8.Назначение и основы использования систем искусственного интеллекта; базы знаний, экспертные системы, искусственный интеллект.
Естественно-языковый интерфейс был наиболее привлекателен для общения с ЭВМ с момента ее появления. Это позволило бы исключить необходимость обучения конечного пользователя языку команд или другим приемам формулировки своих заданий для решения на компьютере, поскольку естественный язык является наиболее приемлемым средством общения для человека. Поэтому работы по созданию такого рода интерфейса начались с середины 20-го века. Однако, несмотря на весь энтузиазм исследователей и проектировщиков, эта задача не решена и по сей день из-за огромных сложностей, связанных с пониманием предложений естественного языка и связного текста в целом. Некоторые программные продукты, которые появлялись на рынке, носили скорее экспериментальный характер, имели множество ограничений и не решали задачу кардинально. Тем не менее, несмотря на кажущийся застой в этой сфере, данная проблема остается актуальной и по сей день и вошла в состав проблематики, связанной с проектом ЭВМ пятого поколения. База знаний.
БЗ (англ. Knowledge base, KB) — это особого рода база данных, разработанная для управления знаниями (метаданными), то есть сбором, хранением, поиском и выдачей знаний. Раздел искусственного интеллекта, изучающий базы знаний и методы работы со знаниями, называется инженерией знаний. Наиболее важный параметр БЗ — качество содержащихся знаний. Лучшие БЗ включают самую релевантную и свежую информацию, имеют совершенные системы поиска информации и тщательно продуманную структуру и формат знаний. . В зависимости от уровня сложности систем, в которых применяются базы знаний, различают:
БЗ всемирного масштаба
Применение баз знаний.
Простые базы знаний могут использоваться для хранения данных об организации: документации, руководств, статей технического обеспечения. Главная цель создания таких баз — помочь менее опытным людям найти существующее описание способа решения какой-либо проблемы предметной области. Онтология может служить для представления в базе знаний иерархии понятий и их отношений. Онтология, содержащая еще и экземпляры объектов не что иное, как база знаний. База знаний — важный компонент интеллектуальной системы. Наиболее известный класс таких программ — экспертные системы. Они предназначены для построения способа решения специализированных проблем, основываясь на записях БЗ и на пользовательском описании ситуации. Создание и использование систем искусственного интеллекта потребует огромных баз знаний.
Базы знаний в интеллектуальной системе.
Ниже перечислены интересные особенности, которые могут (но не обязаны) быть у интеллектуальной системы, и которые касаются баз знаний. Машинное обучение : Это модификация своей БЗ в процессе работы интеллектуальной системы, адаптация к проблемной области. Аналогична человеческой способности «набирать опыт».
Автоматическое доказательство (вывод): способность системы выводить новые знания из старых, находить закономерности в БЗ. Некоторые авторы считают, что БЗ отличается от базы данных наличием механизма вывода.
Интроспекция : нахождение противоречий, нестыковок в БЗ, слежение за правильной организацией БЗ.
Доказательство заключения : способность системы «объяснить» ход её рассуждений по нахождению решения, причем «по первому требованию».
Экспертная система (ЭС, expert system) — компьютерная программа, способная заменить специалиста-эксперта в решении проблемной ситуации. ЭС начали разрабатываться исследователями искусственного интеллекта в 1970 х годах, а в 1980 х получили коммерческое подкрепление. Похожие действия выполняет программа-мастер (wizard). Как правило, мастера применяются в системных программах для интерактивного общения с пользователем (например, при установке ПО). Главное отличие мастеров от ЭС — отсутствие базы знаний; все действия жестко запрограммированы. Это просто набор форм для заполнения пользователем.
Искусственный интеллект (англ. Artificial intelligence, AI) — раздел информатики, изучающий возможность обеспечения разумных рассуждений и действий с помощью вычислительных систем и иных искусственных устройств. При этом в большинстве случаев заранее неизвестен алгоритм решения задачи. Теорией явно не определено, что именно считать необходимыми и достаточными условиями достижения интеллектуальности. Хотя на этот счёт существует ряд гипотез, например, тест Тьюринга или гипотеза Ньюэлла — Саймона. Обычно к реализации интеллектуальных систем подходят именно с точки зрения моделирования человеческой интеллектуальности. Таким образом, в рамках искусственного интеллекта различают два основных направления:
символьное (семиотическое, нисходящее) основано на моделировании высокоуровневых процессов мышления человека, на представлении и использовании знаний;
нейрокибернетическое (нейросетевое, восходящее) основано на моделировании отдельных низкоуровневых структур мозга (нейронов).
Таким образом, сверхзадачей искусственного интеллекта является построение компьютерной интеллектуальной системы, которая обладала бы уровнем эффективности решений неформализованных задач, сравнимым с человеческим или превосходящим его. В качестве критерия и конструктивного определения интеллектуальности предложен мысленный эксперимент, известный как тест Тьюринга. В современной постановке можно рассматривать эту задачу как задачу приближения сингулярности в её сверхинтеллектуальном понимании. На данный момент не существует систем искусственного интеллекта, однозначно отвечающих основным задачам, обозначенным выше. Успехи в исследовании аналоговых и обратимых вычислений позволят совершить большой шаг вперёд в построении систем искусственного интеллекта. Наиболее часто используемые при построении систем искусственного интеллекта парадигмы программирования — функциональное программирование и логическое программирование. От традиционных структурного и объектно-ориентированного подходов к разработке программной логики они отличаются нелинейным выводом решений и низкоуровневыми средствами поддержки анализа и синтеза структур данных.
Почему при разработке ИИ главное — это данные

Системы машинного обучения рождаются от союза кода и данных. Код сообщает, как машина должна учиться, а данные обучения включают в себя то, чему нужно учиться. Научные круги в основном занимаются способами улучшения алгоритмов обучения. Однако когда дело доходит до создания практических систем ИИ, набор данных, на котором выполняется обучение, по крайней мере столь же важен для точности, как и выбор алгоритма.
Существует множество инструментов для улучшения моделей машинного обучения, однако чрезвычайно мало способов улучшения набора данных. Наша компания много размышляет над тем, как можно систематически улучшать наборы данных для машинного обучения.
Совершенствование набора данных может значительно повысить точность ИИ
В своём недавнем докладе Эндрю Ын рассказал историю о проекте, над которым он работал в Landing AI, создавая систему компьютерного зрения для поиска дефектов в стали. Их первая попытка реализации системы имела точность 76%. Люди способны обнаруживать дефекты с точностью 90%, поэтому система была недостаточно хороша для запуска в продакшен. После этого работавшая над проектом команда разделилась на две части. Одна команда работала над проверкой различных типов моделей, гиперпараметров и изменений архитектуры. Вторая стремилась повысить качество набора данных. Спустя несколько недель итераций появились результаты. Несмотря на огромные усилия, занимавшаяся моделями команда никак не смогла повысить точность. С другой стороны, улучшавшая данные команда смогла получить рост точности на 16%. Улучшение набора данных для этой задачи позволило превысить результаты человека.
И эта история не уникальна. У меня был подобный опыт в Humanloop. Мы работали с командой юристов из крупной бухгалтерской фирмы над обучением классификатора документов по юридическим договорам. Как и поиск дефектов в стали, эта задача требовала опыта в данной сфере. После завершения первого раунда разметки и обучения модель всё ещё не дотягивала до уровня показателей человека. У Humanloop есть инструмент для изучения примеров данных, в которых расходятся мнения модели ИИ и живых аннотаторов. Благодаря этому инструменту команде удалось найти примерно 30 случаев ошибочной классификации в наборе данных из 1000 документов. Устранения этих 30 ошибок было достаточно для того, чтобы система ИИ достигла уровня человека.
Как выглядят «баги в данных»?
Сейчас активно обсуждают «подготовку данных» и «очистку данных», но что отличает высококачественные данные от низкокачественных?
В большинстве систем машинного обучения сегодня применяется контролируемое обучение. Это значит, что данные обучения состоят их пар (input, output), и мы хотим, чтобы система могла получать входные данные и сопоставлять их с выходными. Например, входными данными может быть аудиоклип, а выходными — транскрипция речи. Или входными данными может быть фотография повреждённого автомобиля, а выходными — места всех царапин. Humanloop в основном занимается NLP, поэтому примером входных данных для нас может быть сообщение в службу поддержки клиентов, а выходными — шаблон ответа. Для создания таких наборов данных обучения обычно требуется, чтобы человек вручную размечал входные данные, по которым должен обучаться компьютер.
Если в разметке данных присутствует неопределённость, то для достижения высокой точности модели машинного обучения может понадобиться больше данных. Сбор и аннотирование данных могут оказаться неправильными по многим причинам:
-
Простые ошибки аннотирования. Простейший тип ошибки — это неправильное аннотирование. Аннотатор, уставший от большого количества разметки, случайно помещает пример данных не в тот класс. Хоть это и простая ошибка, она встречается на удивление часто, и может иметь огромное отрицательное влияние на производительность системы ИИ. Недавнее изучение наборов данных для бенчмарков в исследованиях компьютерного зрения выявило, что более 3% от всех данных было размечено ошибочно. Более 6% проверочного набора данных Imagenet размечено ошибочно. Как можно ожидать высокой производительности, если данные в бенчмарках неверны?

Например, система распознавания лиц ИИ Google была печально известна тем, что плохо распознавала лица цветных людей, что в большой степени было результатом использования набора данных с недостаточно разнообразными примерами (среди множества прочих проблем).
Ещё важнее качество данных для небольших наборов данных
У большинства компаний и исследовательских групп нет доступа к масштабным наборам данных, которые имеются у Google, Facebook и других технологических гигантов. Когда набор данных настолько велик, можно закрыть глаза на небольшой шум в данных. Однако большинство команд работает в областях, где существуют только сотни или тысячи размеченных примеров. В этой сфере с малым объёмом данных качество этих данных становится ещё более важным.
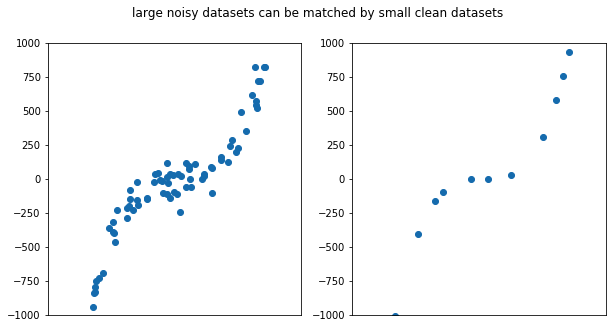
Чтобы получить некоторое понимание того, почему качество данных настолько важно, рассмотрим описанную выше очень простую одномерную задачу контролируемого обучения. В этом случае мы пытаемся подстроить кривую под некие измеренные точки данных. Слева мы видим большой шумный набор данных, а справа — небольшой чистый набор. Вполне очевидно, что небольшое число точек данных с очень низким шумом демонстрирует ту же кривую, что и большой, но шумный набор данных. Из этого можно сделать вывод о том, что шум в небольших наборах данных особенно вреден. Хотя большинство задач машинного обучения имеют высокую размерность, они работают на тех же принципах, что и приближение кривой, и подвержены аналогичным проблемам.
Разумный подбор инструментов может сильно влиять на повышение качества данных
Существует множество инструментов для улучшения моделей машинного обучения, но как можно систематически совершенствовать наборы данных для машинного обучения?
Инструменты очистки данных
В некоторых командах начинают применять следующий рабочий процесс: итерации между обучением моделей и исправлением «багов данных». Появляются инструменты, упрощающие этот процесс, например, шум меток в контексте и аквариумное обучение, или отладчик данных Humanloop.
Эти инструменты работают следующим образом: они используют обучаемую модель, чтобы находить «баги данных». Это можно реализовать изучением областей, в которых возникают сильные противоречия между моделью и человеком, или классов, где есть сильные противоречия между разными аннотаторами. Различные способы визуализации помогают находить кластеры ошибок и устранять их одновременно.
Частичная разметка
Ещё один подход к улучшению наборов данных заключается в том, чтобы учитывать наличие шума, но использовать эвристические правила для увеличения масштабов аннотирования.
Как мы видим из показанного выше примера, можно получить хорошие результаты или на очень маленьких, но чистых наборах данных, или на очень больших, но шумных наборах. Идея частичной разметки заключается в автоматической генерации очень большого количества шумных меток. Эти метки генерируются благодаря тому, что специалисты в соответствующей области создают эвристические правила.
Например, может существовать такое правило для классификатора электронных писем: «пометить письмо как резюме по работе, если в нём содержится слово „cv“. Это правило будет не очень надёжным, но его можно автоматически применить к тысячам или миллионам примеров.
Если таких правил много, то их метки можно скомбинировать и очистить от шума, чтобы создать высококачественные данные.
Активное обучение
Инструменты очистки данных всё равно используют труд человека по ручному поиску ошибок в наборах данных и не помогают справляться с описанными выше проблемами дисбаланса классов. Активное обучение — это методика, обучающая модель в процессе того, как команда аннотирует данные и использует эту модель для поиска самых ценных данных. Активное обучение может автоматически улучшать баланс наборов данных и помогать командам создавать модели с высокой производительностью при значительно меньшем количестве данных.
Использование принципа „главное — это данные“ повышает степень взаимодействия команд
Как мы писали недавно, одним из серьёзных преимуществ использования принципа „главное — это данные“ в машинном обучении является то, что он обеспечивает гораздо более тесное взаимодействие различных команд. Улучшение наборов данных усиливает взаимодействие между аннотирующими данные специалистами в области и дата-саентистами, которые думают о том, как обучать модели.
Базы данных и СУБД. Базы знаний и системы искусственного интеллекта
Прикладное программное обеспечение: свойства, классификация и функции. Система управления базами данных: структура, поддержка языков. История развития систем искусственного интеллекта, его отличия от обычных программ и основные темы исследований.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | курсовая работа |
| Язык | русский |
| Дата добавления | 14.04.2009 |
| Размер файла | 382,0 K |
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Федеральное агентство по образованию
Государственное Образовательное учреждение
Высшего профессионального образования
«Братский Государственный Университет»
Курсовая работа
Базы данных и СУБД.
Базы знаний и системы искусственного интеллекта
Студентка группы ЭКО-07
Введение
Наше время трудно представить жизнь и работы средних и крупных предприятий без информационных систем, а в основу информационных систем входит базы данных и конечно система управления ими.
В данной курсовой работе были рассмотрены темы:
· База данных — дано определение БД и их сущность;
· Система управления базами данных — представлены функции, структура и основные характеристики СУБД;
· Модели данных — представлено три модели данных, описано их различие, сходство и для каких целей они предназначены.
По своей сути процессы адаптации являются оптимизационными процессами.
Дж. Холланд, Adaptation in natural and artificial systems.
На сегодняшний день ученые достигли большого прогресса в области разработки искусственного интеллекта. Но они не могут достичь совершенного «электронного мозга», который мог бы работать как человеческий.
Во второй главе рассматривается история развития искусственного интеллекта, и дано значение баз знаний. Показано, чем БД отличается от БЗ.
Так же приведены модели представления знаний, при помощи которых строятся экспертные системы.
1. Прикладное программное обеспечение
1.1 Введение в программное обеспечение
Программа ? это предписание, указывающее, какие операции, над какими данными и в каком порядке ЭВМ должна выполнить.
Можно сформулировать и так: программа ? это полная и подробная последовательность инструкций на понятном ЭВМ языке, предписывающая, как нужно обрабатывать данные.
Т.к. ЭВМ является универсальным устройством, то ей для работы нужна не одна, а множество различных программ ? программное обеспечение ЭВМ.
Программное обеспечение (ПО) ? это совокупность программ и сопровождающих их документов, предназначенных для эксплуатации систем обработки данных средствами вычислительной техники.
Программное обеспечение в совокупности с аппаратными (техническими) средствами составляют вычислительную систему.
Свойства ПО
· ПО обеспечивает «полезность» вычислительной системы для пользователя;
· ПО обеспечивает универсальность вычислительной системы;
· ПО является посредником между аппаратными средствами и пользователем;
· ПО более гибкая, изменчивая компонента вычислительной системы по сравнению с аппаратными средствами (см. английское название компонентов: hardware ? твердый, жесткий ресурс; software ? мягкий, гибкий ресурс), т.е. при изменении задачи пользователя или аппаратной части вычислительной системы именно ПО выступает как основное средство их адаптации.
Классификация ПО
По классификации ПО делиться на:
1. Системное ПО ? предназначено для эксплуатации и технического обслуживания ЭВМ, для организации вычислительного процесса.
2. Прикладное ПО ? предназначено для решения задач пользователя в конкретной предметной области (от развлекательных игр и творческих задач до сложных научных и производственных проблем).
3. Инструментальное ПО ? предназначено для автоматизации разработки и отладки новых программ.
Полная классификация с подклассами показана на рис.1.
Рис.1. Классификация ПО
ПО ЭВМ функционирует на нескольких связанных между собой уровнях, образуя иерархию ПО, в которой каждый последующий уровень базируется на ПО предшествующих уровней и расширяет функции вычислительной системы показанные рис.2.
Рис.2.
Самый низкий уровень в иерархии ПО занимает базовое ПО ? BIOS (Basic Input/Output System) ? базовая система ввода-вывода. BIOS предназначена для управления базовыми аппаратными компонентами, установленными на материнской плате. Фактически BIOS является неотъемлемой частью ПЗУ и поэтому может быть отнесена к особой категории компьютерных компонентов, занимая промежуточное место между аппаратными средствами и ПО.
2. Прикладное программное обеспечение
Управление данными во внешней памяти включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в базу данных, так и для служебных целей, например, для ускорения доступа к данным.
2.1 Основная функция ПО
Основной функцией прикладного программного обеспечения является выполнение задач, поставленных конечными пользователями. Для разработки прикладного ПО может быть использовано множество языков программирования. Каждый из этих языков имеет свои сильные и слабые стороны.
Управление буферами оперативной памяти СУБД, как правило, работают с БД большого объема. По крайней мере, объем базы данных существенно превышает объем оперативной памяти. Так что, если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти.
Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти. При этом, даже если операционная система производит общесистемную буферизацию, этого недостаточно для целей СУБД, которая располагает большей информацией о полезности буферизации той или иной части БД. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной их замены.
2.2 Управление транзакциями
2.2 Управление транзакциями
Транзакция — это последовательность операций над БД, рассматриваемых СУБД как единое целое. Транзакция либо успешно выполняется, и СУБД фиксирует произведенные изменения данных во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД, поэтому поддержание механизма транзакций является обязательным условием как однопользовательских, так и многопользовательских СУБД.
2.3 Журнализация и восстановление БД после сбоя
Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее целостное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера, например, аварийное выключение питания, и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. В любом из описанных случаев для восстановления БД нужно располагать некоторой избыточной информацией. Наиболее распространенным методом формирования и поддержания избыточной информации является ведение журнала изменений БД.
Журнал — это специальная служебная часть БД, недоступная пользователям, в которую поступают записи обо всех изменениях основной части БД. В виду особой важности этой информации для восстановления целостности базы данных после сбоев, важно обеспечить сверхнадежное её хранение. В некоторых СУБД поддерживаются две копии журнала, располагаемые на разных физических дисках. В разных СУБД изменения БД фиксируются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД, например, удаление строки из таблицы реляционной БД, иногда — минимальной внутренней операции модификации страницы внешней памяти, а иногда одновременно используются оба подхода. Во всех случаях придерживаются стратегии упреждающей записи в журнал. То есть, запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Если в СУБД корректно соблюдается это условие, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя.
При мягком сбое во внешней памяти основной части БД могут находиться объекты, модифицированные транзакциями, не закончившимися к моменту сбоя, и могут отсутствовать объекты, модифицированные транзакциями, которые к моменту сбоя успешно завершились из-за использования буферов оперативной памяти, содержимое которых в этой ситуации пропадает. При соблюдении стратегии упреждающей записи, во внешней памяти журнала должна находиться информация, относящаяся к операциям модификации обоих видов объектов. Целью процесса восстановления после мягкого сбоя является состояние внешней памяти основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и которое не содержало бы никаких следов незаконченных транзакций. Для того чтобы этого добиться, сначала производят откат незавершенных транзакций, а потом повторно воспроизводят те операции завершенных транзакций, результаты которых не отображены во внешней памяти.
Для восстановления БД после жесткого сбоя используют журнал и архивную копию БД. Архивная копия является полной копией БД к моменту начала заполнения журнала. Восстановление БД состоит в том, что, исходя из архивной копии, по журналу воспроизводится работа всех транзакций, которые закончились к моменту сбоя.
2.4 Поддержка языков БД
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка — язык определения схемы БД (SDL — Schema Definition Language) и язык манипулирования данными (DML — Data Manipulation Language). SDL служил, главным образом, для определения логической структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, позволяющих вводить, удалять, модифицировать и выбирать данные. В современных СУБД, обычно, поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД и обеспечивающий базовый пользовательский интерфейс. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language).
Язык SQL содержит специальные средства определения ограничений целостности БД. Ограничения целостности хранятся в специальных таблицах-каталогах. Обеспечение контроля целостности производится на языковом уровне. При компиляции операторов модификации БД, компилятор SQL, на основании имеющихся ограничений целостности, генерирует соответствующий программный код.
Специальные операторы языка SQL позволяют определять так называемые представления БД, фактически являющиеся хранимыми запросами. Для пользователя представление является такой же таблицей, как любая базовая таблица, хранимая в БД, но с его помощью можно ограничить или расширить видимость БД для конкретного пользователя. Поддержание представлений производится также на языковом уровне.
Наконец, авторизация доступа к объектам БД производится на основе специального набора операторов SQL. Идея состоит в том, что для выполнения операторов SQL разного вида пользователь должен обладать различными полномочиями. Пользователь, создавший таблицу БД, обладает полным набором полномочий для работы с этой таблицей. В число таких полномочий входит право на передачу всех или части полномочий другим пользователям, включая полномочие на передачу полномочий. Полномочия пользователей описываются в специальных таблицах-каталогах, а контроль полномочий поддерживается на языковом уровне.
В типовой структуре современной реляционной СУБД логически можно выделить ядро СУБД, компилятор языка БД, подсистему поддержки времени выполнения и набор утилит.
2.5 Ядро СУБД
Ядро СУБД отвечает за управление данными во внешней памяти, управление буферами оперативной памяти, управление транзакциями и журнализацию. Соответственно, можно выделить такие компоненты ядра как менеджер данных, менеджер буферов, менеджер транзакций и менеджер журнала. Ядро обладает собственным интерфейсом, недоступным пользователям, и является основной резидентной частью СУБД. При использовании архитектуры «клиент-сервер» ядро является основной составляющей серверной части системы.
Производительность СУБД оценивается:
1. временем выполнения запросов;
2. скоростью поиска информации в неиндексированных полях;
3. временем выполнения операций импортирования базы данных из других форматов;
4. скоростью создания индексов и выполнения таких массовых операций, как обновление, вставка, удаление данных;
5. максимальным числом параллельных обращений к данным в многопользовательском режиме;
БАЗЫ ЗНАНИЙ В ИСКУССТВЕННОМ ИНТЕЛЛЕКТЕ
Ни для кого не секрет, что информационные технологии прочно вошли в современную жизнь. На сегодняшний день почти у каждого есть смартфон, ноутбук, планшетный компьютер и ещѐ множество других гаджетов, способных принести в нашу жизнь что-то новое или каким-то способом облегчить ее.
Сейчас в каждой отрасли нашей жизни используются современные технологии, которые основаны на информационных технологиях или в них есть подобие искусственного интеллекта.
Иску́ сственный инте лле́кт (ИИ, англ. Artificial intelligence, AI) — 1) наука и технология создания интеллектуальных машин, особенно интеллектуальных компьютерных программ; 2) свойство интеллектуальных систем выполнять творческие функции, которые традиционно считаются прерогативой человека.[1]
В современном мире многие считают, что искусственный интеллект – это робот, но это не так. Несомненно робот, в представлении человека, — это механическое устройство, созданное человеком для облегчения собственной жизни. Например, современное популярное устройство –« робот-пылесос», позволяет пропылесосить полы в квартире почти без помощи человека. Ему достаточно только включить устройство и оно начнет работать, при помощи колесиков передвигаться по квартире, а при помощи определенных датчиков определяет необходимость повернуть или остановиться совсем.
Но все современные устройства далеки от идеала, все они в какой – то степени используют искусственный интеллект. Но в мечтах ученых создать полноценный искусственный интеллект. Под эти ученые подразумевают искусственно созданное устройство, которое сможет не только запоминать какие-то факты, но и распознавать эмоции и чувства, а в идеале еще и проявлять их самому.
Любое искусственное существо с интеллектом должно обладать памятью. Процесс обучения точно такой же как с маленькими детьми, если ребенок один раз обжегся о горячую плиту, то у него в памяти отложилось, что плита горячая и подходить к ней, а тем более трогать ее опасно. Точно так должен обучаться искусственный мозг, один раз запомнив, например, ход в шахматах он должен в следующий раз его повторить не задумываясь.
У человека для этого существует память и нейронный связи, для искусственного интеллекта существует База знаний.
База знаний – это особого рода база данных, разработанная для оперирования знаниями (метаданными). База знаний содержит структурированную информацию, покрывающую некоторую область знаний, для использования кибернетическим устройством (или человеком) с конкретной целью. Современные базы знаний работают совместно с системами поиска информации, имеют классификационную структуру и формат представления знаний.
Полноценные базы знаний содержат в себе не только фактическую информацию, но и правила вывода, допускающие автоматические умозаключения о вновь вводимых фактах и, как следствие, осмысленную обработку информации. Область наук об искусственном интеллекте, изучающая базы знаний и методы работы со знаниями, называется инженерией знаний.[3]
Иерархический способ представления в базе знаний набора понятий и их отношений называется онтологией. Онтологию некоторой области знаний вместе со сведениями о свойствах конкретных объектов также можно назвать базой знаний.[2]
Системы искусственного интеллекта работают на основе заложенных в них баз знаний. Это та модель которая заложена программистом или создателем в компьютер.
Для человека характерно не только запоминание некоторых фактов, но и рассуждение о них, а также анализирование, на основе чего создавать логические рассуждения.
В системах с искусственны интеллектом на данный момент реализована модель рассуждений (человеческой логики). На основе базы знаний и модели рассуждений система искусственного интеллекта сама программирует свою работу при решении любой задачи.
Существуют два типа методов представления знаний:
1. Формальные модели представления знаний;
2. Неформальные (семантические, реляционные) модели представления знаний.
Очевидно, все методы представления знаний, которые приведены выше, включая продукции (это система правил, на которых основана продукционная модель представления знаний), относятся к неформальным моделям. В отличие от формальных моделей, в основе которых лежит строгая математическая теория, неформальные модели такой теории не придерживаются. Каждая неформальная модель годится только для конкретной предметной области и поэтому не обладает универсальностью, которая присуща моделям формальным. Логический вывод — основная операция в СИИ — в формальных системах строг и корректен, поскольку подчинен жестким аксиоматическим правилам. Вывод в неформальных системах во многом определяется самим исследователем, который и отвечает за его корректность.[2]
Каждому из методов представления знаний соответствует свой способ описания знаний.
1. Логические модели Основная идея подхода при построении логических моделей представления знаний — вся информация, необходимая для решения прикладных задач, рассматривается как совокупность фактов и утверждений, которые представляются как формулы в некоторой логике. Знания отображаются совокупностью таких формул, а получение новых знаний сводится к реализации процедур логического вывода. В основе логических моделей представления знаний лежит понятие формальной теории, задаваемое кортежем:
1. Бахтин М. М., 1975. Вопросы литературы и эстетики: Исследования разных лет. М.: Художественная литература.
2. Гаврилова Т.А., Хорошевский В.Ф., 2000. Бзы знаний интеллектуальных систем. Издательство: Питер