Зависимые и независимые случайные величины.
Условные законы распределения и ковариация дискретных СВ
На первом уроке по теме уже фигурировали задачи с независимыми случайными величинами, и давайте сразу вспомним, что это значит: случайные величины являются независимыми, если закон распределения вероятностей любой из них, не зависит от того, какие значения приняли (или примут) остальные случайные величины.
Например, система двух игральных кубиков – совершенно понятно, что результат броска одного кубика никак не влияет на вероятности выпадения граней другого кубика. Или одинаковые независимо работающие игровые автоматы. И, наверное, у некоторых сложилось впечатление, что независимы вообще любые СВ. Однако это далеко не всегда так.
Рассмотрим одновременное сбрасывание двух кубиков-магнитов, у которых северные полюса находятся на стороне 1-очковой грани и южные – на противоположной грани в 6 очков. Будут ли независимыми аналогичные случайные величины? Да, будут. Просто снизятся вероятности выпадения «1» и «6» и увеличатся шансы других граней, т.к. в результате испытания кубики могут притянуться противоположными полюсами.
Теперь рассмотрим систему , в которой кубики сбрасываются последовательно:
– количество очков, выпавших на первом кубике;
– количество очков, выпавших на втором кубике, при условии, что он всё время сбрасывается по правую (например) сторону от 1-го кубика.
В этом случае закон распределения случайной величины зависит от того, как расположился 1-й кубик. Вторая кость может либо притянуться, либо наоборот – отскочить (если «встретились» одноимённые полюса), либо частично или полностью проигнорировать 1-й кубик.
Второй пример: предположим, что одинаковых игровых автоматов объединены в единую сеть, и – есть система случайных величин — выигрышей на соответствующих автоматах. Не знаю, законна ли эта схема, но владелец игрового зала вполне может настроить сеть следующим образом: при выпадении крупного выигрыша на каком-либо автомате, автоматически меняются законы распределения выигрышей вообще на всех автоматах. В частности, целесообразно на некоторое время обнулить вероятности крупных выигрышей, чтобы заведение не столкнулось с нехваткой средств (в том случае, если вдруг кто-то выиграет по-крупному ещё раз). Таким образом, рассмотренная система будет зависима.
То были примеры с дискретными случайными величинами. Но, разумеется, существуют и дву- и большемерные непрерывные случайные величины. Пример третий, баян:
– рост наугад выбранного человека;
И для наглядности представим две группы людей: ростом 160 и 190 см. Совершенно понятно, что во 2-й группе окажутся преимущественно более тяжелые люди, нежели в 1-й. То есть, распределение случайной величины зависит от того, какое значение приняла случайная величина , и поэтому система зависима. В отличие от жёсткой функциональной зависимости (а-ля ) здесь имеет место вероятностная, или как говорят, стохастическая зависимость. Это проявляется в том, что, выбрав наугад человека невысокого (например) роста, более вероятно столкнуться со «стандартным» весом таких людей, но всё же существует вероятность, что у него окажется очень большой либо очень маленький вес для своей «ростовой категории».
Как составить закон распределения системы зависимых СВ? Для независимых дискретных систем мы использовали теорему умножения вероятностей независимых событий, и Капитан Очевидность подсказывает, что сейчас нужно применить аналогичную теорему для зависимых событий.
В качестве демонстрационного примера рассмотрим колоду из 8 карт, пусть это будут короли и дамы, и простую игру, в которой два игрока последовательно (не важно, в каком порядке) извлекают из колоды по одной карте. Рассмотрим случайную величину , которая символизирует одного игрока и принимает следующие значения: 1, если он извлёк червовую карту, и 0 – если карту другой масти.
Аналогично, пусть случайная величина символизирует другого игрока и тоже принимает значения 0 либо 1, если он извлёк не черву и черву соответственно.
– вероятность того, что оба игрока извлекут черву,
– вероятность того, что оба извлекут не черву, и:
– вероятность того, что один извлечёт черву, а другой – нет; ну или наоборот:
Таким образом, закон распределения вероятностей зависимой системы : 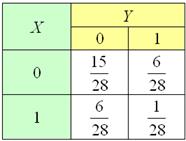
Контроль: , что и требовалось проверить. …Возможно, у вас возник вопрос, а почему я рассматриваю именно 8, а не 36 карт? Да просто для того, чтобы дроби получились не такими громоздкими.
Теперь немного проанализируем результаты. Если просуммировать вероятности по строкам: , то получится в точности закон распределения случайной величины : 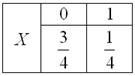
Легко понять, что это распределение соответствует ситуации, когда «иксовый» игрок тянет карту один, без «игрекового» товарища, и его математическое ожидание:
– равно вероятности извлечения червы из нашей колоды.
Аналогично, если просуммировать вероятности по столбцам, то получим закон распределения одиночной игры второго игрока: 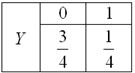
с тем же матожиданием
В силу «симметрии» правил игры, распределения получились одинаковыми, но, в общем случае, они, конечно, различны.
Помимо этого, полезно рассмотреть условные законы распределения вероятностей. Это ситуация, когда одна из случайных величин уже приняла какое-то конкретное значение, или же мы предполагаем это гипотетически.
Пусть «игрековый» игрок тянет карту первым и извлёкает не черву . Вероятность этого события составляет (суммируем вероятности по первому столбцу таблицы – см. вверху). Тогда, из той же теоремы умножения вероятностей зависимых событий получаем следующие условные вероятности:
– вероятность того, что «иксовый» игрок вытянет не черву при условии, что «игрековый» вытянул не черву;
– вероятность того, что «иксовый» игрок вытянет черву, при условии, что «игрековый» вытянул не черву.
…все помнят, как избавляться от четырёхэтажных дробей? И да, формальное, но очень удобное техническое правило вычисления этих вероятностей: сначала следует просуммировать все вероятности по столбцу, и затем каждую вероятность разделить на полученную сумму.
Таким образом, при условный закон распределения случайной величины запишется так: 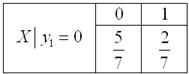
, ОК. Вычислим условное математическое ожидание:
Теперь составим закон распределения случайной величины при условии, что случайная величина приняла значение , т.е. «игрековый» игрок извлёк карту червовой масти. Для этого суммируем вероятности 2-го столбца таблицы (см. вверху): и вычисляем условные вероятности:
– того, что «иксовый» игрок вытянет не черву,
– и черву.
Таким образом, искомый условный закон распределения: 
Контроль: , и условное математическое ожидание:
– разумеется, оно получилось меньше, чем в предыдущем случае, так как «игрековый» игрок убавил количество черв в колоде.
«Зеркальным» способом (работая со строками таблицы ) можно составить – закон распределения случайной величины , при условии, что случайная величина приняла значение , и условное распределение , когда «иксовый» игрок извлёк черву. Легко понять, что в силу «симметрии» игры, получатся те же распределения и те же значения .
Для непрерывных случайных величин вводятся такие же понятия условных распределений и матожиданий, но если в них нет горячей надобности, то лучше продолжить изучение этого урока.
На практике в большинстве случаев вам предложат готовый закон распределения системы случайных величин:
Двумерная случайная величина задана своим законом распределения вероятностей: 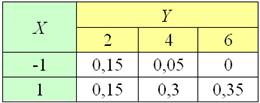
…хотел рассмотреть таблицу побольше, но решил таки не маньячить, ведь главное разобраться в самом принципе решения.
1) Составить законы распределения и вычислить соответствующие математические ожидания. Сделать обоснованный вывод о зависимости или независимости случайных величин .
Это задание для самостоятельного решения! Напоминаю, что в случае независимости СВ законы должны получиться одинаковыми и совпасть с законом распределения случайной величины , и законы – совпасть с . Десятичные дроби, кто не знает или позабыл, удобно делить так: .
Свериться с образцом можно внизу страницы.
2) Вычислить коэффициент ковариации.
Сначала разберёмся в самом термине, и откуда он вообще произошёл: когда случайная величина принимает различные значения, то говорят, что она варьируется, и количественное измерение этой вариации, как вы знаете, выражается дисперсией. Используя формулу вычисления дисперсии, а также свойства матожидания и дисперсии, нетрудно установить, что:
то есть, при сложении двух случайных величин суммируются их дисперсии и добавляется дополнительное слагаемое, характеризующее совместную вариацию или коротко – ковариацию случайных величин.
Ковариация или корреляционный момент – это мера совместной вариации случайных величин.
Обозначение: или
Ковариация дискретных случайных величин определяется, сейчас буду «выражаться»:), как математическое ожидание произведения линейных отклонений этих случайных величин от соответствующих матожиданий:
Если , то случайные величины зависимы. Образно говоря, ненулевое значение говорит нам о закономерных «откликах» одной СВ на изменение другой СВ.
Ковариацию можно вычислить двумя способами, я рассмотрю оба.
«Страшная» формула и совсем не страшные вычисления. Сначала составим законы распределения случайных величин и – для этого суммируем вероятности по строкам («иксовая» величина) и по столбцам («игрековая» величина): 
Взгляните на исходную верхнюю таблицу – всем понятно, как получились распределения? Вычислим матожидания:
и отклонения значений случайных величин от соответствующих математических ожиданий:
Полученные отклонения удобно поместить в двумерную таблицу, внутрь которой затем переписать вероятности из исходной таблицы: 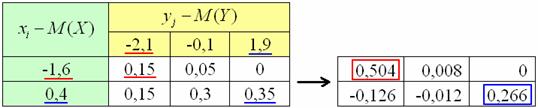
Теперь нужно вычислить все возможные произведения , в качестве примера я выделил: (красный цвет) и (синий цвет). Вычисления удобно проводить в Экселе, а на чистовике расписать всё подробно. Я привык работать «по строкам» слева направо и поэтому сначала перечислю все возможные произведения с «иксовым» отклонением -1,6, затем – с отклонением 0,4:
Способ второй, более простой и распространённый. По формуле:
Матожидание произведения СВ определяется как и технически всё очень просто: берём исходную таблицу задачи и находим все возможные произведения на соответствующие вероятности ; на рисунке ниже я выделил красным цветом произведение и синим произведение : 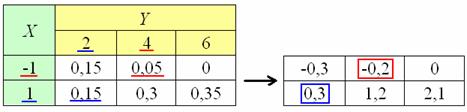
Сначала перечислю все произведения со значением , затем – со значением , но вы, разумеется, можете использовать и другой порядок перебора – кому как удобнее:
Значения уже вычислены (см. 1-й способ), и осталось применить формулу:
Как отмечалось выше, ненулевое значение ковариации говорит нам о зависимости случайных величин, причём, чем оно больше по модулю, тем эта зависимость ближе к функциональной линейной зависимости . Ибо определяется через линейные отклонения.
Таким образом, определение можно сформулировать точнее:
Ковариация – это мера линейной зависимости случайных величин.
С нулевым значением всё занятнее. Если установлено, что , то случайные величины могут оказаться как независимыми, так и зависимыми (т.к. зависимость может носить не только линейный характер). Таким образом, этот факт в общем случае нельзя использовать для обоснования независимости СВ!
Однако, если известно, что независимы, то . В этом легко убедиться аналитически: так как для независимых случайных величин справедливо свойство (см. предыдущий урок), то по формуле вычисления ковариации:
Какие значения может принимать этот коэффициент? Коэффициент ковариации принимает значения, не превосходящие по модулю – и чем больше , тем сильнее выражена линейная зависимость. И всё вроде бы хорошо, но есть существенное неудобство такой меры:
Предположим, мы исследуем двумерную непрерывную случайную величину (готовимся морально :)), компоненты которой измеряются в сантиметрах, и получили значение . Кстати, какая размерность у ковариации? Коль скоро, – сантиметры, и – тоже сантиметры, то их произведение и матожидание этого произведения – выражается в квадратных сантиметрах, т.е. ковариация, как и дисперсия – есть квадратичная величина.
Теперь предположим, что кто-то изучил ту же систему , но использовал не сантиметры, а миллиметры. Так как 1 см = 10 мм, то ковариация увеличится в 100 раз и будет равна !
Поэтому удобно рассмотреть нормированный коэффициент ковариации, который давал бы нам одинаковое и безразмерное значение. Такой коэффициент получил название, продолжаем нашу задачу:
3) Коэффициент корреляции. Или, точнее, коэффициент линейной корреляции:
, где – стандартные отклонения случайных величин.
Коэффициент корреляции безразмерен и принимает значения из промежутка:
(если у вас на практике получилось другое – ищите ошибку).
Чем больше по модулю к единице, тем теснее линейная взаимосвязь между величинами , и чем ближе к нулю – тем такая зависимость выражена меньше. Взаимосвязь считается существенной, начиная примерно с . Крайним значениям соответствует строгая функциональная зависимость , но на практике, конечно, «идеальных» случаев не встретить.
Очень хочется привести много интересных примеров, но корреляция более актуальна в курсе математической статистики, и поэтому я приберегу их на будущее. Ну а сейчас найдём коэффициент корреляции в нашей задаче. Так. Законы распределения уже известны, скопирую сверху: 
Матожидания найдены: , и осталось вычислить стандартные отклонения. Табличкой уж оформлять не буду, быстрее подсчитать строкой:
Ковариация найдена в предыдущем пункте , и осталось рассчитать коэффициент корреляции:
, таким образом, между величинами имеет место линейная зависимость средней тесноты.
Четвёртое задание опять же более характерно для задач математической статистики, но на всякий случай рассмотрим его и здесь:
4) Составить уравнение линейной регрессии на .
Уравнение линейной регрессии – это функция , которая наилучшим образом приближает значения случайной величины . Для наилучшего приближения, как правило, используют метод наименьших квадратов, и тогда коэффициенты регрессии можно вычислить по формулам:
, вот это чудеса, и 2-й коэффициент:
Таким образом, искомое уравнение регрессии:
ну и давайте ради исследовательского интереса я скопирую табличку сверху: 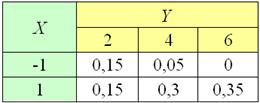
и вычислю значения функции:
– в результате получился результат, который близок к наиболее вероятному (см. 2-ю снизу строку) значению ;
– тоже неплохо, это приближение попало между наиболее вероятными (см. нижнюю строку) значениями
Вполне и вполне приличные результаты, несмотря на невысокий коэффициент корреляции. И, наверное, вы уже догадались, что чем ближе по модулю к единице, тем точнее функция приближает наиболее вероятные значения случайной величины . Но уравнение линейной регрессии, конечно, больше применимо к двумерной непрерывной случайной величине, поскольку позволяет осуществлять реальное прогнозирование, например, наиболее вероятного веса человека по заданному росту.
Творческое задание для самостоятельного решения:
Вычислить коэффициенты ковариации и корреляции для демонстрационного примера данного урока (с картами червовой масти) и оценить тесноту линейной связи между СВ.
после чего с нетерпением переходим к системам непрерывных случайных величин.
Решения и ответы:
Пример 4, пункт 1. Решение:
1) Составим закон распределения , для этого суммируем все вероятности соответствующего столбца: и делим каждую вероятность на полученную сумму:
Так как вероятности изменились, то мы имеем дело с условными вероятностями, и из этого можно сразу сделать вывод, что случайные величины зависимы.
! Примечание: в случае независимости СВ вероятности остались бы прежними! – желающие могут проверить данный факт на любом примере предыдущего урока.
Таким образом, условное распределение вероятностей: 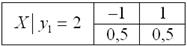
и условное математическое ожидание:
2) Составим закон распределения . Суммируем вероятности соответствующего столбца: и делим каждую из них на полученную сумму:
Таким образом: 
И здесь делаем вывод, что распределение случайной величины зависит от того, какое значение приняла случайная величина , что является ещё более убедительным обоснованием зависимости этих СВ.
Условное матожидание: .
3) Аналогично находим закон распределения :
Таким образом, при случайная величина достоверно примет значение 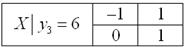
и, очевидно, .
4) Чтобы составить закон распределения , нужно просуммировать все вероятности соответствующей строки: и разделить каждую из них на полученную сумму: 
5) И, наконец, 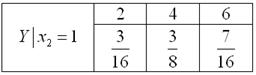
Контроль: , ч.т.п.
Пример 5. Решение: коэффициент ковариации вычислим по формуле:
Коэффициент корреляции вычислим по формуле:
Найдём стандартные отклонения случайных величин:
Закон распределения точно такой же, поэтому .
Таким образом:
Полученное значение достаточно близко к нулю, что говорит о слабой зависимости случайных величин. Тем не менее, знак «минус» показывает, что при увеличении значения одной из случайных величин (от 0 до 1) уменьшаются шансы извлечения червы другим игроком
Примечание: при достаточно малых значениях (ниже 0,3-0,4 по модулю) построение уравнения линейной регрессии теряет смысл, т.к. оно недостоверно приблизит исходные данные.
Автор: Емелин Александр
(Переход на главную страницу)
 Contented.ru – онлайн школа дизайна
Contented.ru – онлайн школа дизайна
SkillFactory – получи востребованную IT профессию!
Научный форум dxdy
Каждая из случайных величин  и
и 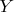 принимает лишь два значения, причем
принимает лишь два значения, причем  . Докажите, что и независимы
. Докажите, что и независимы
Рассматриваю величины и , мат. ожидание которых равно нулю (если это не так, вычту из и их мат. ожидания и тогда из независимости полученных переменных будет следовать и независимость и ).
и принимают значения  ,
,  ,
, 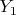 и ,
и ,  соответственно
соответственно
Тогда: ![$Cov(X, Y) = E[X \cdot Y] = X_1 Y_1 \cdot P(X=X_1, Y=Y_1) + X_1 Y_2 \cdot P(X=X_1, Y=Y_2) + X_2 Y_1 \cdot P(X=X_2, Y=Y_1) + X_2 Y_2 \cdot P(X=X_2, Y=Y_2) = 0$](https://dxdy-01.korotkov.co.uk/f/c/4/a/c4a19461714e55c2c5840fcfe3e94ae982.png)
Но не могу понять как из этого доказать независимость и
Последний раз редактировалось vicvolf 22.03.2020, 12:33, всего редактировалось 7 раз(а).
Каждая из случайных величин и принимает лишь два значения, причем . Докажите, что и независимы
Если для невырожденных случайных величин  выполняется:
выполняется:  , то они являются независимыми. Напомню, что вырожденной случайной величиной называется случайная величина,принимающая одно значение с вероятностью равной 1. В данном случае случайные величины принимают два значения, поэтому являются невырожденными. Здесь все просто
, то они являются независимыми. Напомню, что вырожденной случайной величиной называется случайная величина,принимающая одно значение с вероятностью равной 1. В данном случае случайные величины принимают два значения, поэтому являются невырожденными. Здесь все просто  . Поэтому выполняется . (отредактировал текст)
. Поэтому выполняется . (отредактировал текст)
Последний раз редактировалось Otta 22.03.2020, 12:46, всего редактировалось 1 раз.
А что именно «просто»?
Если для невырожденных случайных величин выполняется: , то они являются независимыми.
Последний раз редактировалось DeBill 22.03.2020, 12:51, всего редактировалось 1 раз.
Если для невырожденных случайных величин выполняется: , то они являются независимыми.
Здесь есть неточности: 1. Вместо запятой должно быть умножение, да?
2. Утверждение верно для ВЫРОЖДЕННЫХ (а для НЕ — не, вообще говоря)
И составляет это содержание стандартной задачи «приведите пример некоррелированных, но не независимых»
Независимые случайные величины
Иначе говоря, две случайные величины называются независимыми, если по значению одной нельзя сделать выводы о значении другой.
Независимость в совокупности
| Определение: |
| Случайные величины [math]\xi_1, \ldots ,\xi_n[/math] называются независимы в совокупности (англ. mutually independent), если события [math]\xi_1 \leqslant \alpha_1, \ldots ,\xi_n \leqslant \alpha_n[/math] независимы в совокупности. |
Примеры
Карты
Пусть есть колода из [math]36[/math] карт ( [math]4[/math] масти и [math]9[/math] номиналов). Мы вытягиваем одну карту из случайным образом перемешанной колоды (вероятности вытягивания каждой отдельной карты равны). Определим следующие случайные величины:
[math]\xi[/math] — масть вытянутой карты : [math]0[/math] — червы, [math]1[/math] — пики, [math]2[/math] — крести, [math]3[/math] — бубны
[math]\eta[/math] : принимает значение [math]0[/math] при вытягивании карт с номиналами [math]6, 7, 8, 9, 10[/math] или [math]1[/math] при вытягивании валета, дамы, короля или туза
Для доказательства того, что [math]\xi, \eta[/math] независимы, требуется рассмотреть все [math]\alpha,\beta[/math] и проверить выполнение равенства: [math]P((\xi \leqslant \alpha)\cap(\eta \leqslant \beta)) = P(\xi \leqslant \alpha) \cdot P(\eta \leqslant \beta)[/math]
Для примера рассмотрим [math]\alpha = 0, \beta = 0[/math] , остальные рассматриваются аналогично:
[math]P((\xi \leqslant 0)\cap(\eta \leqslant 0)) = [/math] [math] \dfrac<5> <36>[/math]
[math]P(\xi \leqslant 0) \cdot P(\eta \leqslant 0) = [/math] [math] \dfrac<1> <4>[/math] [math] \cdot [/math] [math] \dfrac<5> <9>[/math] [math] = [/math] [math] \dfrac<5> <36>[/math]
Тетраэдр
Рассмотрим вероятностное пространство «тетраэдр». Каждое число соответствует грани тетраэдра (по аналогии с игральной костью): [math]\Omega = \<0, 1, 2, 3\>[/math] . [math]\xi (i) = i \bmod 2[/math] , [math]\eta(i) = \left \lfloor \dfrac <2>\right \rfloor[/math] .
Рассмотрим случай: [math]\alpha = 0[/math] , [math]\beta = 1[/math] . [math]P(\xi \leqslant 0) = [/math] [math] \dfrac<1> <2>[/math] , [math]P(\eta \leqslant 1) = 1[/math] , [math]P((\xi \leqslant 0) \cap (\eta \leqslant 1)) = [/math] [math] \dfrac<1> <2>[/math] .
Для этих значений [math]\alpha[/math] и [math]\beta[/math] события являются независимыми, так же, как и для других (рассматривается аналогично), поэтому эти случайные величины независимы.
Заметим, что если: [math]\xi (i) = i \bmod 3[/math] , [math]\eta(i) = \left \lfloor \dfrac <3>\right \rfloor[/math] , то эти величины зависимы: положим [math]\alpha = 0, \beta = 0[/math] . Тогда [math]P(\xi \leqslant 0) = [/math] [math] \dfrac<1> <2>[/math] , [math]P(\eta \leqslant 0) = [/math] [math] \dfrac<3> <4>[/math] , [math]P((\xi \leqslant 0) \cap (\eta \leqslant 0)) = [/math] [math] \dfrac<1> <4>[/math] [math] \neq P(\xi \leqslant 0) \cdot P(\eta \leqslant 0)[/math] .
Честная игральная кость
Рассмотрим вероятностное пространство «честная игральная кость»: [math]\Omega = \<1, 2, 3, 4, 5, 6\>[/math] , [math]\xi (i) = i \bmod 2[/math] , [math]\eta (i) = \dfrac <\mathcal i><3 \mathcal
При [math]\alpha = 0, \beta = 1[/math] :
[math]P((\xi \leqslant 0)\cap(\eta \leqslant 1)) = [/math] [math] \dfrac<2> <6>[/math] [math] = [/math] [math] \dfrac<1> <3>[/math] , [math]P(\xi \leqslant 0) = [/math] [math] \dfrac<1> <2>[/math] , [math]P(\eta \leqslant 1) = [/math] [math] \dfrac<5> <6>[/math]
[math]P((\xi \leqslant 0)\cap(\eta \leqslant 1)) \neq P(\xi \leqslant 0) \cdot P(\eta \leqslant 1)[/math] , откуда видно, что величины не являются независимыми.
7.4. Независимые случайные величины
Мы уже видели, какое большое значение имеет понятие независимости для случайных событий. Оказывается, что аналогичное понятие можно естественным образом ввести и для случайных величин.
Пусть в результате опыта могут наблюдаться две случайные величины ξ и η. Слова «могут наблюдаться» мы понимаем в том смысле, что для любых двух числовых множеств А и В мы можем сказать, произошло или не произошло каждое из двух событий < ξ A >и < η B >(напомним, что так для краткости обозначаются множества < ω:ξ(ω) A >и < ω:η(ω) B >).. «Независимость» случайных величин интуитивно понимается так, что, зная результат наблюдения над одной случайной величиной, мы ничего не можем сказать дополнительно о другой случайной величине. Этим мотивируется следующее
Определение 7.5. Две случайных величины ξ и η называются
независимыми , если для любых двух числовых множеств А и В события < ξ A >и < η B >независимы, т.е. (см. § 2, п. 2.2) вероятность их произведения равна произведению вероятностей этих событий:
Замечание . Произведение событий < ξ A >и < η B >, т.е. совокупность всех тех ω Ω, для которых одновременно ξ(ω) A и η(ω) B :
мы далее для краткости будем обозначать символом < ξ A ,η B >.
ω Ω , для которых одновременно ξ(ω) = a i и η(ω) = b j , т.е. произведение событий < ξ = a i >= < ω:ξ(ω) = a i >и < η = b j >= < ω:η(ω) = b j >:
Пусть x 1 , x 2 , . x n , . – возможные значения д.с.в. ξ и P (ξ = x i ) = p i , y 1 , y 2 , . y m , . – возможные значения д.с.в. η и P (η = y j ) = q j .
Если случайные величины ξ и η – независимы, то полагая в (7.14) A = < x i >и B = < y j >(одноточечные числовые множества), получим:
P ( ξ = x i ,η = y j ) = P (ξ = x i ) P (η = y j ) = p i q j .
Справедливо и обратное утверждение: если для всех
x 1 , x 2 , . x n , . и
всех y 1 , y 2 , . y m , . выполнено равенство (7.16), то случайные величины ξ иη– независимы.Действительно,длялюбыхчисловыхмножеств А и В имеем:
P ( ξ = x i ,η = y j )
∑ P (ξ = x i ) P (η = y j ) =
= ∑ P (ξ = x i ) ∑ P (η = y j ) = P (ξ A ) P (η B ),
что и требовалось.
Мы видим, таким образом, что справедлива следующая теорема.
Теорема 7.4 . Длянезависимости случайныхвеличинξиη необходимои достаточно, чтобы для любых x i и y j было выполнено равенство (7.16).
Установим теперь некоторые свойства математического ожидания и дисперсии, связанные с понятием независимости случайных величин.
Теорема 7.5. Если случайные величины ξ и η независимы и существуют
ожидание произведения ξη и
= ∑ x i y j P ( ξ = x i ,η = y j ) =
∑ x i y j p i q j = ( ∑ x i p i ) ( ∑ y j q j ) = M ξ M η, ч.т.д.
Обратимся теперь к дисперсии и рассмотрим вопрос о дисперсии суммы ξ + η двух случайных величин не предполагая , поначалу, что эти величины независимы. Вычислим:
D (ξ+η) = M [ ξ+η − M (ξ+η) ] 2 (7 = .6) M [ (ξ − M ξ) + (η − M η) ] 2 =
= M (ξ − M ξ) 2 + M (η − M η) 2 + 2 M [ (ξ − M ξ)(η − M η) ] .
Выражение cov(ξ,η)= M [ (ξ − M ξ)(η − M η) ] называется ковариацией величин ξ и η. Для независимых случайных величин в силу (7.8) и (7.17):
cov(ξ,η) = M (ξ − M ξ) M (η − M η) = 0.
Таким образом, нами доказана Теорема 7.6. Для любых случайных величин
D (ξ+η) = D ξ + D η+2cov(ξ,η).
Для независимых ξ и η
Следствие. Если случайные величины ξ 1 ,ξ 2 . ξ n попарно независимы
(т.е. любые две случайные величины ξ i и
дисперсии D ξ i ( i = 1,2. n ) существуют, то
D (ξ 1 +ξ 2 +. +ξ n ) = D ξ 1 + D ξ 2 + . + D ξ n .
Действительно , достаточно проверить равенство (7.20) для трех
попарно независимых случайных величин
получится по индукции.
Итак, пусть случайные величины ξ,η,ς попарно независимы. Тогда:
D (ξ+η+ς) = D (ξ+(η+ς)) = D ξ + D (η+ς)+2cov(ξ,η+ς) =
= D ξ + D (η+ς)+2cov(ξ,η+ς) = D ξ + D η + D ς + 2cov(ξ,η+ς).
Для cov(ξ,η+ς) имеем:
cov(ξ,η+ς) = M [ (ξ − M ξ)(η+ς − M (η+ς)) ] = = M [ (ξ − M ξ)(η+ς − M η − M ς) ] .
Производя перемножение внутри квадратных скобок и используя свойства математического ожидания и попарную независимость случайных величин ξ,η,ς, получаем cov(ξ,η+ς) = 0. Тогда формула (7.21) дает:
D (ξ+η+ς) = D ξ + D η + D ς
7.5. Неравенство Чебышёва
В этом разделе мы познакомимся с некоторыми важными результатами, использующими понятия математического ожидания, дисперсии и независимости случайных величин.
Теорема 7.7 (неравенство Чебышёва).
Пусть имеется д.с.в. ξ, у которой существуют M ξ и D ξ. Тогда для любого ε > 0 справедливо неравенство:
1. Обозначение P ( ξ − M ξ ≥ ε ) есть сокращенное обозначение для вероятности
x i : x i − M ξ ≥ ε
( x 1 , x 2 , . x n , . – возможные значения случайной величины ξ).
2. Смысл неравенства Чебышёва 56 состоит в том, при малых значениях дисперсии D ξ большие отклонения случайной величины ξ от ее математического ожидания M ξ маловероятны. Это подтверждает представление о дисперсии как мере отклонения случайной величины от ее математического ожидания.
Доказательство теоремы. Имеем:
D ξ = ∑ ( x i − M ξ) 2 P (ξ = x i ).
Если суммированиепо всем x i заменить суммированиемтолькопотем x i ,для которых x i − M ξ ≥ ε, то сумма не увеличится. Поэтому:
D ξ ≥ ∑ ( x i − M ξ) 2 P (ξ = x i ) ≥
x i : x i − M ξ ≥ ε
≥ ε 2 ∑ P (ξ = x i ) = ε 2 P ( ξ − M ξ ≥ ε ) ,
x i : x i − M ξ ≥ ε
что, очевидно, эквивалентно (7.22).
7.6. Закон больших чисел
56 Пафнутий Львович Чебышёв (1821-1894) – один из наиболее видных российских математиков второй половины XIX века, создатель петербургской научной школы, академик Петербургской Императорской Академии Наук с 1856 года.
Случайные величины возникают в приложениях как результаты измерений, причем либо сами измерения подвержены случайным ошибкам, либо объекты измерения случайным образом выбираются из некоторой совокупности. Давно было замечено, что, в то время как результаты отдельных измерений ξ 1 ,ξ 2 . ξ n могут колебаться сильно, их средние
арифметические 1 n (ξ 1 +ξ 2 +. +ξ n ) обнаруживают (при больших n ) гораздо
бóльшую устойчивость, т.е. меняются незначительно (так называемая «устойчивость средних»). Как правило, указанная величина среднего арифметического совокупности n измерений одной и той же физической величины принимается за ее среднее значение , т.е. приближенное значение, которое можно использовать в тех вычислениях, где эта физическая величина встречается. Здесь, однако, имеется определенная тонкость, требующая разъяснения.
Дело в следующем. При измерении физической величины мы не можем заранее указать все факторы, которые в той или иной степени повлияют на показания приборов, с помощью которых мы это измерение производим. Поэтому, результат каждого такого конкретного измерения представляет собой одно из возможных значений некоторой случайной величины, которая определяется совокупностью факторов (явлений-причин), которые сопровождают данный эксперимент по измерению интересующей нас физической величины. При проведении следующего (независящего от предыдущего) измерения той же самой физической величины , даже при соблюдении одинаковости 57 условий, в которых измерения проводятся, мы уже будем иметь дело с другой случайной величиной, одно из возможных значений которой и будет наблюдаться при втором измерении.
Иными словами, каждый конкретный эксперимент по измерению данной физической величины порождает свою случайную величину, одно из
57 В той мере, в которой такую «одинаковость» можно обеспечить. 130
возможных значений которой и наблюдается экспериментатором как показание соответствующего измерительного прибора . Таким образом, мы имеем дело с несколькими (по числу измерений) независимыми случайными величинами. Каждая такая случайная величина имеет свои собственные числовые характеристики (математическое ожидание и дисперсию), которые определяются распределениями каждой из этих случайных величин в отдельности. Интуитивно ясно, что разумнее всего в качестве значения измеряемой в эксперименте физической величины принять ее математическое ожидание, т.е. величину M ξ = ∑ x j p j .
Однако мы никогда непосредственно этого математического ожидания вычислить не можем, так как нам неизвестно распределение соответствующей случайной величины. На практике в качестве значения измеряемой физической величины принимают арифметическое среднее различных измерений этой величины , т.е. значение ( x (1) + x (2) + . + x ( n ) ) 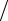 n , где в числителе стоят не возможные значения одной случайной величины, а какие-то из возможных значений разных независимых случайных величин (представляющих различные измерения). Естественно возникает вопрос, в какоймеретакойподходявляетсяудовлетворительным,т.е.великалиразница между математическим ожиданием M ξ и упомянутым арифметическим средним различных измерений?
n , где в числителе стоят не возможные значения одной случайной величины, а какие-то из возможных значений разных независимых случайных величин (представляющих различные измерения). Естественно возникает вопрос, в какоймеретакойподходявляетсяудовлетворительным,т.е.великалиразница между математическим ожиданием M ξ и упомянутым арифметическим средним различных измерений?
Следующая теорема, представляющая собой знаменитый закон больших чисел (в форме Чебышёва), дает ответ на поставленный вопрос.
Теорема 7.8. Пусть случайные величины ξ 1 ,ξ 2 . ξ n попарно независимы и их дисперсии ограничены в совокупности, т.е. D ξ i ≤ c для всех