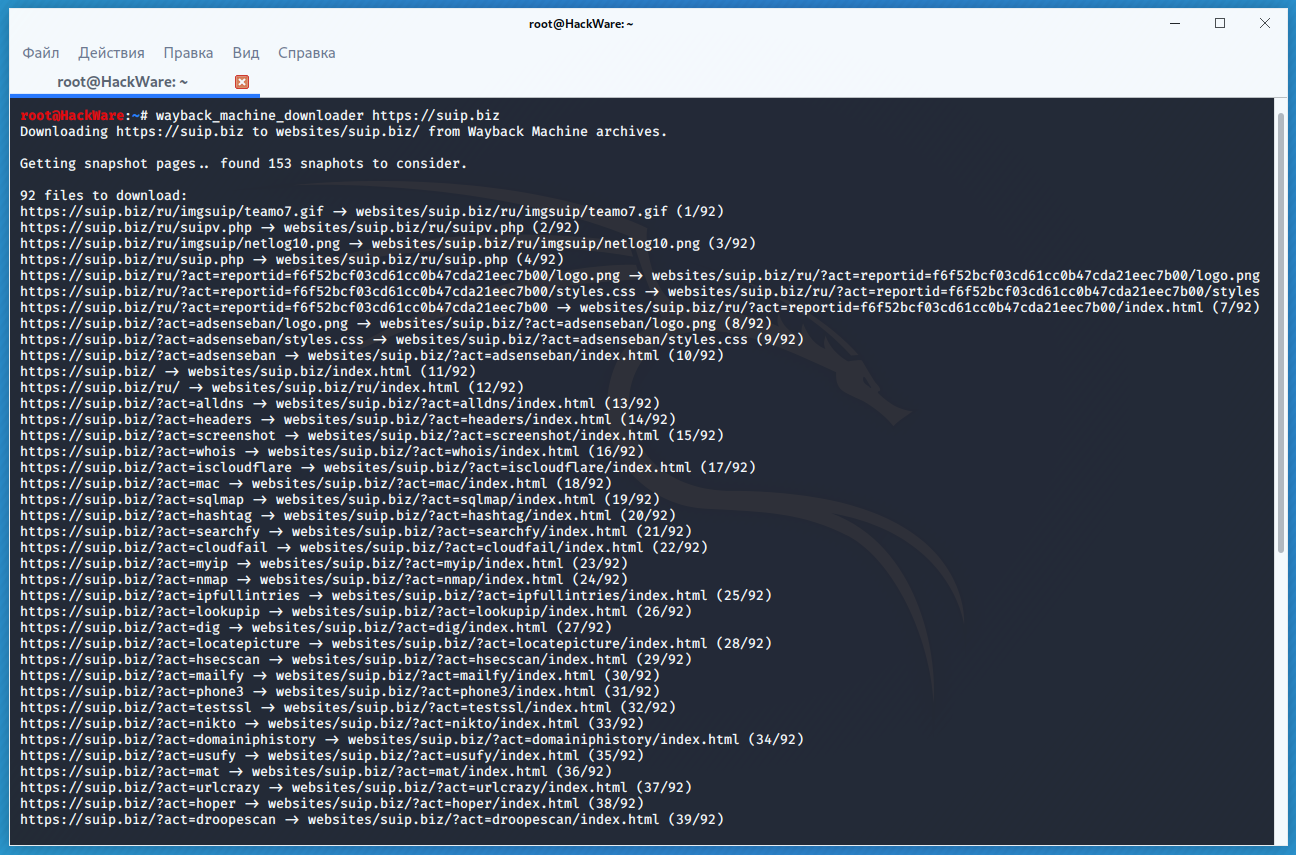
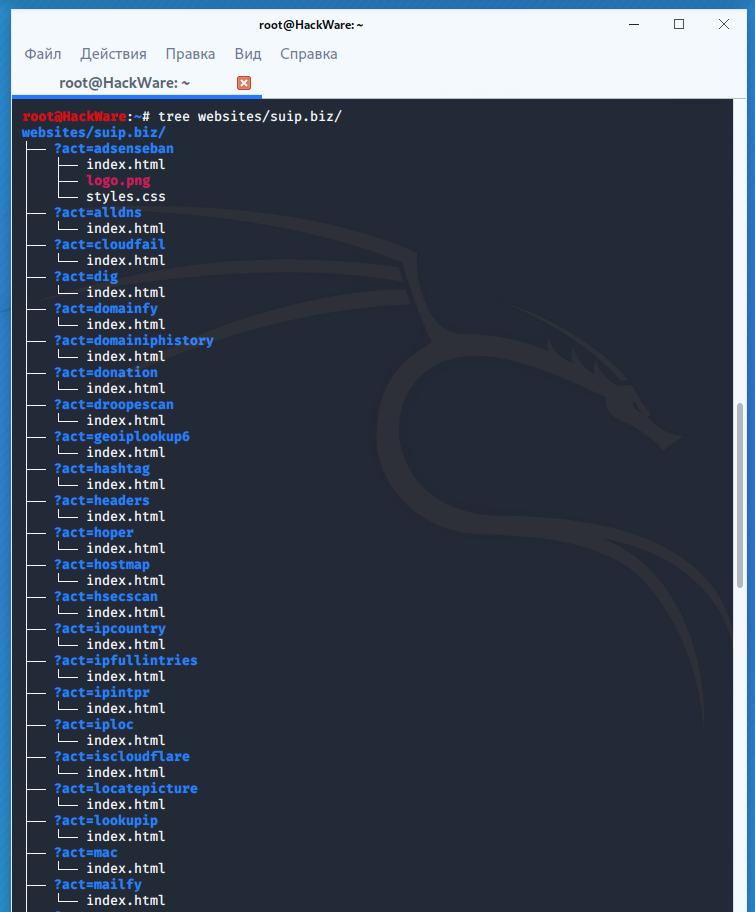
Downloading – A Basic Guide
Are all the files on the Internet Archive downloadable?
No, not all files are downloadable.
There are access restricted items such as books in the lending program and some other collections, as well as some file formats in items to allow other files to be downloaded.
If an item is downloadable, there will a DOWNLOAD OPTIONS box on the right of the page that looks similar to this example.
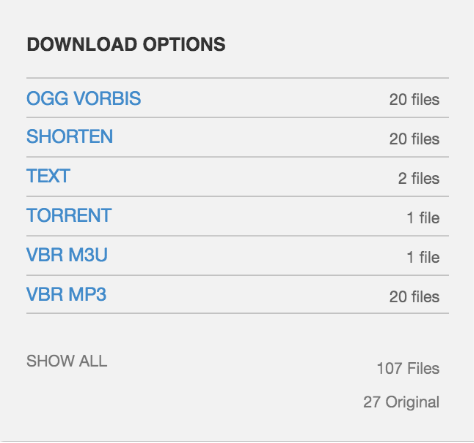
How do I download an item such as an image?
1. To download, go to the DOWNLOAD OPTIONS section on the right side of a page.
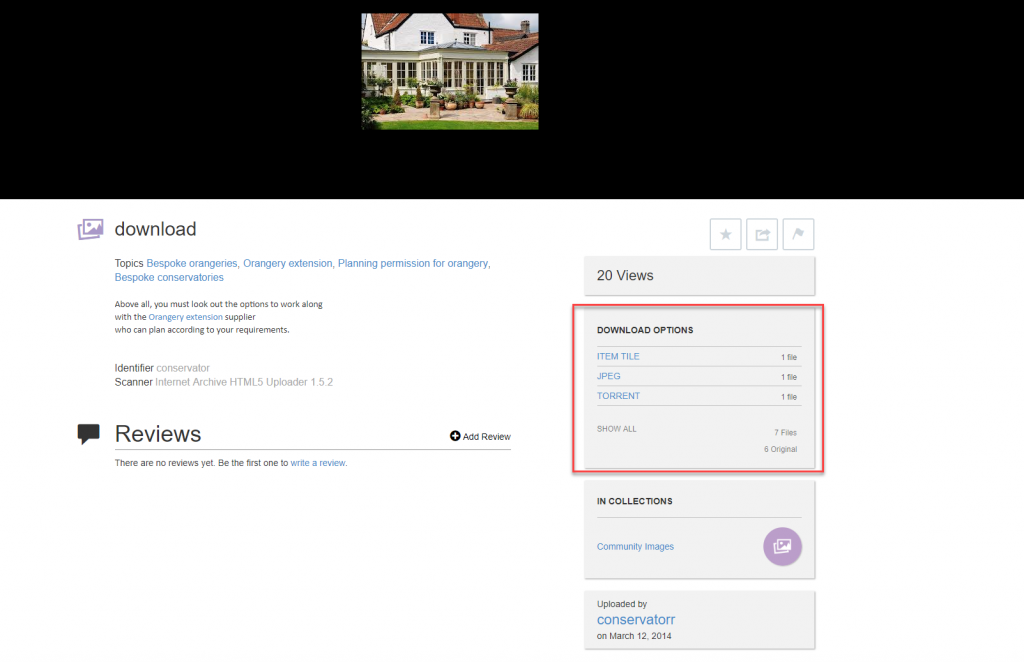
2. Select your preferred Download Option and click on the download icon.
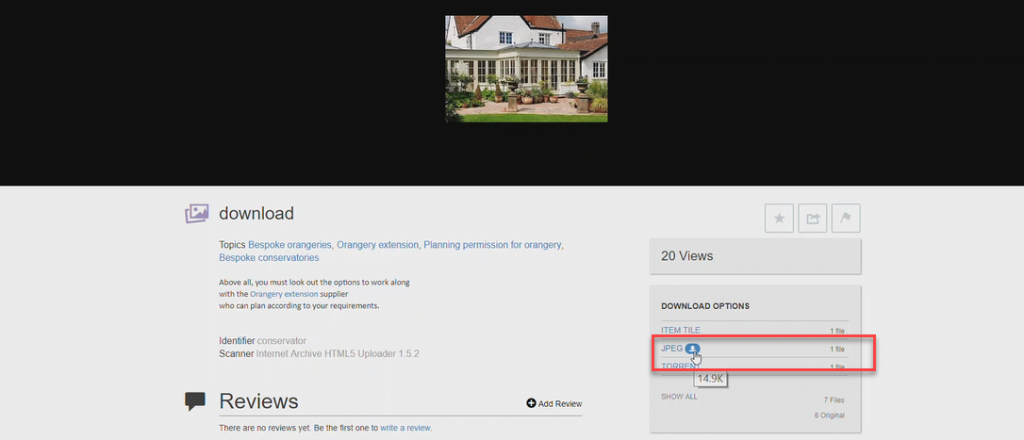
3. Once downloaded, save the item to your preferred location.

How do I download an item that has many files in just one format? For example, all the chapters in an audiobook.
1. Select your preferred DOWNLOAD OPTION
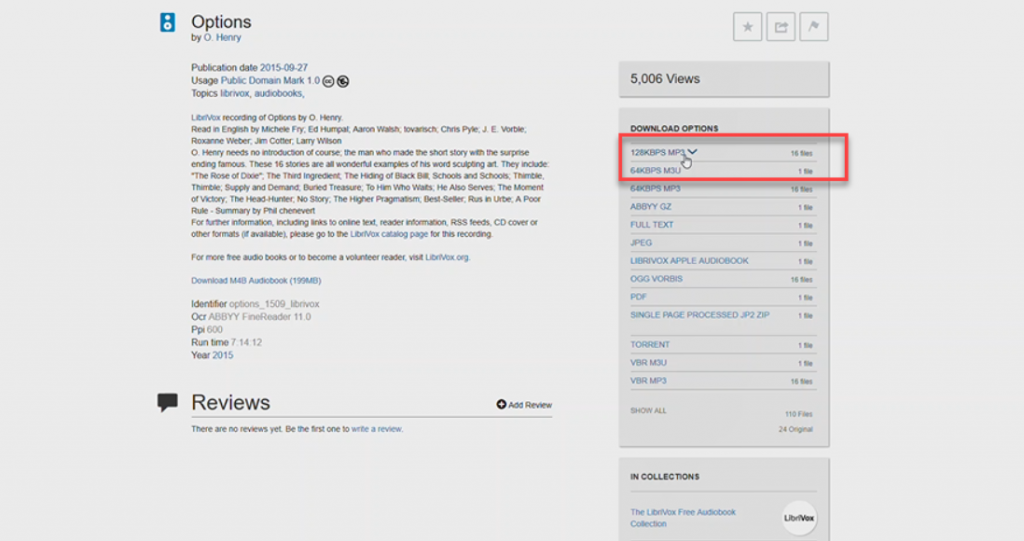
2. Select the download icon to download all the files for that option.
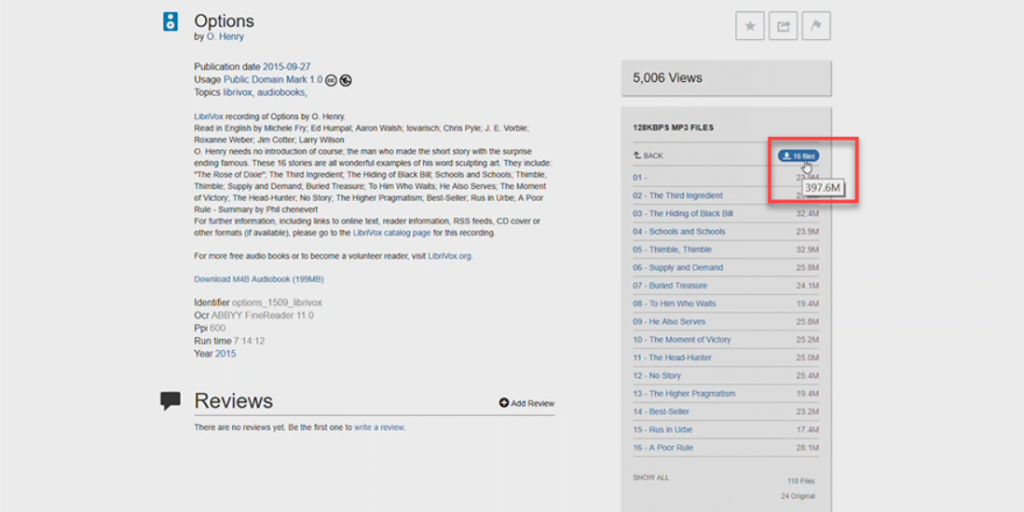
If there are multiple files in that format, you will be prompted to download a zip file containing all the files.
If there is only one file in that format it will either open in your browser (a pdf for example) or download it if it’s a format that does not render in your browser (such as ePuB).
3. You can also download all the originals and metadata or all the files available to download by clicking on one of the links at the bottom of the DOWNLOAD OPTIONS section. In the example below, it’s: 110 Files or 24 Originals.

You will be prompted to download a zip file containing all the files in your selection. (Files or Original)
How do I download one file? For example, one chapter from an audiobook?
1. Select SHOW ALL at the bottom of the DOWNLOAD OPTIONS box.

2. Select the single file that you would like to download.

3. You can listen or view to the selected file in your browser, or you can download it. Just follow the screenshots below.
Press play to listen.

To download, select the

Click Download

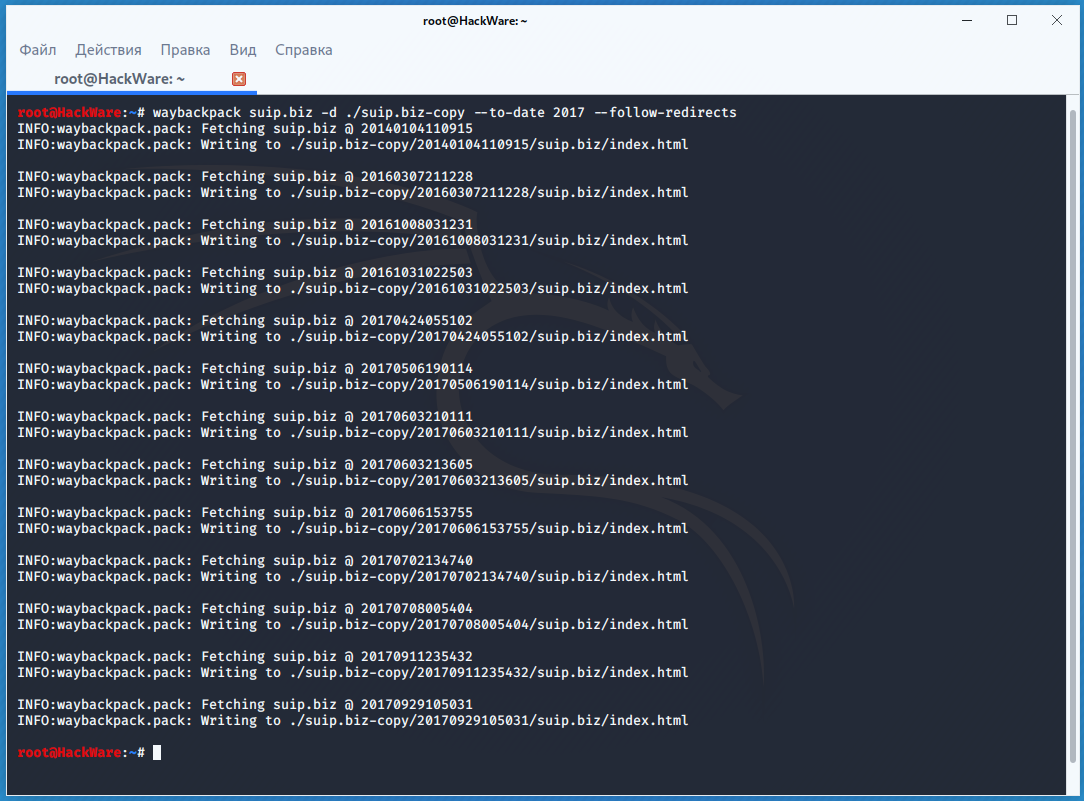
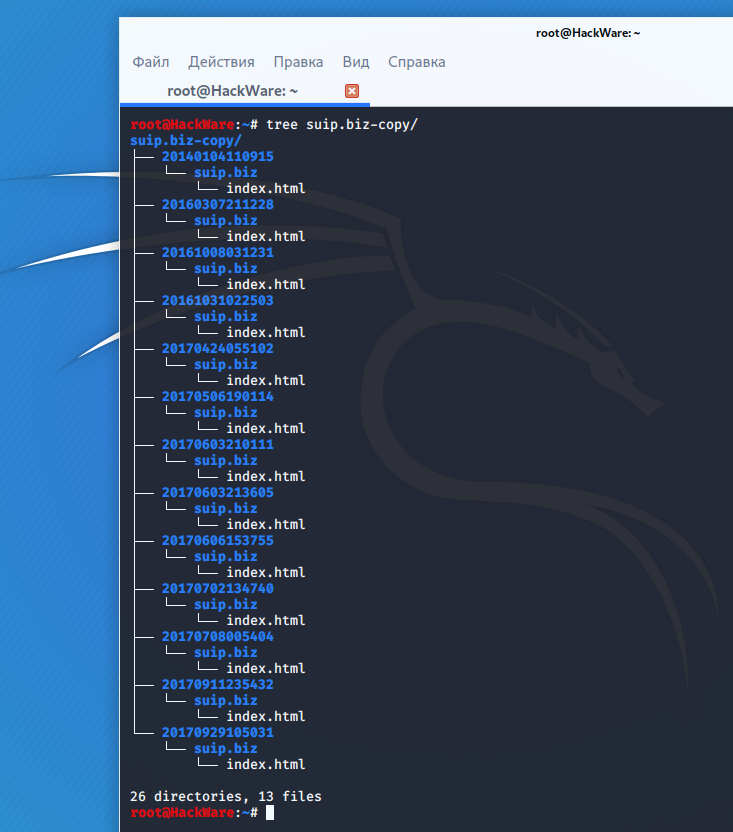
How do I bulk download?
At this time, there are two methods to do bulk downloading. Both require some comfort working in a Unix environment:
Как скачать книгу с archive org
Войти через uID
- Страница 1 из 1
- 1
На нем можно найти множество книг, которые на территории США перешли в открытый доступ, и самые интересные в контексте этого сайта — по архитектуре!
Как искать
Зайти на сайт и ввести в поле поиска нужные секретные архитектурные слова, а справа выбрать тип данных для поиска — Text, нажать Ввод (Enter): 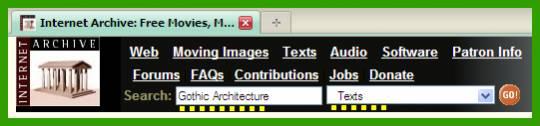
В результатах выбрать книгу, например, первую: 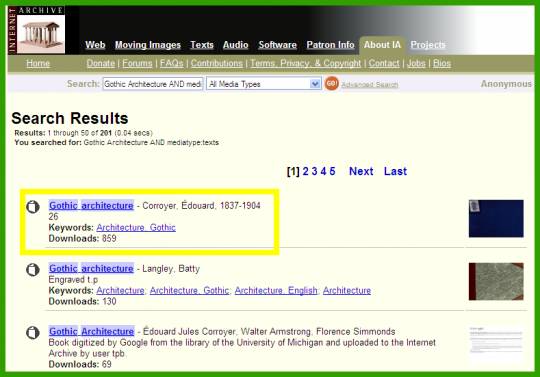
Зайти на её страницу, щелкнув по названию: 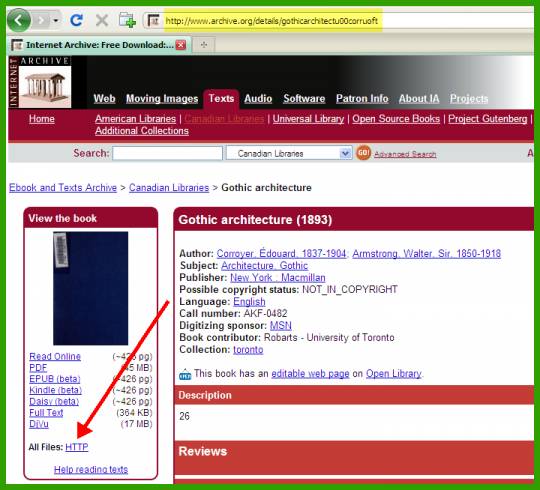
Здесь надо обратить внимание на два важных момента:
1. адрес этой страницы постоянен и помогает найти эту книгу в любое время, а последнее слово в адресе (справа от черты) является идентификатором этой книги в библиотеке.
В нашем примере это http://www.archive.org/details/gothicarchitectu00corruoft .
2. Слева внизу есть ссылка «All files: HTTP», по нему лежат файлы книги, доступные по протоколу HTTP, их можно скачивать обычными программами, от браузера до любого менеджера загрузок: 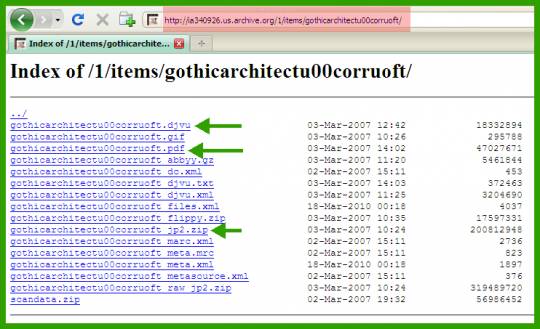
Интерес представляют обычно следующие файлы:
*.PDF — отсканированная и собранная в один файл книга
*.DJVU — то же самое, но в формате DJVU
*_JP2.zip — отсканированные и обработанные страницы книги, упакованные в архив формата ZIP. После его скачивания и извлечения файлов можно смотреть их любой программой просмотра, поддерживающей формат .JP2 (JPEG2000), или конвертировать их в любой другой формат, делать из них постеры, аватары, обои и т.п!!
Важно (1): ссылка на страницу с файлами может меняться, в отличии от ссылки на книгу.
Важно (2): во всех именах файлов, скачанных с этого сайта, присутствует идентификатор книги, например: gothicarchitectu00corruoft _jp2.zip
Поэтому перейти к странице самой книги легко: надо склеить вместе две строки:
адрес http://www.archive.org/details/ и идентификатор книги: gothicarchitectu00corruoft :
В дальнейшем можно публиковать книги с этого сайта, просто указав ссылку на её страницу и ссылку на эту инструкцию.
Как скачать книгу с archive org

- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- http://twitter.com/burgerkingfor покажет архив данного url (поиск чувствителен к регистру)
- http://twitter.com/burg* поиск архивных url начинающихся с http://twitter.com/burg
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
- http://archive.is/http://www.google.de/
- http://archive.is/www.google.de
- http://archive.is/*.google.de
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
- добавить хэштег (#) с позицией прокрутки в качество которого число между 0 (вершина страницы) и 100 (низ страницы). Например, http://archive.md/dva4n#95%
- выбрать текст на страницы и получить URL с хэштегом, указывающим на этот раздел. Например, http://archive.is/FWVL#selection-1493.0-1493.53
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
web-arhive.ru

- http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0
- http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1
Издатели добрались до Archive.org?
This program is only available to residents of the United States or American citizens living abroad
Как скачать книгу с archive org
Войти
Авторизуясь в LiveJournal с помощью стороннего сервиса вы принимаете условия Пользовательского соглашения LiveJournal
познавательная партизанщина. Ч.3. archive.org
В продолжение темы познавательной партизанщины (см. предыдущие две части: ч.1 и ч.2 ) — краткий псто о всем известном ресурсе archive.org. Замечательный и бесхитростный ресурс, но даже на нём есть пара фокусов, которые здорово облегчат «геронтобиблиофилу» работу.
#1 Книги оцифрованные google
На archive.org покоится лишь малая толика старых изданий оцифрованных гуглом, но зато их легко и приятно оттуда скачивать, не заморачиваясь с прокси-серверами и прочей унизительной лабудой. Если знать как.
Как? Всё очень просто. Открыв на архив-орг карточку нужной книги видим такое:
При нажатии на ссылку «PDF(Google.com)» происходит былинный отказ — нас просто перебрасывают на страницу книги на books.google.com, естественно закрытую для не американских IP.
Решается просто — всего лишь нажатием на ссылку «HTTP» (см. красную стрелку на картинке выше)
Наживаем, и видим вот такой список:
Красной стрелкой выделена строка с pdf-версией файла, который спокойно скачиваем щёлкнув правой кнопкой мыши, и далее, — «сохранить как..».
№2 Картинки в максимальном качестве.
Насколько я понял из своего опыта, как таковые pdf-книги на серверах huthi trust и archive.org не хранятся. Хранятся наборы графических файлов в jp2 и tiff, т.е. pdf по сути склеивается из них как-бы «налету». На archive.org этот самый пдф склеивается так, что хоть плачь, хоть смейся. Файл получается тяжелый, но при этом все изображения в нём «убиты» напрочь. Но мы-то с вами знаем, что на самом деле картинки там очень даже зер гут. Как заполучить исходные файлы с Хати траст было показано в предыдущей части. Практически то же самое, только намного удобнее и легче можно провернуть на архив-орг.
Опять же, всё совсем несложно.
Открываем книгу в режиме «reed online» (самая первая ссылка, над «download pdf»). Я лично для сбора картинок включаю режим миниатюр страниц. Видим примерно такое:
На интересующей картинке щёлкаем ПКМ, и «открыть изображение». Откроется махонькая картинка в jpeg, ровно такая же как и сама миниатюра. А теперь немножко камлаем — в частности меняем конец url-адреса картинки. В данном случае, url заканчивается на переменные «scale=26&rotate=0». Это означает что исходный файл jp2, лежащий на сервере уменьшен в 26 (!) раз. Меняем значение «scale» на о (ноль) и перезагружаем страницу. Картинка загрузится в полном исходном размере (в данном случае — ок. 750 кб и примерно 4000х2500 пикс), что очень даже неплохо. Формат правда не исходный (jp2), а jpeg, но это даже удобней, тем более что качество совершенно не отличается (единственно отличие — исходный jp2 заметно меньше весит). Кстати точно также можно менять переменную rotate (поворот), чтобы вывести «лежащие на боку» картинки с нужным поворотом (поменяв значение с нуля на 90 или 270).
Всё это наверняка все заинтересованные лица давно знают, но пускай будет, — так,»для коллекции».