии на кнопку в форме генерировать датафрейм с результатами ставок.
Начнём с импорта нужных модулей.

Так как нужно будет генерировать N наборов данных, построенных по одинаковому принципу, то упакуем начальные «настройки» в класс, и будем использовать их при вызове методов.
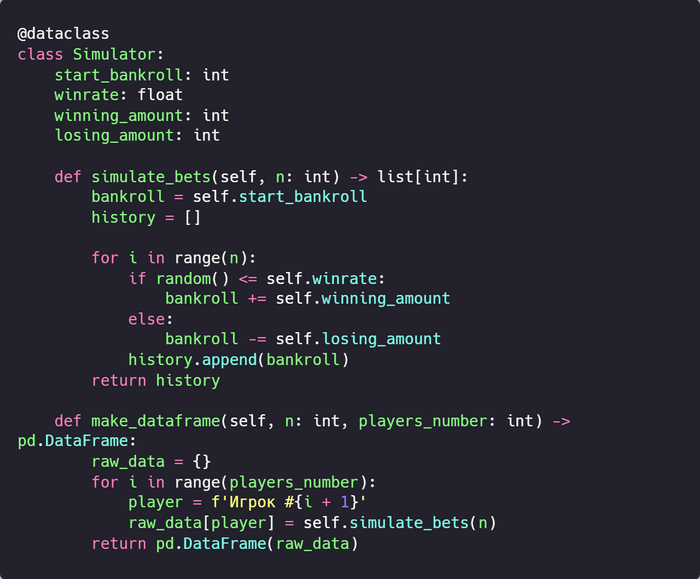
Соединяем интерфейс и логику
Осталось сделать так, чтобы при клике по кнопке приложение забирало данные из элементов интерфейса и отдавало их в Simulator.

Приложение готово. Обновите страницу в браузере, и Streamlit автоматически подтянет все изменения.
Streamlit щедро раздаёт свои облачные ресурсы, так что развернуть приложение можно буквально в пару команд. Пушим код на Github, даём Streamlit ссылку на репозиторий, немного ждём и получаем ссылку на наше приложение в облаке. Подробности — в документации.
Игры на Python3 (TMNT TF)
Частенько я пишу простые игры, для усвоения азов языка, в частности вникнуть в ООП. У меня есть несколько недоделанных проектов типа танчиков и тамагочи. Бросаю их на полпути, но сейчас не об этом. Ради интереса решил начать новый проект (не закончив старые, ага)). Сделать простенький файтинг графика из NES черепашек. Мне интересно воспроизводить игры со старых приставок. Так вот, чтобы не забрасывать и мотивировать себя, буду, может, тут отчитываться. Сейчас мало что готово, есть два персонажа, отсчет времени и жизни. Драться пока не умеют, точнее умеют, но без урона.

Подборка ресурсов для личной анонимности и безопасности в сети
Анонимность и безопасность:
checkshorturl.com — Дешифратор коротких URL-ссылок для проверки на фишинговый сайт
proxy6.net/privacy — Проверка анонимности web-серфинга
browsercheck.qualys.com — Проверка браузера на безопасность (security bugs, malware addons, etc)
www.cpcheckme.com/checkme — Экспресс-онлайн проверка безопасности вашего десктопа от фишинга, уязвимостей ПО, утечки sensitive data
www.hackerwatch.org/probe — Проверка хостовой IDSIPS и end-point Firewall
Список полезных сайтов:
https://fakedetail.com/ — генератор фейк переписок, личностей, медиа и т.д.
https://www.photopea.com/ — онлайн photoshop ( не хуже настольной версии)
https://pory.io/ — если нужно создать приятный, простенький сайт, но лень писать код.
https://www.google.ru/alerts — устанавливаем трекер на любой поисковой запрос.
Reflect ( https://reflect.tech/ ) — заменит любое лицо на фотографии.
Teachable Machine ( https://teachablemachine.withgoogle.com/)- обучить нейросеть! Google сформировала приложение, которое поможет людям понять, как функционируют нейросети.
Talk to Books ( https://books.google.com/talktobooks/)- поговорить с нейросетью с помощью книг.
This Person Does Not Exist ( https://thispersondoesnotexist.com/ ) — сгенерирует несуществующего человека.
больше интересного и полезно в нашем ТГ
Задача по Python #3: палиндром
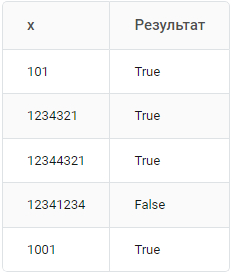
Сможете определить, является ли число палиндромом, не превращая его в строку?

Создайте функцию, которая будет принимать число и определять, является ли оно палиндромом, то есть симметрично ли оно относительно своей середины.
Функция должна вернуть либо True, либо False.
Важно: не используйте списки и строки. Пробежаться по набору символов с двух сторон — это слишком легко. Попробуйте решить задачу, оперируя лишь числовыми данными.
Скидывайте решения в комментарии, посмотрим, у кого получится лучше всех) Аккуратно оформить код можно здесь: https://carbon.now.sh/
Чтобы вам было комфортнее решать задачи, я подготовил набор тестов. Вот тут можно написать код онлайн, тут же проверить, проходит ли он тесты, а потом получить обратную связь от наших код-ревьюеров.
Войти в IT за 365 дней. Дни #14-20
3 начинающих программиста изучают Python и ведут видеодневники. Предыдущие выпуски можно найти в профиле.
Краткий срез по состоянию на 7-15 августа: с функциями полностью разобрались и перешли к изучению коллекций. Пока что все трое обучающихся идут по плану, без внезапных происшествий. Только вот Денис немного приболел, так что свой выпуск видеодневника он записал чуть позже остальных.
Скоро будет первая важная точка: в конце темы «Коллекции» каждому обучающемуся предстоит написать первый более-менее полноценный проект на произвольную тему. Это будет самой интересной частью первого месяца, так что посмотрим, что у них получится)
А пока что выкладываю промежуточные результаты. Как обычно, там всё сложно: код никак не хочет нормально писаться с первого раза, а ревьюеры заставляют много думать и выбрасывать из кода всё лишнее. Ролики будут особенно полезными тем новичкам, кто до сих пор искренне верит, что сейчас они пару месяцев посидят на Степике, а потом их возьмут на работу с ЗП 200к. Нет, друзья, всё будет куда сложнее)
Андрей получает достижение «Мастер костылей» и учится работать со словарями внутри словарей внутри словарей.
Юрий достаточно быстро продвигается по теме «Коллекции», но по-прежнему испытывает сложности с некоторыми практическими заданиями, в особенности с алгоритмами для них. Тем не менее, прогресс по сравнению с началом обучения уже есть.
Денис: «Когда я впервые увидел это задание, то просто закрыл replit и пошёл отдыхать. В итоге я переделывал его раза 4».

Подборка IT-обучающих каналов на ютубе
На пикабу периодически всплывают посты о том, как кто-то вкатился в программирование в 30/40/50 лет и ни о чём не жалеет, дают советы как не забросить идею итд. Я же хочу поделиться мини-подборкой каналов на ютубе, которые дают либо хорошую базу для начала обучения программированию, либо рассказывают о том, как быстрее и удобнее писать код.
Начать хочется с, по моему мнению, самородка русского IT ютуба — Alek OS.
Парень в приятной манере рассказывает об алгоритмах, основах программирования, приводит примеры на псевдокоде, сопровождает все разъяснения красивой графикой. Он не учит какому-то конкретному языку, но даёт базу, которая позволит писать лаконичный код на любом языке.
Далее канал посвящённый Python — ZProger.
Акулам питона и людям с опытом в других языках его контент вряд ли будет интересен, но новичкам очень его советую. Рассказывает об инструментах и возможностях языка, о которых мало пишут в статьях для новичков и курсах, посвящённых python.
Разговорный канал разработчика со стажем — Лёша Корепанов.
Тут нет лекций о программировании, вас не научат писать супер оптимизированный код, работающий на утюге, но зато автор очень хорошо рассказывает о своей истории, о том как бороться с выгоранием, как найти себя в разработке, и что, как мне кажется, самое важное — как подать себя на рынке труда.
Последний канал в подборке включаю только для тех, кому интересны новости из мира IT и их интересная подача — Pingvinus.
Просто подборки новостей, обзоры дистрибутивов Linux, истории разных open-source компаний и подобное.
Подборка из комментариев:
Vectozavr — Снимает видео про геймдев (предложил @aquah)
Владилен Минин — React, JS, Angular, SPA и вот это вот всё) (предложил @Assshooole)
Тимофей Хирьянов — Лекции по алгоритмам, C++, Python и вот это вот все (предложил @Archikoff999)
RuFrame — Видео про написание консольных скриптов на cmd и powershell (предложил @sovietsova)
Олег Молчанов — Обучающие ролики по python и разработке на Django (предложил @ChYuriy)
Artsiom Rusau QA Life — Всё про QA и тестирование приложений (предложил @FoxGarrison)
Sergei Calabonga — Обучение разработки на .NET (преложил @DarkTolyan)
Интересный Python #13: играем "Имперский марш"
В прошлых постах было слишком много слов «работаем». Поэтому сегодняшний пост будет про то, как играть. Причём играть не что-то там, а музыку. Причём музыку не какую-то там, а «Имперский марш» из «Звёздных войн». Так что, товарищи Дарты Вейдеры, отвлекитесь на пару минут от удушения очередного офицера и насладитесь чудесными звуками.

Для воспроизведения звуков будем использовать модуль winsound из стандартной библиотеки Python. Устанавливать ничего не нужно, он уже идёт в комплекте с интерпретатором.
В нём есть функция Beep(), с помощью которой можно воспроизвести звук заданной частоты и заданной длительности.
Важно: модуль работает только под Windows. Господа линуксоиды, сегодня вы в пролёте 🙁

Также понадобится модуль time, с помощью которого будем создавать паузы.

Каждой ноте соответствует определённая частота звука, выраженная в герцах. Таблицу можно увидеть здесь или здесь.
Составим список необходимых нот:
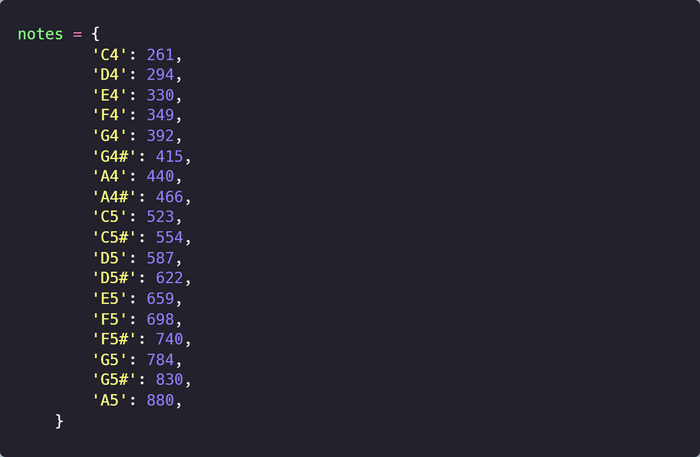
Ключ — это название ноты, а значение — это частота.
Запишем мелодию в виде набора нот.

1/4, 3/16 и прочее — это длительность каждой ноты.

Нам понадобятся 2 функции: одна для воспроизведения конкретной ноты, а вторая — для воспроизведения всей мелодии.
Воспроизводим ноту
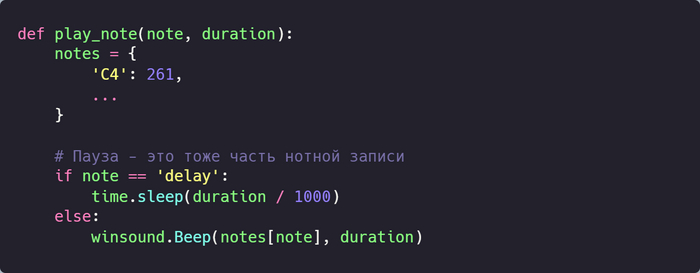
Воспроизводим мелодию

Наслаждаемся результатами
Оригинальный темп мелодии — 103 BPM.

Забрать полный код в текстовом виде можно здесь.
Ответ charmag в «График работы и последствия»
После окончания универа, тоже думала, вот поработаю пару лет «на дядю» (в мое случае правда тётя была) наберусь опыта в разработке и сопровождении и тоже на фриланс уйду, сама на себя работать буду. Поработала, заработала нервный срыв, ненависть к пользователям, полное отвращение к профессии программиста.
Вообще, в этой профессии разочаровалась. Так как представления о данной работе были совсем иные, не спорю, может быть у тех, кто работает в разработке, да ещё в иностранных компаниях или хотя бы в Мск, всё ништяк. Однако меня жизнь завела в сопровождение и поддержку/доработку 1С т.е. разработка есть, но на минималках. И при этом всём регулярно общаешься с пользователями, решая их проблемы. И по большому счету, вся работа превращается в сплошное решение чьих-то проблем. Там не формируется, тут не выгружается, здесь был Вася, а вот там ошибка. И у всех сраки горят. Сделайте мне большую красную кнопку «Работать» и что б оно всё работало за меня, ТЗ я не дам, сами придумайте, че Вы не программисты што ле? И т.д. просто ааааааа убивать хотелось.
Собиралась идти трусами торговать, а не вот это вот всё. Но в итоге устроилась в другую адекватную компанию. И поняла одну простую вещь, да нахрен мне этот фриланс сдался. Я тут стабильненько с 9.00 до 18.00 поработаю, после 18.00 рабочий телефон в отключу, почту закрываю, и всё никто меня не дергает. Свой оклад я точно получу, хорошо поработаю ещё и премию тоже. И мне не нужно искать заказчиков, общаться с ними на прямую, работать по ненормированному графику, откладывая в сторону свою жизнь и свою семью. Переживать будут ли заказы, всё ли мне оплатят и т.д.
В общем, лично для меня работа в нормальной компании, куда комфортнее фриланса. Потому что на фрилансе я бы получила, тоже самое, что и на первом месте работы. И когда читаешь про то, что кто-то на фрилансе по 30 часов подряд работает, по запарке ест из собачей миски и т.д. Лично мне не понятно, а оно того стоит вообще? Даже если Вы при этом зарабатываете куда больше, если б работали в компании, свободное время на деньги не купишь.

Пульс "Лучшего", статистика и статистические заблуждения. Часть 2.
В комментариях к предыдущей части мне советовали вывести распределение количества постов по рейтингу в логарифмическом масштабе. Собственно, вот, обратите внимание на ось Y:
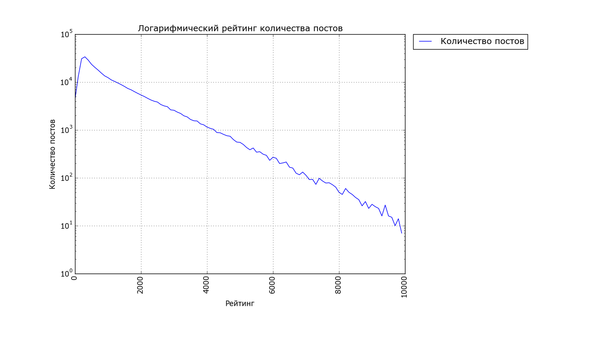
График хорошо согласуется с предложенной моделью, и с графиком в исследовании @ponyuh. Мы видим, что количество постов с заданным рейтингом не просто убывает с увеличением этого рейтинга, а убывает экспоненциально.
Теперь, посмотрим на временной анализ количества постов с определёнными тегами на Пикабу. Для этого я снова выделил теги, которые встречаются хотя бы 200 раз и подсчитал, сколько постов с этими тегами было в каждый день. Для удобства вывода и сравнения полученные значения были отнормированы: массивы значений для каждого тега были поделены на сумму значений по массиву. Таким образом, график для тега тем выше, чем более неоднородно распределение постов с данным тегом (и не зависит от количества постов с ним). Графики дополнительно немного сглажены для лучшей читабельности узких пиков, и чтобы низкоуровневый шум не портил низ изображения.
Для начала проверка здравого смысла: теги, связанные с праздниками и временами года:
Мобильная версия (большой текст):
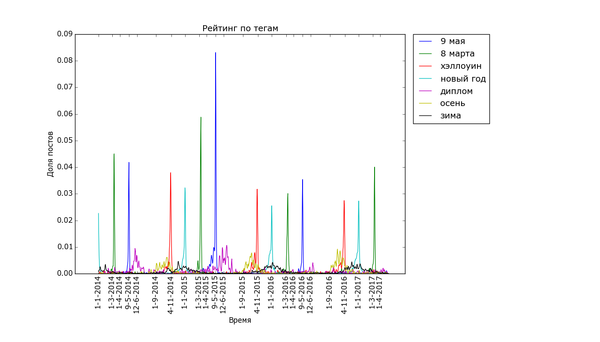
Широкоформатная версия (мелкие детали, откройте в полном окне):
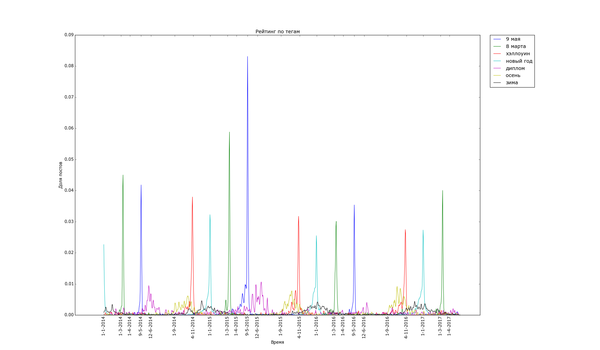
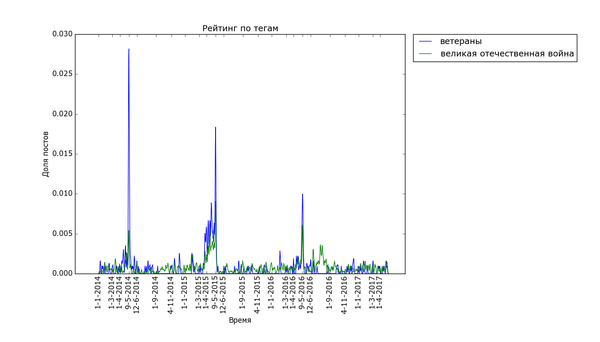
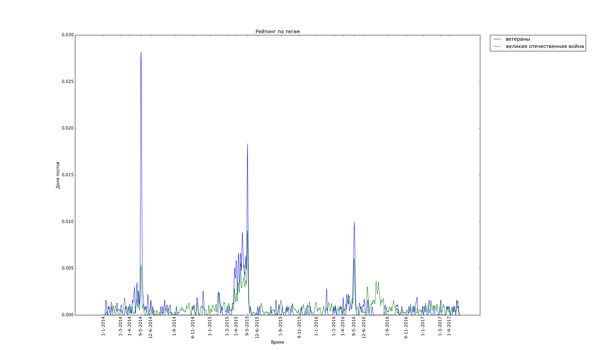
Внизу стабильно плещутся волнами «осень», «зима» и «диплом», распределение постов с ними размазано по соответствующим месяцам. Зато явно видно как примерно за месяц начинают набирать обороты, а затем резко взмывают вверх перед определёнными датами «праздничные» теги. Больше всего выделяется «9 мая» — это график с самым большим перепадом из всех, видимо, сказалось, что в 2015 году было 70 лет победы в Великой Отечественной. Но вообще, хоть постов про девятое мая больше всего, хм, около девятого мая, не сказать, что Пикабу помнит про ветеранов только весной. Графики уверяют, что посты про ветеранов и Великую Отечественную войну иногда достигают «Лучшего» в течение всего года.
Примерно так же выглядят графики для тегов «Леонардо ди Каприо» и «Оскар»:
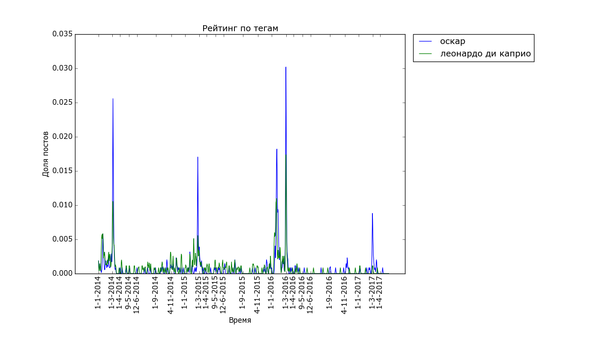
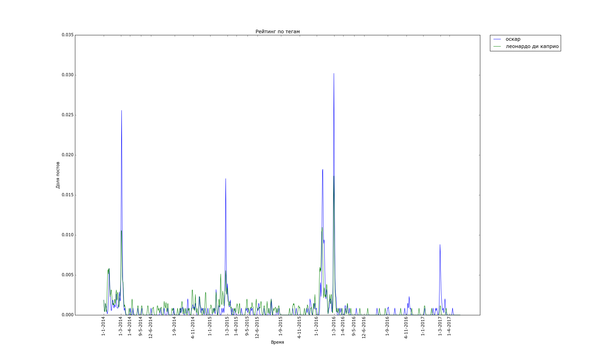
Бедный ди Каприо, после того как ему таки дали злосчастный Оскар, про него совсем перестали вспоминать =(
Пикабу очень не против поделиться своим мнением о политике:
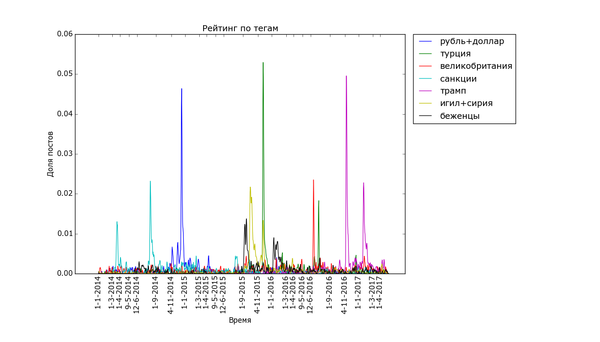
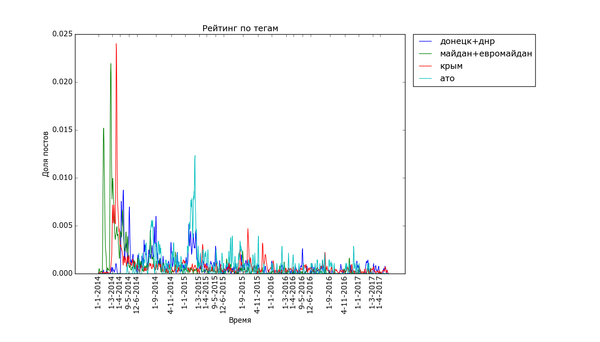
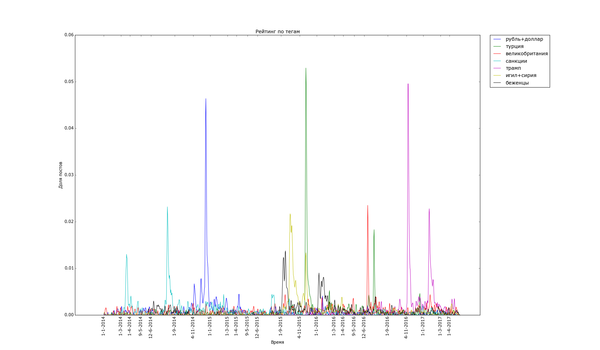
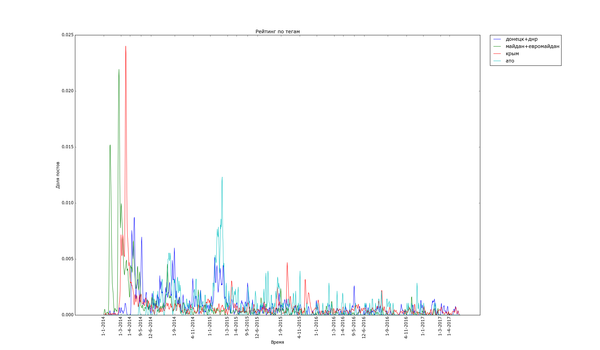
Часто шумиха стихает в течение месяца («Трамп», «Турция», «Великобритания» (в контексте Brexit), «санкции»), иногда двух («беженцы», «Сирия»). Украинские теги держатся дольше, но меняют акцент со временем. Впрочем, и они потихоньку сходят на нет.
Графики соответствующие волнам историй на определённую тематику ещё уже. К тому же не все из них так явно выражены. Волна тега «трамвай» всего в пять раз выше уровня шума (частоты появления постов с тегом «трамвай» в остальное время):
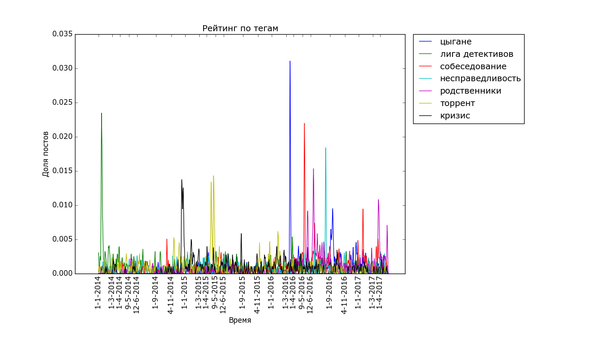

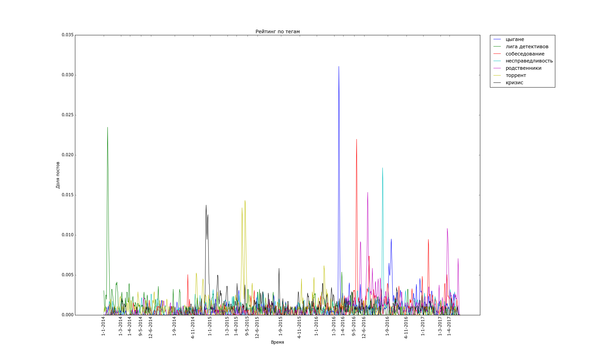
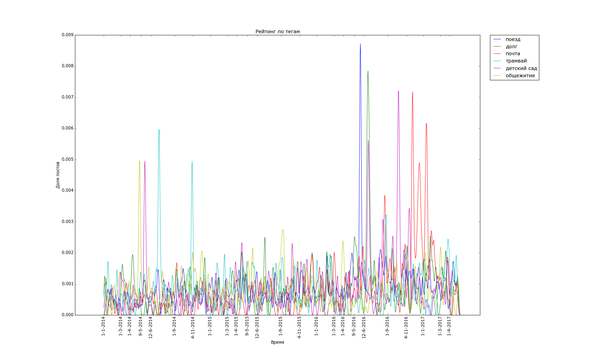
Накладывание графиков друг на друга позволяет сказать, что волны историй не соседствуют друг с другом. Единственное исключение — теги «долг» и «детский сад», возникшие из шума одновременно летом 2016. (Возможно, есть какие-то малые волны, которые соседствуют с большими, но не попали на график).
Графики, соответствующие событиям в гик-культуре, бывают как острыми, так и размазанными по времени:
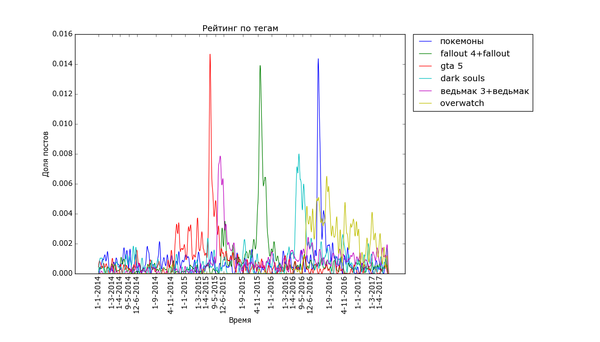
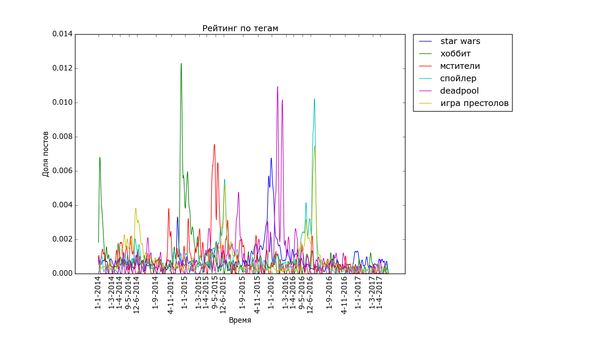
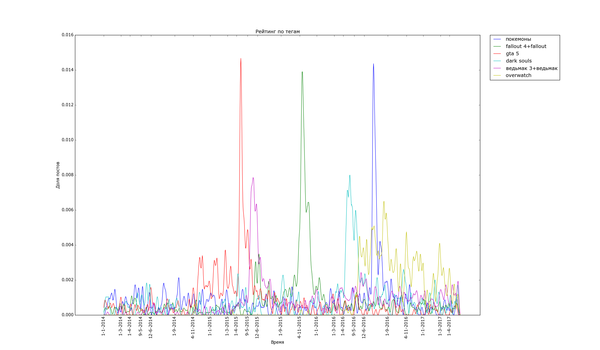
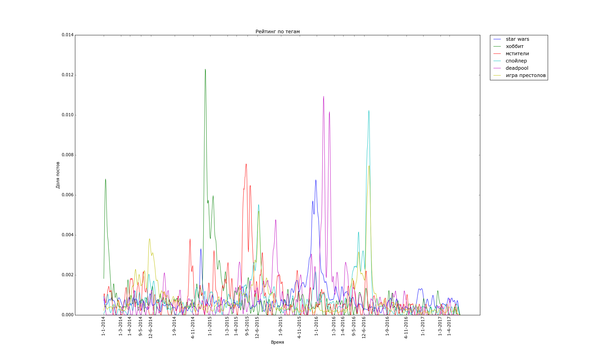
Особенно поразителен узкий вжух «покемонов». Помните, такая игра была, а? За рубежом её так долго ждали. «Overwatch», напротив, демонстрирует поразительную стабильность. «Star Wars» и «Мстители» демонстрируют как сравнительно медленный подъём, так и затухание. Также обратите внимание на интересную форму — двойной пик — некоторых графиков. Особенно сильно это заметно с «Дэдпулом» и «Хоббитом». По всей видимости, это соответствует двум датам выхода фильмов — в России и за рубежом. Также это может быть связано с тем, что первая волна зрителей/игроков своими положительными отзывами создаёт вторую волну.
3) Если вы почему либо хотите «попасть в волну», то следует правильно рассчитывать «мощность» горячего тега.
Волны кулстори на определённую тематику на Пикабу имеют наименьших срок жизни (порядка 15 дней). Сиюминутные политические и общественные события немногим лучше (около месяца). Более продолжительные события или новые однопользовательские игры (не мобильные с дополненной реальностью) могут протянуть несколько месяцев. Больше всего живут раскрученные франшизы и мультиплеерные игры.
4) Не стоит форсить свою линейку историй, если Пикабу уже увлечён чем-то другим. Лучше подождать недолго, пока шумиха утихнет.
5) Иногда получение Оскара может повредить вашей популярности.
Извини, Пикабу. Что-то я не рассчитал длину поста и своё время. Пост с общим временным анализом по дням недели и рассказом про некорректное использование статистики будет завтра или чуть позже. Но если вдруг кому интересно, выложу ссылку на программу и данные сегодня, как и обещал.
Исходный код. Для работы нужен Python 3.4 с установленными numpy и matplotlib; для работы обходчика веб-страниц нужен ещё и scrapy. Чтобы скачать сырые данные, настройте и запустите scraper.py (лучше на ночь). После этого в корне проекта появится data.pkl. Для анализа и вывода данных — main.py.
Чтобы не скачивать все данные с Пикабу и не вычислять всё с нуля, скачайте кэш-файлы и разархивируйте их рядом с main.py. Осторожно, в функциях проекта используется очень наивная реализация кэша. Если бы будете запускать функции с соответствующей аннотацией, не забудьте вручную удалить соответствующий файл кэша.
Архив со всеми графиками, в том числе и теми, что будут в следующем посту.
Если у вас есть предложения, график или статистику чего вы бы хотели увидеть, пишите в комментариях.
Пульс "Лучшего", статистика и статистические заблуждения. Часть 1.
Я программист, и моё хобби — статистика, анализ данных и машинное обучение. Чтобы отвлечься от пережёвывания однообразных банковских и социальных данных, пару недель назад я расковырял данные Пикабу о лучших постах. Я хотел бы поделиться с вами результатами этого небольшого исследования и разобрать на его примере один типичный случай неправильного применения статистики. Попробуйте обнаружить её в ходе повествования.
Сначала немного о способе получения информации. К сожалению, доступ к полной статистике посещения, кликов и размещения постов имеет разве что админ, и вряд ли со мной поделится. Поэтому пришлось довольствоваться тем, что есть, а именно кодом страниц Пикабу. Его можно увидеть в браузере, нажав правой кнопкой мыши на страницу и выбрав «Просмотреть код» или посмотрев, что приходит в ответ на запрос страницы (F12 в Chrome). Эту длинную HTML-простыню несложно распилить на сегменты, отвечающие за каждый пост, а из них, в свою очередь, наковырять чего-нибудь интересного. Разумеется, сохранять все данные вручную, было бы невероятной тратой сил, поэтому я написал бота, обходящего «Лучшее». К счастью, адрес страниц Пикабу имеет простой формат «http://pikabu.ru/best/XX-XX-XXXX?page=YY».

Выкачивать всю информацию, включающую в себя многомегабайтные картинки, было бы грустно для свободного места на моём компьютере, поэтому пока что я остановился только на базовых данных: названии поста, тегах, рейтинге, количестве комментариев и дате отправки. Также я решил, что абсолютно все посты меня не интересуют, поэтому ограничился лишь 15 страницами «Лучшего» каждого дня начиная с 1 января 2014 года по 1 апреля 2017. Вышло 361604 записи.
Даже из этих простеньких данных можно состряпать что-нибудь интересное. Для начала давайте просто посмотрим на количество постов с различным рейтингом. По вертикали отложен рейтинг, толщина жёлтой области по горизонтали — количество постов с данным рейтингом, жирные красные точки — единичные посты с высоким рейтингом.
Мобильная версия с читабельным текстом:
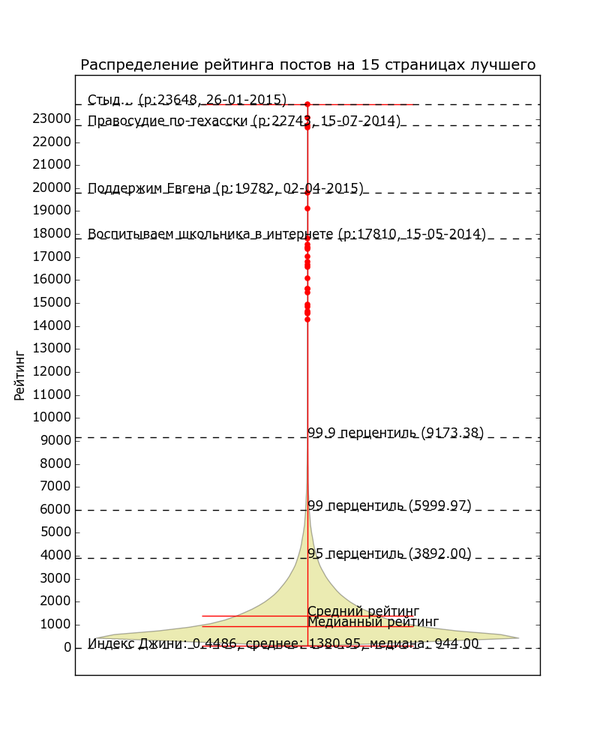
Версия с высоким разрешением и большим количеством информации (откройте в полное окно во избежание шакалов):
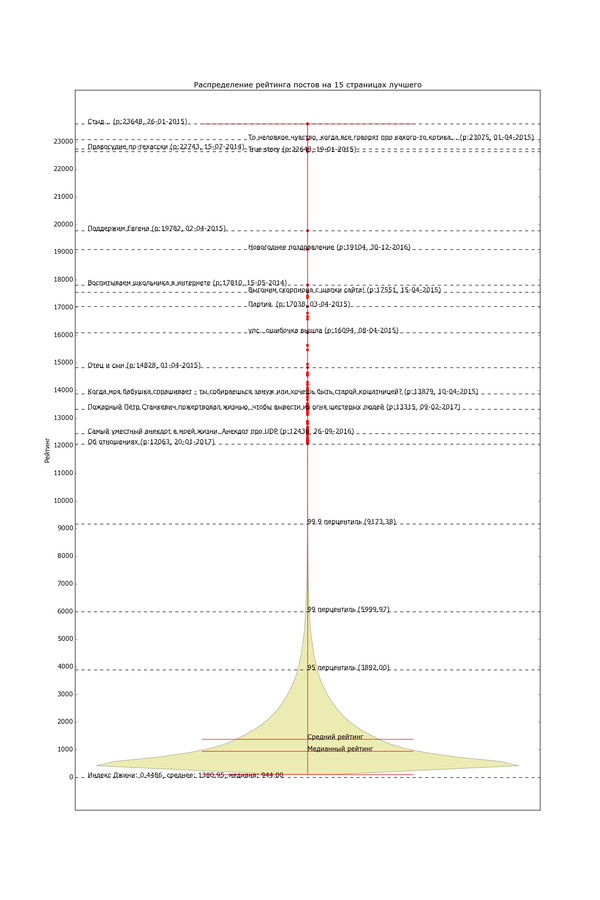
Невооружённым глазом видно, как график очень быстро сужается. Распределение рейтинга по постам довольно неравномерно. Половина постов в «Лучшем» имеет рейтинг в диапазоне от 0 до 944 (жирный кусок «юлы»). Если сложить весь рейтинг и поделить поровну, получится 1380 рейтинга на пост. Только 5% постов в лучшем имеют рейтинг выше 3892 (95 перцентиль) и лишь 1% — выше 6000. Хоть график тянется довольно высоко, его высокие уровни почти не населены. В верхней половине графика находятся 80 постов «элиты» с рейтингом выше 12 тысяч (красные точки); остальная 361 тысяча — в нижней половине. Вот такое вот неравенство.
Проанализировав данные при помощи стандартной метрики неравенства, индекса Джини, я получил значение в
0.45. 0 означало бы абсолютно одинаковое распределение рейтинга, 1 — абсолютное неравенство. Для сравнения стоит заметить, что неравенство распределения доходов россиян по индексу Джини оценивается в
0.41, американцев в
0.43, французов в
0.31, а чилийцев — в
Вообще такой график соответствует часто встречающемуся в различных системах закону «богатые становятся богаче». На Пикабу такое поведение связано с тем, что разные читатели просматривают разное количество страниц. Лишь небольшая их доля отлавливает посты в свежем. Только если посту повезло, и рыцари свежего одарили его плюсам, он «получает доступ» к более широкой аудитории людей, пролистывающих «Горячее» до конца. Если и там он поднялся, то свою порцию плюсов накидывают обитатели первых страниц «Лучшего» и «Горячего», а затем и просто люди заходящие только на первую страницу «Лучшего». Разумеется публика не столь стратифицирована, кто-то, кто обычно сидит в свежем, может сегодня только посмотреть пару страниц «Горячего», а кто-то, сидящий в «Горячем», может вовсе не зайти на Пикабу. Тем не менее, «подъём» поста — многоступенчатый и самоподдерживающийся процесс с положительной обратной связью (чем популярнее пост, тем он станет ещё популярнее в будущем). Качество контента играет роль, но если на каком-то этапе из-за случайных флуктуаций иссякает «топливо», то увы. Хотя вообще и пост может оказаться неоч для «Лучшего», это да.
Что самое интересное, «топ топа» не особо отличается от случайных постов в лучшем. То есть, они довольно хорошие, без треша, но за исключением нескольких постов от 0x00, вряд ли бы я бы опознал их на общем фоне:
Наверное, это можно интерпретировать так: шанс попасть на самый верх есть у каждого, но его можно здорово повысить умением создавать длинные гифки-мультики.
Теперь посмотрим на распределение рейтинга по тегам. Для полученных данных я подсчитал, сколько раз используется каждый тег. Для тегов, встречающихся более чем в 200 постах, вычислил средний рейтинг постов с этим тегом. В итоге:
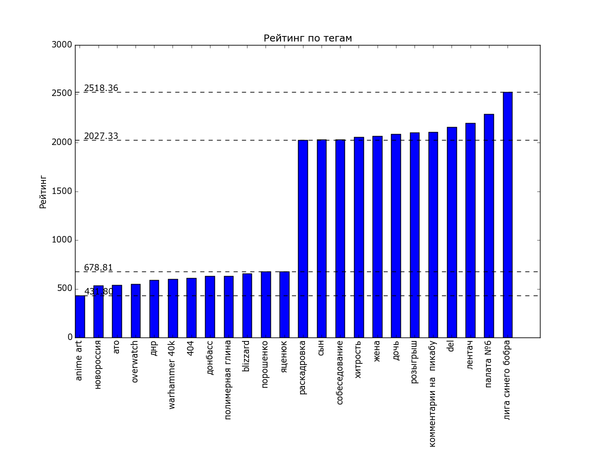
Ииии в самом топе по рейтингу. с уверенным отрывом. «лига синего бобра». Хах. Кто бы мог подумать. Я один не замечал этот тег раньше? Второе и третье место занимают «палата №6» и «лентач». Вообще состав тегов правой половины графика намекает на то, что на Пикабу ценятся кулстори из личной жизни («сын», «отец», «дочь», «жена»), с работы («клиенты», «собеседование», «начальник») и из понятной всем повседневной жизни («почта России», «очередь», «яжмать», «азиаты» (?)). Не стесняется Пикабу таскать контент с bash im и заниматься самолюбованием («комментарии на Пикабу»).
На донышке находится политота — туда ей и дорога! — аниме, некоторые игры и хобби. Рискну предположить, что политика просто всех так достала, что большинство её уже просто пролистывает или помещает тег в игнор. Остальное — просто слишком специализированное, так что если и выходит в «Лучшее», то далеко не уходит просто за счёт того, что на Пикабу слишком мало людей, которым был бы интересен, скажем, рисунок карандашом.
Прошлый анализ никак не учитывал, что пост может быть одновременно отмечен несколькими тегами, входящими в перечень (скажем, и «blizzard», и «собеседование»). Скажем, если аудитория не любит «тег 1» и любит «тег 2», при этом «тег 2» почти всегда встречается с «тегом 1» и постов с «тегом 1» гораздо больше, то это может привести к «занижению ценности» «тега 2». Чтобы оценить степень проблемы, посмотрим на матрицу корреляции самых популярных тегов:
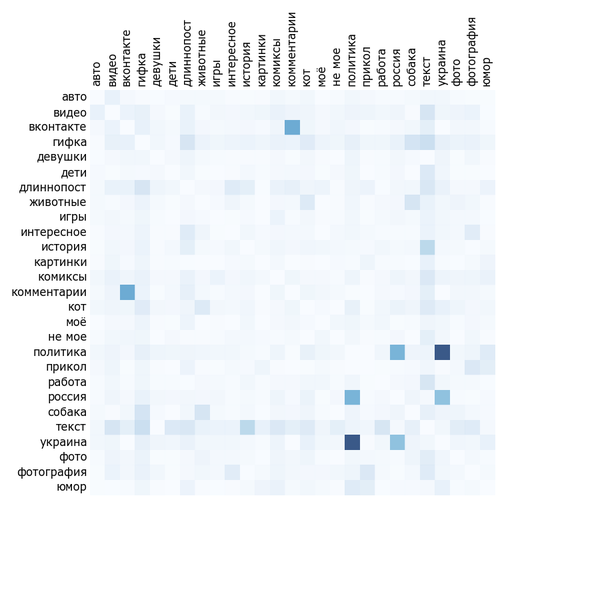
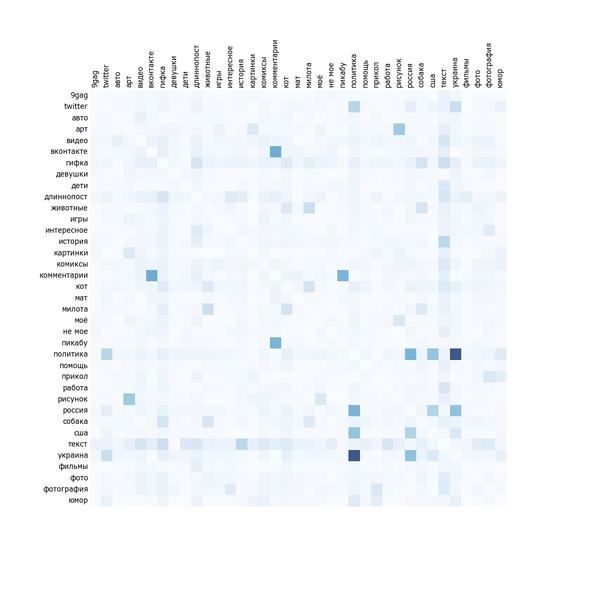
Чем синее квадрат на пересечении, тем чаще эти два тега встречаются вместе. Очевидно, что рисунок симметричен. Хоть тег сам с собой встречается постоянно, диагональ специально сделана белой для читабельности.
В общем-то анализ не слишком показателен. Тегов всего 37 на большой картинке. Невооружённым глазом видна плеяда «политика», «Украина», «США», «Россия», «twitter». «Милота», «собаки», «коты» и «животные» часто встречаются вместе. Также можно увидеть, что «моё», «рисунок» и «арт» часто встречаются вместе. Комментарии чаще всего с Пикабу или ВКонтакте. Текст коррелирует вообще со всем, причём «не моего» текста на Пикабу больше, чем «моего». Будем надеяться, что влияние статистических артефактов окажется малым.
Кто-то может сказать, что вышеперечисленные умозаключения довольно капитанские. Я же отвечу, что приятно, когда формальный анализ сходится с интуитивными предположениями.
Итак, промежуточные выводы:
1) Постов с рейтингом выше шести тысяч исключительно мало.
1.5) Тем не менее, повезти может каждому, было бы начальное внимание к посту (от 100 плюсов).
1.75) Коэффициент везения зависит от качества контента и от количество «0» в нике.
2) Для более высокого рейтинга постов лучше постить что-то, что понятно каждому.
2.5) Но не политику. Кармалюбствовать на политике не выгодно.
В следующих частях: временной анализ (общий и по тегами), рассказ про статистическое искажение, ссылка на исходный код.
12 функций Telegram, о которых вы могли не знать
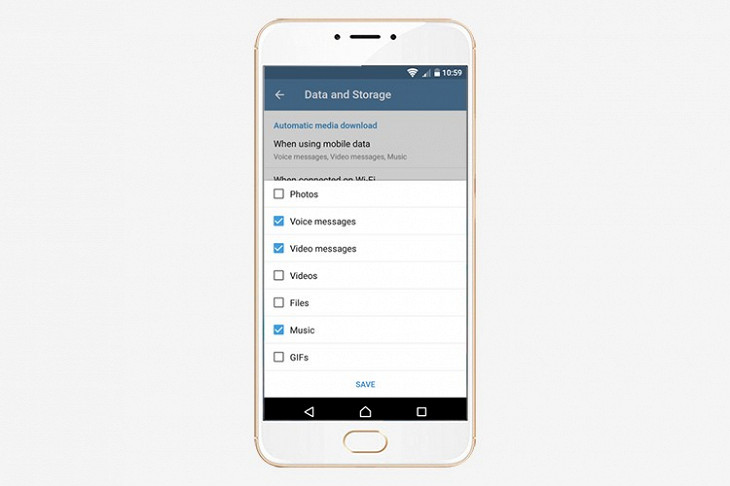
Telegram передает файлы размером до 1,5 гигабайта, которые кэшируются в памяти телефона или компьютера. Чтобы поток фотографий, видео и гифок не засорял память, настройте автозагрузку файлов. Отключите автозагрузку полностью, только для мобильного интернета или выберите нежелательные категории: картинки, аудиосообщения, гифки, видео и другие. Например, если отключить загрузку фотографий, то новые картинки в чате отобразятся размытыми превью, и каждую придется загружать отдельно. Для подробной настройки перейдите в раздел Data and Storage. Там же очистите кэш приложения (в пункте Storage Usage). Во время подготовки материала с телефона были удалены 324 мегабайта кэшированных файлов.
Секретный просмотр сообщений
Допустим, пришло сообщение, которое вы очень хотите прочитать, но не хотите, чтобы собеседник знал об этом. Активируйте авиарежим в настройках телефона, зайдите в Telegram и прочитайте сообщение, а затем закройте приложение и выключите авиарежим. Таким образом, вы прочитаете сообщение, но у собеседника оно будет отображаться как непрочитанное.
Картинка в картинке
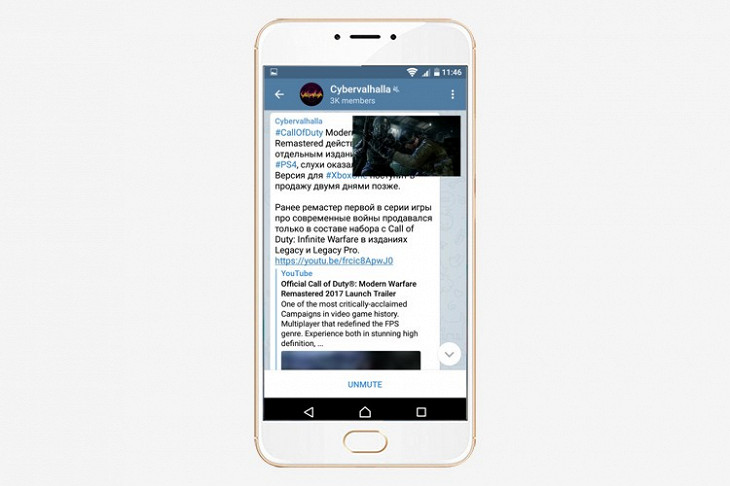
Видео с YouTube воспроизводится прямо в чатах, без перехода по ссылке или запуска другого приложения. Для этого нажмите на превью ролика. Это удобно, но еще удобнее смотреть видео и читать переписку. Чтобы отправить видео в режим «картинка в картинке», нажмите на иконку в правом верхнем углу плеера. Режим работает не только внутри чата — видео останется на экране, даже если перейти в другой чат или свернуть приложение.
Редактирование сообщений
Ошибки и опечатки в сообщениях встречаются ежедневно и нередко становятся мемами. Не становитесь объектом насмешек — редактируйте отправленные сообщения. Долгое нажатие на свое сообщение в iOS и короткое в Android вызывает меню — нажмите в нем на кнопку Edit. После редактирования нажмите Save — актуальная версия сообщения появится в чате. В секретных чатах редактировать сообщения нельзя.
Уведомления без предпросмотра
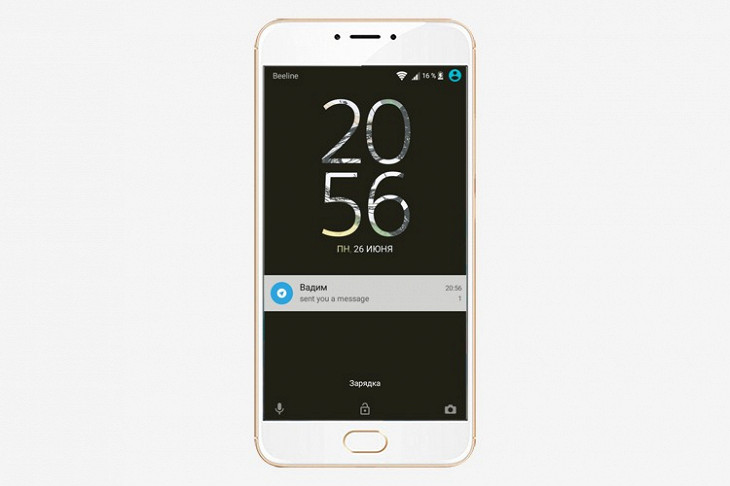
Если не хотите, чтобы кто-то увидел, что вы обсуждаете в мессенджере, отключите предпросмотр сообщений в уведомлениях. Для этого перейдите в настройки, зайдите в раздел Notifications & Sounds и отключите пункт Message Preview для обычных сообщений и сообщений из общих чатов.
Защита чатов паролем
Если вы отключили предпросмотр сообщений в уведомлениях, но все еще переживаете за приватность переписки, закройте чаты паролем. Для этого зайдите в раздел Privacy and Security, придумайте четырехзначный пароль и установите его в пункте Passcode Lock. На главном экране появится иконка замка — нажмите на нее, чтобы замок «закрылся». В следующий раз (после того как закроете, свернете мессенджер или заблокируете телефон) приложение попросит ввести указанный пароль и только потом покажет экран с чатами. Пароль действует один раз, поэтому не забывайте нажимать на иконку замка, когда выходите из приложения.
Уничтожение сообщений по времени
Секретные чаты, самая обсуждаемая функция Telegram, умеют удалять сообщения автоматически. Они исчезают через некоторое время после того, как собеседник их прочитал. Перейдите в настройки секретного чата, выберите Set Self-Destruct Timer и установите время, спустя которое сообщения удалятся автоматически. Минимальное время — одна секунда, максимальное — одна неделя.
Самодельные гифки
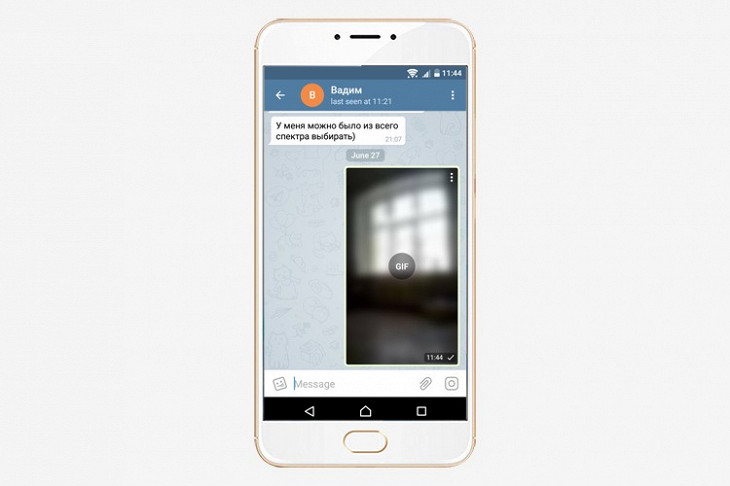
В Telegram есть простейший способ сделать гифку с собой и друзьями. Для этого откройте встроенную камеру, запишите видео, а потом выключите в нем звук. Видео без звука отправится в чат в формате GIF и будет бесконечно проигрываться по кругу.
Скрытый онлайн-статус от нежелательных контактов
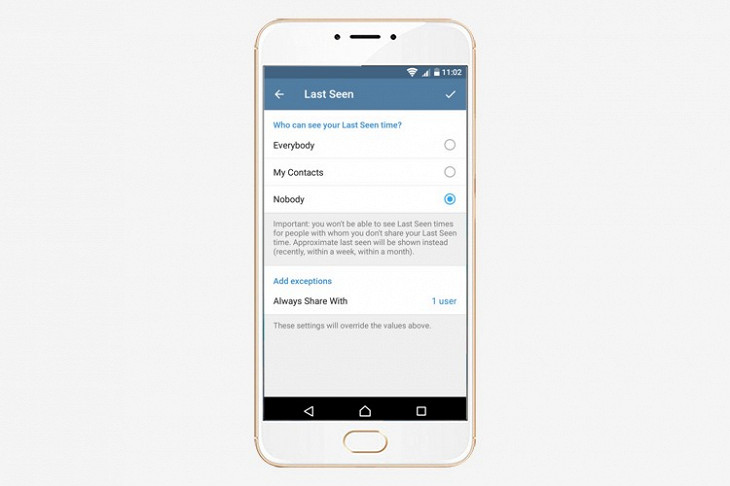
Многие знают, что в Telegram можно скрыть свой онлайн-статус (то есть собеседник не увидит, когда вы пользовались мессенджером последний раз). Если не знали, то настройте это в разделе Privacy and Security. Там можно скрыть последнюю активность от всех контактов, кроме лучшего друга. Или, наоборот, скрыть только от неприятного начальника, который постоянно пишет на выходных. Но помните, Telegram пишет в статусе «last seen recently», если вы заходили хотя бы три дня назад.
Закрепленные чаты
Закрепите важный чат в самом верху списка. В iOS смахните влево по чату в списке, в небольшом меню выберите Pin Chat. Чтобы попасть в это меню в Android, удерживайте палец на чате.
Видеосообщения
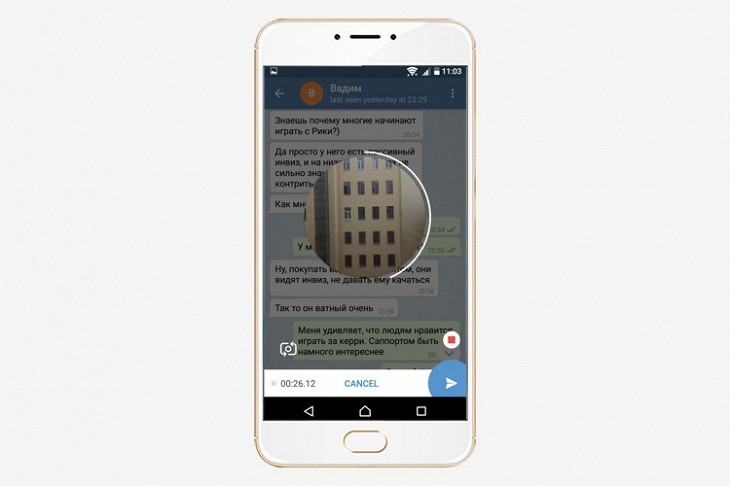
Если мало аудиосообщений, отправляйте видеосообщения. Перейдите в любой чат, нажмите на значок микрофона и переключитесь в режим камеры. Удерживайте иконку, чтобы записать видео в круглой рамке, и отпустите, чтобы отправить, — как с аудиосообщениями. Владельцы каналов записывают такие видео и отправляют их при помощи платформы Telescope. По ссылке telesco.pe/channelname (где channelname — логин канала) собраны все видео автора. Оттуда их отправляют в Facebook и Twitter. Например, по этой ссылке найдете видеопоток канала «Дневник визажидзе».
Цвета для индикатора сообщений
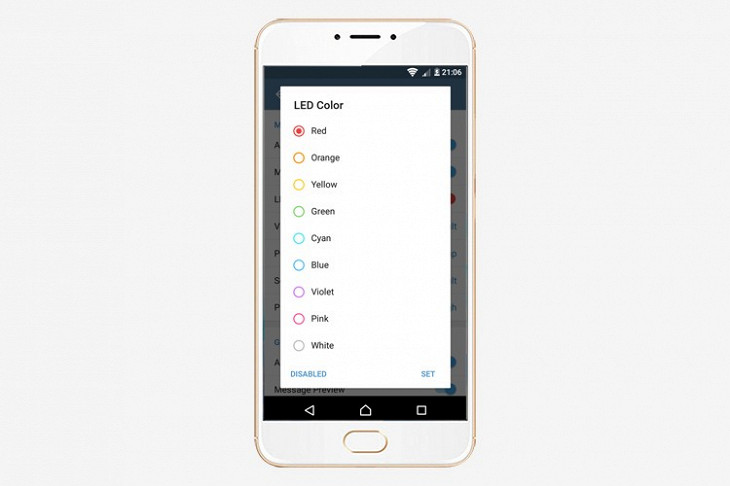
Там же, в разделе Notifications & Sounds, можно выбрать цвет, которым светодиод над экраном сигнализирует о новых сообщениях. По умолчанию Telegram использует синий, но в меню на выбор есть еще восемь цветов. Из этой косметической функции можно извлечь пользу. Если состоите в общем чате, поставьте для сообщений из него другой цвет индикатора. Тогда, чтобы понять, откуда пришло сообщение, не придется снимать блокировку и открывать центр уведомлений — достаточно просто посмотреть на огонек. Для настройки выберите пункты LED Color. Функция доступна только для пользователей мобильной версии Telegram на Android.