Функция Ord
Функция Ord в Паскале возвращает порядковый номер значения порядкового типа (далее на примерах это будет разъяснено более внятно). Синтаксис:
function Ord(X : TOrdinal) : LongInt;
Здесь Х — значение любого порядкового типа. Функция возвращает порядковый номер значения порядкового типа, переданного через параметр Х.
Изначально Паскаль не имел функций преобразования типов и функция Ord была необходима для того, чтобы выполнять некоторые операции с не целочисленными порядковыми типами (такими, как тип Char). С введением универсального подхода к преобразованию типов стало возможным отказаться от использования функции Ord. Однако она не считается устаревшей и до сих пор широко используется.
Чаще всего эту функцию используют для того, чтобы узнать код символа (об этом ниже). Однако её также можно использовать с любыми порядковыми типами — как с простыми целыми числами (хотя в этом нет особого смысла), так и, например, с перечислениями.
Как узнать код символа
Как известно, любой символ имеет свой код. Потому что компьютеры не понимают ни слов, ни символов. Они понимают только числа. Поэтому каждому символу присвоен определённый код.
Различных кодировок существует довольно много. Самая простая и одна из самых первых — это ASCII.
В разной справочной литературе и в книгах по программированию вы можете найти таблицы ASCII-кодов. Но в Паскале можно узнать ASCII-код любого символа и без этих таблиц (к тому же в разных операционных системах эти таблицы могут отличаться для русского языка), просто воспользовавшись функцией Ord. Например, так:
Здесь в переменную Cod мы получаем ASCII-код английской буквы Z.
В этой программе с помощью функции Ord мы сначала получаем код (номер) числа 200. Разумеется, это и будет число 200.
Затем мы получаем ASCII-код символа Z (английская большая буква Z). В кодировке символов ASCII код символа Z — Это число 90.
А затем мы получаем порядковый номер элемента Summer в перечислении TSeasons. Элемент Summer у нас находится на третьей позиции. Однако в перечислениях отсчёт начинается с 0, поэтому функция Ord вернёт число 2.
Строки: таблица символов ASCII и её использование
В этой статье мы детально рассмотрим таблицу символов ASCII и как ее можно использовать. Также мы рассмотрим несколько новых функций, принцип работы которых основан на специфике строения таблицы ASCII, и в конце создадим новую библиотеку, в которую включим эти функции. Они достаточно популярны в других языках программирования, но их нет среди встроенных функций языка MQL4. Кроме того, мы очень детально разберем основы работы со строками, так что, я думаю, вы обязательно узнаете что-нибудь новое про этот полезный тип данных.
Что такое ASCII ?
ASCII — Американский стандарт кодирования для передачи информации (American Standard Code for Information Interchange). Этот стандарт основан на английском алфавите. Коды ASCII представляют текст в компьютерах, коммуникационном оборудовании и других устройствах, которые работают с текстом. ASCII был создан в 1963 году, но впервые опубликован как стандарт в 1967 году. Последние изменения были внесены в 1986 году. Более детальную информацию про ASCII вы можете почитать здесь: https://en.wikipedia.org/wiki/ASCII. Далее мы рассмотрим как можно полностью вывести ASCII средствами MQL4, но для начала давайте рассмотрим основы работы со строками.
Основы построения библиотеки
Чтобы написать подобную библиотеку, нужно разобраться в некоторых моментах, которые нам жизненно необходимы. Для начала давайте определимся, как можно «пройтись» по всем символам строки подобно процедурам с массивами данных. Подобный кусок кода будет всегда повторяться в любой функции, которая предназначена для посимвольной обработки. Для примера напишем простой скрипт, который выводит сначала обычную строку, а потом обработанную, в которой каждый символ разделяет пробел.
Разберем значение каждой строки отдельно.
Определяем три переменные типа string:
- s1 — начальная строка, которую мы хотим обработать;
- s2 — строка, в которую будет выведен результат;
- symbol — строка, которая используется для временного хранения каждого символа.
Обратите внимание на то, что она инициализируется одним символом. Если этого не сделать, то в результате получим строку, в которой нет первого символа. Дело в том, что стандартная функция языка MQL4 StringSetChar() изменяет уже созданные символы, поэтому требуется хотя бы один символ для нормальной работы.
Определяем переменную целого типа для хранения длины строки. Для этого сразу же вызываем стандартную функцию для определения длины строки StringLen(), которая имеет единственный параметр — строку, длину которой требуется узнать.
Выводим строку до обработки.
Определяем цикл, в котором будет производиться посимвольная обработка. Обратите внимание, что счетчик инициализируется нулем, так как символы в строке индексируются с нуля, так же как и в массивах. В условии выполнения цикла используется оператор сравнения «меньше», так как последний символ имеет позицию lenght — 1.
В этой строке используется две стандартные функции: StringSetChar() и StringGetChar(). Первая позволяет заменить один из символов строки, а вторая получить код символа в указанной позиции. Функция StringSetChar() имеет три параметра:
- строку, в которой требуется произвести замену символа;
- позиция символа, который следует заменить (помните, что символы индексируются с нуля, как в массивах);
- код символа, которым следует произвести замену.
Функция возвращает результат в виде уже измененной строки. Еще одна важная функция — StringGetChar. Она имеет два параметра:
- строку, в которой содержится символ, код которого нужно узнать;
- позиция символа, код которого следует узнать.
Функция возвращает код символа. Так как функция StringGetChar возвращает код символа, то я разместил ее вызов на месте параметра функции StringSetChar. Таким образом с помощью этой строки мы запоминаем текущий символ для дальнейшей обработки. В ходе выполнения всего цикла этой переменной будет по очереди присвоен каждый символ строки s1.
Мы можем без проблем связывать строки (конкатенация) с помощью операций сложения (+). Здесь при каждой итерации цикла мы добавляем к результирующей строке очередной символ и пробел.
Выводим результат. Обратите внимание, что мы считываем каждый символ, начиная с первого, но можно поступить и наоборот. В таком случае получим меньше кода и переменных. Если при обработке строки для вас не имеет значения, с какой стороны начинать, то используйте следующий вариант:
Как видно, теперь вместо цикла for используется while, что позволяет избавиться от счетчика x. Для этих целей используется переменная lenght. В дальнейшем мы будем использовать один из этих двух шаблонов для написания функций в зависимости от того, имеет ли значение, в какой последовательности производить обработку. В нашем случае получим строку, в которой символы переставлены наоборот, то есть здесь последовательность обработки имеет большое значение.
Выводим все символы ASCII
Скрипт использует встроенные функции MQL4, а также строковые константы новой строки и табуляции для наглядного представления таблицы. Теперь скомпилируйте и запустите его. Вы должны увидеть таблицу символов ASCII:
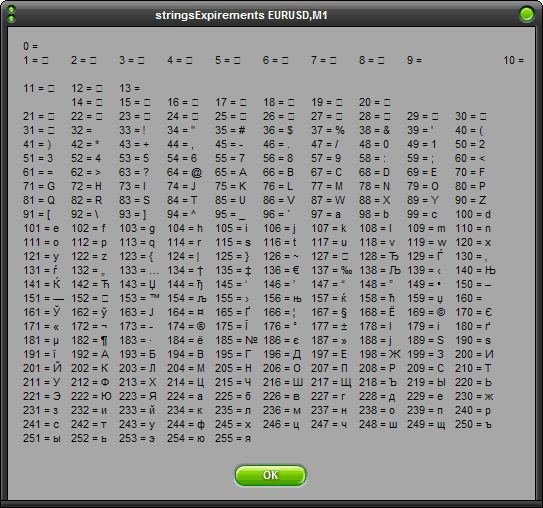
Рассмотрите ее повнимательнее. Вы заметите абсолютно все символы, которые только могут понадобиться, от цифр и букв до специальных символов, некоторые из которых вы наверняка увидите впервые. Сначала идет код, а потом после знака » text-align:center;»> 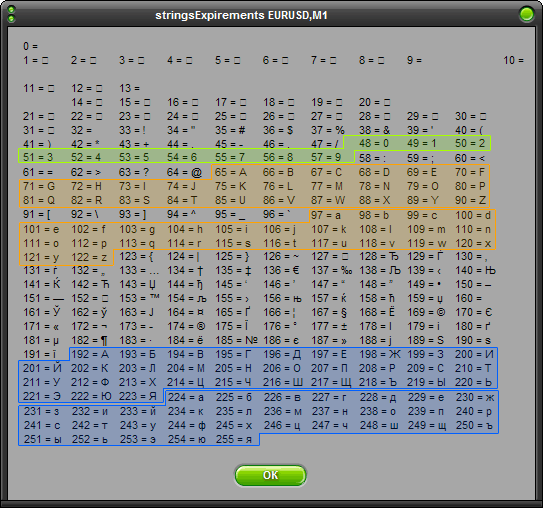
Обратите внимание на расположение букв. Они расположены в алфавитном порядке. Эту особенность мы скоро используем для написания некоторых функций, например, для перевода букв строки из верхнего регистра в нижний и наоборот. А теперь давайте займемся новыми функциями и в конце на их основе создадим библиотеку.
StringUpperCase и StringLowerCase
Это две очень популярные функции для перевода строки в верхний или нижний регистр. Их реализация основана на том факте, что все коды символов букв верхнего регистра на 32 больше букв нижнего регистра. Это можно увидеть, если смотреть по таблице, что мы получили. На практике, если попробовать узнать коды символов ‘А’,’Я’,’а’, ‘я’, например, с помощью такого кода
то получим результаты: А = 192, Я = 223, а = 224 и я = 255 соответственно. Поэтому следует учесть и эту особенность. Рассмотрим исходный код функций:
Так как последовательность обработки не имеет никакого значения, используем цикл while. Применять функции очень просто, единственный параметр — строка которую следует привести к нужному регистру:
StringCompare
В MQL4 сравнение строк реализовано на уровне операторов с помощью «==». Интересно, что сравнение является регистрозависимым, то есть строки «STRING» и «string» — разные:
Если нужно сравнить две строки без учета регистра, воспользуйтесь функцией StringCompare. Она возвращает значения типа bool аналогично оператору сравнения. Сама реализация крайне проста. Сравниваются строки, которые до этого приведены к нижнему регистру:
StringIsDigit
Эта функция проверяет содержимое строки. Если строка состоит только из цифр, то возвращает true, иначе false. Реализация довольно проста и основана на том, что символы цифр расположены в ряд и имеют коды от 48 до 58.
StringIsAlpha
Эта функция позволяет определить подобно предыдущей, состоит ли строка только из букв. Ее реализация аналогична:
Создание библиотеки
Теперь давайте соберем все эти функции в одну библиотеку. Для этого в редакторе MetaEditor 4 кликаем File->New->Library->Далее. В поле name пишем stringProcess и нажимаем на кнопку Готово. Потом вставляем код всех функций, приведенных выше, затем сохраняем. Осталось создать файл с прототипами функций, для этого File->New->Include(*. MQH)->Далее. В поле name пишем stringProcess, -> Готово. Теперь нужно вставить прототипы всех новых функций, а также указать директиву для импорта:
Использование библиотеки stringProcess
Для использования библиотеки следует подключить заголовочный файл с прототипами функций, после чего можно вызывать необходимые функции. Ниже приведен пример использование в скрипте:
Заключение
Итак, вы узнали что такое таблица символов ASCII и каким образом можно использовать особенности ее строения для реализации новых функций. Вы написали новые функции, которые являются довольно популярными в других языках программирования, но которых нет в MQL4. На основе их вы создали небольшую библиотеку для обработки строк. Я думаю, что эта библиотека будет использоваться не при самой торговле, но при выводе результатов. Например, если вы занимаетесь разработкой собственной системы отчетов для своего эксперта, то некоторые функции будут довольно полезными. Кроме того, наверняка найдется много областей применения, о которых я не подозреваю. Удачи вам и профитов.
String.prototype.charCodeAt()
Метод charCodeAt() возвращает числовое значение Юникода для символа по указанному индексу (за исключением кодовых точек Юникода, больших 0x10000).
Синтаксис
Параметры
Целое число больше, либо равное 0 и меньше длины строки; если параметр не является числом, он устанавливается в 0.
Описание
Кодовые точки Юникода простираются в диапазоне от 0 до 1114111 (0x10FFFF). Первые 128 кодовых точек Юникода напрямую отображаются в кодировку ASCII. Информацию по Юникоду смотрите в Руководстве по JavaScript.
Обратите внимание, что метод charCodeAt() всегда возвращает значение, меньшее 65536. Так происходит потому, что большие кодовые точки представляются парой (меньших значений) «суррогатных» псевдо-символов, которые используются для составления настоящего символа. Поэтому для того, чтобы получить полный символ для значений символов от 65536 и выше, необходимо получить не только значение charCodeAt(i) , но также значение charCodeAt(i + 1) (как если бы строка состояла из двух букв). Смотрите второй и третий примеры ниже.
Метод charCodeAt() возвращает NaN , если указанный индекс меньше нуля или больше длины строки.
Обратная совместимость: в более старых версиях (например, в JavaScript 1.2) метод charCodeAt() возвращал число из кодировки ISO-Latin-1 по указанному индексу. Диапазон символов в кодировке ISO-Latin-1 простирается от 0 до 255. Первые 127 чисел напрямую отображаются в кодировку ASCII.
Примеры
Пример: использование метода charCodeAt()
В следующем примере возвращается число 65, значение Unicode для латинского символа «A».
Пример: исправление метода charCodeAt() для обработки символов не в Базовой многоязыковой плоскости, если их предыдущее присутствие в строке неизвестно
Эта версия может использоваться в циклах for, даже когда неизвестно, были ли до указанной позиции символы из не-БМП.
Name already in use
course-site-python3 / content.old / 2015-2016 / lab2.rst
- Go to file T
- Go to line L
- Copy path
- Copy permalink
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents
Copy raw contents
Copy raw contents
Введение в Python 3
| Date: | 2015-09-10 14:23 |
|---|---|
| lecture_link: | https://youtu.be/KnFrdzG79ak |
| lecture_pdf: | true |
| test_comment: | Регистрация на контрольную №2 |
| test_link: | http://judge2.vdi.mipt.ru/cgi-bin/new-register?contest_id=540102 |
| show_solutions: | yes |
| Status: | draft |
Данный курс будет посвящен изучению программирования с использованием языка Python. Это — современный язык программирования, работающий на всех распространных операционных системах.
В настоящее время существует две версии языка Python: более старая, но пока ещё более распространненая версия 2 и современная версия 3. Они не вполне совместимы друг с другом: программа, написанная для одной версии языка может оказаться невыполнимой для другой версии. Но в основном обе версии очень похожи.
Мы будем использовать версию 3 данного языка, некоторые из используемых примеров не будут работать с версией 2. Последняя версия языка, доступная в сентябре 2015 года — 3.4.3, именно её необходимо установить дома, скачав данную версию с сайта www.python.org.
Запустить интерпретатор python можно из командной строки:
Будьте внимательны — команда python запустит интерпретатор версии 2, с которым мы работать не будем. В системе Windows можно использовать пункт меню «Python (command line)».
IPython — интерактивная оболочка для языка программирования Python, которая предоставляет расширенную интроспекцию, дополнительный командный синтаксис, подсветку кода и автоматическое дополнение. Является компонентом пакета программ SciPy.
IPython может использоваться как замена стандартной командной оболочки операционной системы, особенно на платформе Windows, возможности оболочки которой ограничены. Поведение по умолчанию похоже на поведение оболочек UNIX-подобных систем, но тот факт, что работа происходит в окружении Python, позволяет добиваться большей настраиваемости и гибкости.
Для обучения возможностям Python лучше сразу использовать оболочку IPython.
Итак, запустив оболочку Python Вы увидите примерно следующее приглашение командной строки:
Смело вводите команды и наслаждайтесь результатом. А что можно вводить? Несколько примеров:
Первая команда вычисляет сумму двух чисел, вторая команда вычисляет 2 в степени 100, третья команда выполняет операцию конкатенации для строк, а четвертая команда печатает строку ‘ABC’ , повторенную 10 раз.
Хотите закончить работу с питоном? Введите команду exit() (именно так, со скобочками, так как это — функция) или нажмите Ctrl+D .
Итак, мы видим, что Python умеет работать как минимум с двумя видами данных — числами и строками. Числа записываются последовательностью цифр, также перед числом может стоять знак минус, а строки записываются в одинарных кавычках. 2 и ‘2’ — это разные объекты, первый объект — число, а второй — строка. Операция + для целых чисел и для строк работает по-разному: для чисел это сложение, а для строк — конкатенация.
Кроме целых чисел есть и другой класс чисел: действительные (вещественные числа), представляемые в виде десятичных дробей. Они записываются с использованием десятичной точки, например, 2.0 . В каком-то смысле, 2 и 2.0 имеют равные значение, но это — разные объекты. Например, можно вычислить значения выражения ‘ABC’*10 (повторить строку 10 раз), но нельзя вычислить ‘ABC’*10.0 .
Определить тип объекта можно при помощи функции type :
Обратите внимание — type является функцией, аргументы функции указываются в скобках после ее имени.
Вот список основных операций для чисел:
- A+B — сумма;
- A-B — разность;
- A*B — произведение;
- A/B — частное;
- A**B — возведение в степень.
Полезно помнить, что квадратный корень из числа x — это x**0.5 , а корень степени n — это x**(1/n) .
Есть также унарный вариант операции — , то есть операция с одним аргументом. Она возвращает число, противоположное данному. Например: -A .
В выражении может встречаться много операций подряд. Как в этом случае определяется порядок действий? Например, чему будет равно 1+2*3**1+1 ? В данном случае ответ будет 8, так как сначала выполняется возведение в степень, затем — умножение, затем — сложение.
Более общие правила определения приоритетов операций такие:
- Выполняются возведения в степень справа налево, то есть 3**3**3 это 3²⁷.
- Выполняются унарные минусы (отрицания).
- Выполняются умножения и деления слева направо. Операции умножения и деления имеют одинаковый приоритет.
- Выполняются сложения и вычитания слева направо. Операции сложения и вычитания имеют одинаковый приоритет.
Основные операции над строками:
- A+B — конкатенация;
- A*n — повторение n раз, значение n должно быть целого типа.
Вычислите длину гипотенузы в прямоугольном треугольнике со сторонами 179 и 971.
Иногда бывает полезно целое число записать, как строку. И, наоборот, если строка состоит из цифр, то полезно эту строку представить в виде числа, чтобы дальше можно было выполнять арифметические операции с ней. Для этого используются функции, одноименные с именем типа, то есть int , float , str . Например, int(‘123’) вернет целое число 123 , а str(123) вернет строку ‘123’ .
Результатом будет строка из числа 4 , повторенная 22 раза.
В предыдущем задании мы использовали Python для простых разовых вычислений, используя интерактивный режим. Например, было задание вычислить длину гипотенузы прямоугольного треугольника по ее катетам. Запустите текстовый редактор и напишите следующий текст:
Здесь мы используем переменные — объекты, в которых можно сохранять различные (числовые, строковые и прочие) значения. В первой строке переменной a присваивается значение 179 , затем переменной b присваивается значение 971 , затем переменной c присваивается значение арифметического выражения, равному длине гипотенузы. После этого значение переменной c выводится на экран.
Сохраните этот текст в файле с именем hypot.py . Запустите терминал, перейдите в каталог, где лежит этот файл и выполните эту программу:
Интерпретатор языка Python, запущенный с указанием имени файла, запускается не в интерактивном режиме, а выполняет ту последовательность команд, которая сохранена в файле. При этом значения вычисленных выражений не выводятся на экран (в отличии от интерактивного режима), поэтому для того, чтобы вывести результат работы программы, то есть значение переменной c , нам понадобится специальная функция print .
Пример выше неудобен тем, что исходные данные для программы заданы в тексте программы, и для того, чтобы использовать программу для другого треугольника необходимо исправлять текст программы. Это неудобно, лучше, чтобы текст программы не менялся, а программа запрашивала бы у пользователя данные, необходимые для решения задачи, то есть запрашивала бы значения двух исходных переменных a и b . Для этого будем использовать функцию input() , которая считывает строку с клавиатуры и возвращает значение считанной строки, которое сразу же присвоим переменым a и b :
Правда, функция input возвращает текстовую строку, а нам нужно сделать так, чтобы переменные имели целочисленные значения. Поэтому сразу же после считывания выполним преобразование типов при помощи фунцкии int , и запишем новые значения в переменные a и b .
Можно объединить считывание строк и преобразование типов, если вызывать функцию int для того значения, которое вернет функция input :
Далее в программе вычислим значение переменной c и выведем результат на экран.
Теперь мы можем не меняя исходного кода программы многократно использовать ее для решения различных задач. Для того нужно запустить программу и после запуска программы ввести с клавиатуры два числа, нажимая после кажого числа клавишу Enter . Затем программа сама выведет результат.
Функция print может выводить не только значения переменных, но и значения любых выражений. Например, допустима запись print(2 + 2 ** 2) . Также при помощи функции print можно выводить значение не одного, а нескольких выражений, для этого нужно перечислить их через запятую:
В данном случае будет напечатан текст 1 + 2 = 3 : сначала выводится зание переменной a , затем строка из знака + , затем значение переменной b , затем строка из знака = , наконец, значение суммы a + b .
Обратите внимание, выводимые значение разделяются одним пробелом. Но такое поведение можно изменить: можно разделять выводимые значения двумя пробелами, любым другим символом, любой другой строкой, выводить их в отдельных строках или не разделять никак. Для этого нужно функции print передать специальный именованный параметр, называемый sep , равный строке, используемый в качестве разделителя (sep — аббревиатура от слова separator, т.е. разделитель). По умолчанию параметр sep равен строке из одного пробела и между значениями выводится пробел. Чтобы использовать в качестве разделителя, например, символ двоеточия нужно передать параметр sep , равный строке ‘:’ :
Аналогично, для того, чтобы совсем убрать разделитель при выводе нужно передать параметр sep , равный пустой строке:
Для того, чтобы значения выводились с новой строке, нужно в качестве параметра sep передать строку, состоящую из специального символа новой строки, которая задается так:
Символ обратного слэша в текстовых строках является указанием на обозначение специального символа, в зависимости от того, какой символ записан после него. Наиболее часто употребляется символ новой строки ‘\n’ . А для того, чтобы вставить в строку сам символ обратного слэша, нужно повторить его два раза: ‘\\’ .
Вторым полезным именованным параметром функции print является параметр end , который указывает на то, что выводится после вывода всех значений, перечисленных в функции print . По умолчанию параметр end равен ‘\n’ , то есть следующий вывод будет происходить с новой строки. Этот параметр также можно исправить, например, для того, чтобы убрать все дополнительные выводимые символы можно вызывать функцию print так:
Дано два числа a и b . Выведите гипотенузу треугольника с заданными катетами.
| Ввод | Вывод |
|---|---|
| 3 | 5 |
| 4 |
Напишите программу, которая считывает целое число и выводит текст, аналогичный приведенному в примере:
| Ввод | Вывод |
|---|---|
| 2015 | The next number for the number 2015 is 2016 |
| The previous number for the number 2015 is 2014 |
Для целых чисел определены ранее рассматривавшиеся операции + , — , * и ** . Операция деления / для целых чисел возвращает значение типа float . Также функция возведения в степень возвращает значение типа float , если показатель степени — отрицательное число.
Но есть и специальная операция целочисленного деления, выполняющегося с отбрасыванием дробной части, которая обозначается // . Она возвращает целое число: целую часть частного. Например:
Другая близкая ей операция — это операция взятия остатка от деления, обозначаемая % :
Дано натуральное число. Выведите его последнюю цифру. Пример:
| Ввод | Вывод |
|---|---|
| 179 | 9 |
Дано натуральное число. Найдите число десятков в его десятичной записи (то есть вторую справа цифру его десятичной записи). Пример:
| Ввод | Вывод |
|---|---|
| 179 | 7 |
Любой текст состоит из символов. Символ — это некоторый значок, изображение. Один и тот же символ можно записать по- разному, например, два человека по-разному напишут от руки букву «A», и даже в компьютерном представлении одна и та же буква будет выглядеть по-разному, если ее отображать разными шрифтами, при этом это будет все равно один и тот же символ. Верно и другое: разные символы могут быть записаны одинаково, например, вот две разные буквы, одна — латинского алфавита, другая — русского: «A» и «А». Несмотря на то, что они выглядят одинаково, удобней считать их разными символами.
Итак, способ хранения текстовой информации в компьютере не связан напрямую с изображением этого текста. Вместо символов хранятся их номера — числовые коды, а вот то, как выглядит символ с данным числовым кодом на экране напрямую зависит от того, какой используется шрифт для отображения символов. При этом, разумеется, следовало бы договориться о единообразном способе кодирования символов числовыми кодами, иначе текст, записанный на одном компьютере, невозможно будет прочитать на другом компьютере.
Первоначально договорились под кодирование одного символа отвести один байт, то есть 8 бит информации. Таким образом можно было закодировать 256 различных значений, то есть в записи текста можно использовать 256 различных символов. Этого достаточно, чтобы отобразить все символы латинского алфавита, цифры, знаки препинания и некоторые другие символы. Стандарт, указывающий, какие числовые коды соответствуют каким основным символам, называется ASCII. В таблицу ASCII включены символы с кодами от 0 до 127, то есть ASCII — это семибитный код. Вот так выглядит таблица ASCII:
При этом символы с кодами, меньшими 32 — это специальные управляющие символы, которые не отображаются на экране. Например, для того, чтобы обозначить конец строки в системе Linux используется один символ с кодом 10, а в системе Windows — два подряд идущих символа с кодами 13 и 10, символы с кодами 48-57 соответствуют начертанию арабских цифр (обратите внимание, символ с кодом 0 — это вовсе не символ, отображающийся на экране, как «0»), символы с кодами 65-90 — заглавные буквы буквы латинского алфавита, а если к их кодам прибавить 32, то получатся строчные буквы латинского алфавита. В промежутках между указанными диапазонами находятся знаки препинания, математические операции и прочие символы.
Но в ASCII-таблицы нет русских букв! А также нет букв сотен других национальных алфавитов. Первоначально для отображения букв национальных алфавитов использовали вторую половину возможного значения байта, то есть символы с кодами от 128 до 255. Это приводило к множеству проблем, например, поскольку 128 значений явно недостаточно для того, чтобы отобразить символы всех национальных алфавитов (даже недостаточно для того, чтобы отобразить символы одного алфавита, например, китайской письменности. Поэтому в настоящее время для кодирования символов используется стандарт Unicode версия 6.0 которого (октябрь, 2010) включает свыше 109000 различных символов. Естественно, для кодирования Unicode-символов недостаточно одного байта на символ, поэтому используются многобайтовые кодировки (для представления одного символа необходимо несколько байт).
Язык программирования Python — современный язык, поэтому он работает исключительно с Unicode-символами.
Код символа можно определить при помощи функции ord . Эта функция получает на вход строку, которая дол на состоять ровно из одного символа. Функция возвращает код этого символа. Например, ord(‘A’) вернет число 65 .
Обратная функция получения по числовому коду его номера называется chr .
Поскольку для символов заданы их числовые коды, то их можно сравнивать при помощи операций сравения. Поскольку символы алфавита идут подряд, то результат их сравнения будет соответствовать лексикографическому порядку, но можно сравнивать между собой не только буквы алфавита, но и два произвольных символа.
Также в питоне определены и операции сравнения строк, которые также сравниваются в лексикографическом порядке.
Считайте со стандартного ввода символ и выведите его код.
Программа получает на вход один символ с кодом от 33 до 126. Пример:
| Ввод | Вывод |
|---|---|
| A | 65 |
Считайте со стандартного ввода целое число и выведите ASCII-символ с таким кодом. Решите эту задачу с использованием только одной переменной типа int .
Программа получает на вход число от 33 до 126. Пример:
| Ввод | Вывод |
|---|---|
| 65 | A |
Строка считывается со стандартного ввода функцией input() . Напомним, что для двух строк определа операция сложения (конкатенации), также определена операция умножения строки на число.
Строка состоит из последовательности символов. Узнать количество символов (длину строки) можно при помощи функции len :
Срез (slice) — извлечение из данной строки одного символа или некоторого фрагмента подстроки или подпоследовательности.
Есть три формы срезов. Самая простая форма среза: взятие одного символа строки, а именно, S[i] — это срез, состоящий из одного символа, который имеет номер i , при этом считая, что нумерация начинается с числа 0. То есть если S=’Hello’ , то S[0]==’H’ , S[1]==’e’ , S[2]==’l’ , S[3]==’l’ , S[4]==’o’ .
Номера символов в строке (а также в других структурах данных: списках, кортежах) называются индексом.
Если указать отрицательное значение индекса, то номер будет отсчитываться с конца, начиная с номера -1 . То есть S[-1]==’o’ , S[-2]==’l’ , S[-3]==’l’ , S[-4]==’e’ , S[-5]==’H’ .
Или в виде таблицы:
| Строка S | H | e | l | l | o |
|---|---|---|---|---|---|
| Индекс | S[0] | S[1] | S[2] | S[3] | S[4] |
| Индекс | S[-5] | S[-4] | S[-3] | S[-2] | S[-1] |
Если же номер символа в срезе строки S больше либо равен len(S) , или меньше, чем -len(S) , то при обращении к этому символу строки произойдет ошибка IndexError: string index out of range .
Срез с двумя параметрами: S[a:b] возвращает подстроку из b-a символов, начиная с символа c индексом a , то есть до символа с индексом b , не включая его. Например, S[1:4]==’ell’ , то же самое получится если написать S[-4:-1] . Можно использовать как положительные, так и отрицательные индексы в одном срезе, например, S[1:-1] — это строка без первого и последнего символа (срез начинается с символа с индексом 1 и заканчиватеся индексом -1, не включая его).
При использовании такой формы среза ошибки IndexError никогда не возникает. Например, срез S[1:5] вернет строку ‘ello’ , таким же будет результат, если сделать второй индекс очень большим, например, S[1:100] (если в строке не более 5 символов).
Если опустить второй параметр (но поставить двоеточие), то срез берется до конца строки. Например, чтобы удалить из строки первый символ (его индекс равен 0, то есть взять срез, начиная с символа с индексом 1), то можно взять срез S[1:] , аналогично если опустиить первый параметр, то срез берется от начала строки. То есть удалить из строки последний символ можно при помощи среза S[:-1] . Срез S[:] совпадает с самой строкой S .
Если задать срез с тремя параметрами S[a:b:d] , то третий параметр задает шаг, как в случае с функцией range , то есть будут взяты символы с индексами a , a+d , a+2*d и т.д. При задании значения третьего параметра, равному 2, в срез попадет кажый второй символ, а если взять значение среза, равное -1 , то символы будут идти в обратном порядке.
Метод — это функция, применяемая к объекту, в данном случае — к строке. Метод вызывается в виде Имя_объекта.Имя_метода(параметры) . Например, S.find(«e») — это применение к строке S метода find с одним параметром «e» .
Метод find находит в данной строке (к которой применяется метод) данную подстроку (которая передается в качестве параметра). Функция возвращает индекс первого вхождения искомой подстроки. Если же подстрока не найдена, то метод возвращает значение -1. Например:
Аналогично, метод rfind возвращает индекс последнего вхождения данной строки («поиск справа»).
Если вызвать метод find с тремя параметрами S.find(T, a, b) , то поиск будет осуществляться в срезе S[a:b] . Если указать только два параметра S.find(T, a) , то поиск будет осуществляться в срезе S[a:] , то есть начиная с символа с индексом a и до конца строки. Метод S.find(T, a, b) возращает индекс в строке S , а не индекс относительно начала среза.
Метод replace заменяет все вхождения одной строки на другую. Формат: S.replace(old, new) — заменить в строке S все вхождения подстроки old на подстроку new . Пример:
Если методу replace задать еще один параметр: S.replace(old, new, count) , то заменены будут не все вхождения, а только не больше, чем первые count из них.
Метод count подсчитывает количество вхождений одной строки в другую строку. Простейшая форма вызова S.count(T) возвращает число вхождений строки T внутри строки S . При этом подсчитываются только непересекающиеся вхождения, например:
При указании трех параметров S.count(T, a, b) , будет выполнен подсчет числа вхождений строки T в срез S[a:b] .
Дана строка. Последовательно на разных строках выведите:
- третий символ этой строки;
- предпоследний символ этой строки;
- первые пять символов этой строки;
- всю строку, кроме последних двух символов;
- все символы с четными индексами (считая, что индексация начинается с 0, поэтому символы выводятся начиная с первого);
- все символы с нечетными индексами, то есть начиная со второго символа строки;
- все символы в обратном порядке.
- все символы строки через один в обратном порядке, начиная с последнего;
- длину данной строки.
Ввод вывод Абракадабра р р Абрак Абракадаб Аркдба бааар арбадакарбА абдкрА 11
Дана строка, состоящая из слов, разделенных пробелами. Определите, сколько в ней слов. Используйте для решения задачи метод count . Пример:
| Ввод | Вывод |
|---|---|
| Hello world | 2 |
Получите новую строку, вставив между двумя символами исходной строки символ *. Выведите полученную строку. Пример:
| Ввод | Вывод |
|---|---|
| python | p*y*t*h*o*n |
Замените в строке все появления буквы h на букву H, кроме первого и последнего вхождения. Пример:
| Ввод | Вывод |
|---|---|
| aahhhhhbb | aahHHHhbb |
PEP 8 создан на основе рекомендаций Гвидо ван Россума — создателя языка Python.
Ключевая идея Гуидо такова: код читается намного больше раз, чем пишется. Собственно, рекомендации о стиле написания кода направлены на то, чтобы улучшить читаемость кода и сделать его согласованным между большим числом проектов. В идеале, весь код будет написан в едином стиле, и любой сможет легко его прочесть.