Техблог Александра Куракина
Если все вводные данные помещаются в память, тогда простейший путь создать Dataset из данных — это конвертировать их в tf.Tensor объекты и использовать Dataset.from_tensor_slices().
Следует отметить, что пример кода выше встроит массивы свойств и меток в TensorFlow граф как tf.constant() операции. Это работает хорошо на небольших датасетах, но тратит напрасно память, потому что содержимое массива будет скопировано много раз, и может достичь 2GB лимита для буфера tf.GraphDef протокола.
В качестве альтернативы, можно определить Dataset с точки зрения tf.placeholder() тензоров и передать NumPy массивы при инициализации Iterator для датасета.
Получение TFRecord данных
tf.data API поддерживает различные форматы файлов, так можно обрабатывать большие наборы данных, которые не помещаются в память. Например, TFRecord формат — это простой ориентированный на записи бинарный формат, который многие TensorFlow приложения используют для тренировочных данных. tf.data.TFRecordDataset класс позволяет проходить по содержимому одного или нескольких TFRecord файлов как часть пайплайна ввода.
filenames (имена файлов) аргумент для TFRecordDataset инициализатора может быть строкой, списком строк, или tf.Tensor строк. Таким образом можно иметь два набора файлов для целей тренировки и валидации, можно использовать tf.placeholder(tf.string) для представления filenames (имен файлов), и инициализировать итератор из подходящих имен файлов:
Получение текстовых данных
Многие наборы данных поставляются как один или несколько текстовых файлов. tf.data.TextLineDataset предоставляет легкий путь извлечения строк из одного или нескольких файлов. Получив одно или несколько имен файлов, TextLineDataset производит один элемент строкового значения на каждую строку этих файлов. Как TFRecordDataset, TextLineDataset принимает имена файлов как tf.Tensor, таким образом можно параметризировать его передавая tf.placeholder(tf.string).
По умолчанию, TextLineDataset выводит каждую строку каждого файла, что может быть нежелательным, например если файл начинается с линии заголовка или содержит комментарии. Эти строки могут быть удалены использованием Dataset.skip() и Dataset.filter() преобразований. Для применения преобразований к каждому файлу отдельно используем Dataset.flat_map() для создания вложенного Dataset для каждого файла.
Получение CSV данных
CSV формат файлов — популярный формат для сохранения табличных данных в простой текст. tf.contrib.data.CsvDataset класс предоставляет путь извлечения записей из одного или нескольких CSV файлов, которые соотвествуют RFC 4180. Получив одно или несколько имен файлов и лист типа данных по умолчанию, CsvDataset производит tuple элементов, типы которых соответствуют типам, предоставленным по умолчанию, для каждой CSV записи. Как TFRecordDataset и TextLineDataset, CsvDataset принимает имена файлов как tf.Tensor, таким образом можно параметризировать его передавая tf.placeholder(tf.string).
Если некоторые колонки пустые можно предоставить значения по умолчанию.
По умолчанию CsvDataset выводит каждую колонку каждой строки файла, что может быть нежелательным, например если файл начинается с линии заголовка, которая должна быть пропущена, или некоторые колонки не требуются во вводе. Эти строки и поля могут быть удалены с header и select_cols аргументами соответственно.
Как в tensoboard прочитать файл
I’ve run several training sessions with different graphs in TensorFlow. The summaries I set up show interesting results in the training and validation. Now, I’d like to take the data I’ve saved in the summary logs and perform some statistical analysis and in general plot and look at the summary data in different ways. Is there any existing way to easily access this data?
More specifically, is there any built in way to read a TFEvent record back into Python?
If there is no simple way to do this, TensorFlow states that all its file formats are protobuf files. From my understanding of protobufs (which is limited), I think I’d be able to extract this data if I have the TFEvent protocol specification. Is there an easy way to get ahold of this? Thank you much.
9 Answers 9
As Fabrizio says, TensorBoard is a great tool for visualizing the contents of your summary logs. However, if you want to perform a custom analysis, you can use tf.train.summary_iterator() function to loop over all of the tf.Event and tf.Summary protocol buffers in the log:
You need to import it, that module level is not currently imported by default. On 2.0.0-rc2
Русские Блоги
Программы TensorBoard и TensorFLow выполняются в разных процессах.TensorBoard автоматически прочитает последний файл журнала TensorFlow и представит последний статус текущей запущенной программы TensorFLow.
2. Процесс использования TensorBoard
- Добавить узел записи: tf.summary.scalar/image/histogram() Подождите
- Узел сводной записи: merged = tf.summary.merge_all()
- Запустите сводный узел: summary = sess.run(merged) , Получите сводный результат
- Создание экземпляра модуля записи журнала: summary_writer = tf.summary.FileWriter(logdir, graph=sess.graph) , При создании экземпляра передайте график и запишите текущий график вычислений в журнал
- Объект экземпляра модуля записи журнала вызовов summary_writer из add_summary(summary, global_step=i) Метод записи всех сводных журналов в файл
- Объект экземпляра записи журнала вызовов summary_writer из close() Метод записи в память, иначе пишет каждые 120 с
Два, визуальная классификация TensorFlow
1. Визуализация графика расчета: add_graph ()
# Launch the graph in a session.
# Create a summary writer, add the ‘graph’ to the event file.
writer = tf.summary.FileWriter(logdir, sess.graph)
Writer.close () # Запись в память при закрытии, иначе будет записываться каждые 120 секунд
2. Визуализация индикаторов мониторинга: add_summary ()
Во время процесса обучения визуализации, уровень точности (val acc), значение потерь (потеря обучения / теста), скорость обучения (скорость обучения), статистика веса и смещения каждого слоя (среднее, стандартное, макс. / Мин.) ) И т.д.
- name: имя узла операции, вертикальная ось графика, нарисованного в TensorBoard, также будет использовать это имя
- тензор: переменная, которая должна отслеживаться. Настоящий числовой тензор, содержащий одно значение.
- A scalar Tensor of type string. Which contains a Summary protobuf.
Визуализация Текущий раунд Обучающие / тестовые изображения или карты функций, используемые для обучения
- name: имя этого рабочего узла, вертикальная ось графика, нарисованного в TensorBoard, также будет использовать это имя
- tensor: A r A 4-D uint8 or float32 Tensor of shape [batch_size, height, width, channels] where channels is 1, 3, or 4
- max_outputs:Max number of batch elements to generate images for
- A scalar Tensor of type string. Which contains a Summary protobuf.
Визуализируйте распределение значений тензора
- name: имя узла операции, вертикальная ось графика, нарисованного в TensorBoard, также будет использовать это имя
- tensor: A real numeric Tensor. Any shape. Values to use to build the histogram
- A scalar Tensor of type string. Which contains a Summary protobuf.
- Merges all summaries collected in the default graph
- Поскольку в программе определено множество операций записи журналов, вызывать их по очереди очень сложно, поэтому TensoorFlow предоставляет эту функцию для организации всех операций создания журналов, например: merged = tf.summary.merge_all ()
- Эта операция не будет выполнена сразу, поэтому вам нужно явно запустить эту операцию ( summary = sess.run(merged) ) Чтобы получить итоговый результат
- Наконец, вызовите объект экземпляра записи журнала add_summary(summary, global_step=i) Метод записи всех сводных журналов в файл
3. Визуализация нескольких событий: add_event ()
- Если подкаталог каталога logdir содержит данные из другого запуска (несколько событий), то TensorBoard отобразит все данные запуска (в основном скалярные), которые можно использовать для сравнения эффекта модели при различных параметрах и настройки параметров модели. , Пусть добьется наилучшего эффекта!
- Верхняя строка — это график потерь с 200 итерациями, а нижняя — график с 400 итерациями. См. Конец процедуры.
В-третьих, украсьте граф вычислений с помощью пространства имен
- Используйте пространства имен, чтобы сделать визуализацию более иерархической, чтобы общая структура нейронной сети не была перегружена слишком большим количеством деталей.
- Все узлы в одном пространстве имен будут сокращены до одного узла, и только узлы в пространстве имен верхнего уровня будут отображаться в визуализации TensorBoard.
- доступный tf.name_scope() или tf.variable_scope() Подробности см. В заключительной процедуре.

4. Запишите все журналы в файл: tf.summary.FileWriter ()

-
Отвечает за запись журналов событий (график, скаляр / изображение / гистограмма, событие) в указанный файл
- logdir: каталог, в который записано событие
- график: если передано во время инициализации sess,graph Эквивалентно вызову add_graph() Метод визуализации вычислительного графа
- flush_sec:How often, in seconds, to flush the added summaries and events to disk.
- max_queue:Maximum number of summaries or events pending to be written to disk before one of the ‘add’ calls block.
- add_event(event) :Adds an event to the event file
- add_graph(graph, global_step=None) :Adds a Graph to the event file,Most users pass a graph in the constructor instead
- add_summary(summary, global_step=None) : Добавляет буфер итогового протокола в файл событий, обязательно передайте global_step
- close() :Flushes the event file to disk and close the file
- flush() :Flushes the event file to disk
- add_meta_graph(meta_graph_def,global_step=None)
- add_run_metadata(run_metadata, tag, global_step=None)
5. Запустите TensorBoard, чтобы отобразить все диаграммы журнала.
1. Запускаем cmd под Windows
- Запустите вашу программу в указанном каталоге ( logs ) Создать event файл
- В logs В каталоге нажмите и удерживайте shift Кнопка, щелкните правой кнопкой мыши и выберите открыть здесь cmd
- В cmd , Введите следующую команду, чтобы начать tensorboard —logdir=logs Примечание. Каталог журналов указывать не нужно. Если в журналах есть несколько событий, будет сгенерирован сравнительный скалярный график, но на графике будут отображаться только последние результаты.
- Поместите сгенерированный URL ниже ( http: // DESKTOP-S2Q1MOS: 6006 # Все могут быть разными ) Скопируйте в браузер, чтобы открыть


Tensorflow – чтение файлов
TensorFlow поддерживает чтение больших наборов данных таким образом, чтобы данные никогда не хранились в памяти полностью (было бы не очень хорошо, если бы он имел это ограничение).
Есть несколько функций и опций из стандартной библиотеки Python, которые вы можете использовать для решения этой задачи.
Более того, TensorFlow поддерживает создание произвольных обработчиков данных, и на это определенно стоит обратить внимание, если в своем проекте вы работаете с большим количеством данных. Написание собственной функции загрузки данных — это небольшое усилие с вашей стороны, которое может сэкономить много времени позже на проекте. Ознакомьтесь с официальной документацией для получения дополнительной информации по этой теме.
В этой статье мы рассмотрим основы чтения CSV-файла при помощи TensorFlow и использования этих данных в ваших графах.
Placeholder-ы
Самый простой способ чтения данных — просто прочитать их при помощи стандартного кода на Python. Давайте рассмотрим базовый пример и прочитаем данные из файла олимпийских игр 2016 года.
Первое, что мы сделаем, это создадим граф, который берет одну строку данных за другой и суммирует общие медали.
Далее определим новую операцию tf.Print(), которая будет суммировать и печатать общий результат сложения всех медалей (features).
Что происходит, когда мы используем printerop? Эта переменная ссылается на функцию, которая регистрирует текущие значения, переданные ей во втором параметре (в данном случае список [country, features, total]) и возвращает их сумму, применяя к этому списку операцию total. Далее мы открываем сеанс для расчетов графа, открываем файл для чтения и передаем строки из файла функции printerop строка за строкой. Обратите внимание, что чтение файла выполняется исключительно средствами Python во время расчетов в сеансе.
Результат исполнения этого кода будет выглядеть следующим образом:
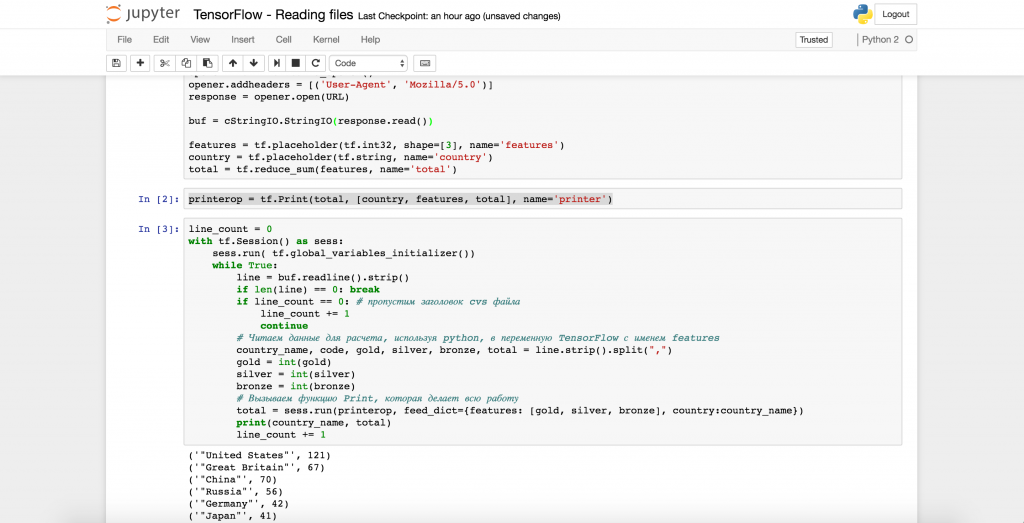
Внутри цикла мы читаем файла файл построчно, разделяем каждую строку на элементы до каждой запятой, преобразуем значения в целые числа и затем передаем данные в файл feed_dict в качестве значений для placeholder-а.
При каждом вызове printerop в лог TensorFlow будет попадать строка вида, содержащая лог операции:
Результат же самой операции будет печататься на стандартный поток вывода функцией print (country_name, total), которая печатает текущее имя страны из Python переменной и результат работы printerop (сумма золотых, серебряных и бронзовых медалей).
Работа с данными в TensorFlow подобным образом является хорошей практикой: создайте placeholder-ы, в цикле загружайте немного данных в память, вычисляйте нужные вам значения и переходите к новой порции данными.
Чтение csv файлов в Tensorflow
TensorFlow поддерживает и непосредственное считывание данных в тензоры, однако работать с CSV форматом далеко не всегда удобно и приятно. Тем не менее, т.к. это довольно частый сценарий, давайте рассмотрим один из множества способ сделать это.
Суть подхода заключается в том, чтобы определить список имен файлов, из которых необходимо прочитать данные, затем создать функцию для чтения, которая будет позже вызываться в процессе работы сессии. Внутри функции для чтения нужно определить переменные, которые заменяются фактическими значениями, когда они выполняются на этапе выполнения графика.
Функция file_reader_func здесь принимает объект очереди, а не обычный список Python, поэтому нам нужно создать его перед тем, как передавать его в нашу функцию:
Результатом вызова функции file_reader_func будут значения каждой отдельной строки из нашего набора данных. Далее, т.к. файлов в наборе данных может быть несколько, нам потребуется координатор Coordinator , задачей которого будет переключение между файлами набора данных при чтении каждый раз, когда будут оцениваться значения переменных example и label.
Цикл while будет обходить данные до тех пор, пока у нас не останется данных и не возникнет исключение OutOfRangeError.
Чтение и запись данных (cvs, txt, HTML, XML) / pd 7
Вы уже знакомы с библиотекой pandas и ее базовой функциональностью по анализу данных. Также знаете, что в ее основе лежат два типа данных: Dataframe и Series . На их основе выполняется большая часть взаимодействия с данными, вычислений и анализа.
В этом материале вы познакомитесь с инструментами, предназначенными для чтения данных, сохраненных в разных источниках (файлах и базах данных). Также научитесь записывать структуры в эти форматы, не задумываясь об используемых технологиях.
Этот раздел посвящен функциям API I/O (ввода/вывода), которые pandas предоставляет для чтения и записи данных прямо в виде объектов Dataframe . Начнем с текстовых файлов, а затем перейдем к более сложным бинарным форматам.
А в конце узнаем, как взаимодействовать с распространенными базами данных, такими как SQL и NoSQL , используя для этого реальные примеры. Разберем, как считывать данные из базы данных, сохраняя их в виде Dataframe .
Инструменты API I/O
pandas — библиотека, предназначенная для анализа данных, поэтому логично предположить, что она в первую очередь используется для вычислений и обработки данных. Процесс записи и чтения данных на/с внешние файлы — это часть обработки. Даже на этом этапе можно выполнять определенные операции, готовя данные к взаимодействию.
Первый шаг очень важен, поэтому для него представлен полноценный инструмент в библиотеке, называемый API I/O. Функции из него можно разделить на две категории: для чтения и для записи.
| Чтение | Запись |
|---|---|
| read_csv | to_csv |
| read_excel | to_excel |
| read_hdf | to_hdf |
| read_sql | to_sql |
| read_json | to_json |
| read_html | to_html |
| read_stata | to_stata |
| read_clipboard | to_clipboard |
| read_pickle | to_pickle |
| read_msgpack | to_msgpack (экспериментальный) |
| read_gbq | to_gbq (экспериментальный) |
CSV и текстовые файлы
Все привыкли к записи и чтению файлов в текстовой форме. Чаще всего они представлены в табличной форме. Если значения в колонке разделены запятыми, то это формат CSV (значения, разделенные запятыми), который является, наверное, самым известным форматом.
Другие формы табличных данных могут использовать в качестве разделителей пробелы или отступы. Они хранятся в текстовых файлах разных типов (обычно с расширением .txt).
Такой тип файлов — самый распространенный источник данных, который легко расшифровывать и интерпретировать. Для этого pandas предлагает набор функций:
- read_csv
- read_table
- to_csv
Чтение данных из CSV или текстовых файлов
Самая распространенная операция по взаимодействию с данными при анализе данных — чтение их из файла CSV или как минимум текстового файла.
Для этого сперва нужно импортировать отдельные библиотеки.
Чтобы сначала увидеть, как pandas работает с этими данными, создадим маленький файл CSV в рабочем каталоге, как показано на следующем изображении и сохраним его как ch05_01.csv .
Поскольку разделителем в файле выступают запятые, можно использовать функцию read_csv() для чтения его содержимого и добавления в объект Dataframe .
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
Это простая операция. Файлы CSV — это табличные данные, где значения одной колонки разделены запятыми. Поскольку это все еще текстовые файлы, то подойдет и функция read_table() , но в таком случае нужно явно указывать разделитель.
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
В этом примере все заголовки, обозначающие названия колонок, определены в первой строчке. Но это не всегда работает именно так. Иногда сами данные начинаются с первой строки.
Создадим файл ch05_02.csv
| 1 | 5 | 2 | 3 | cat | |
|---|---|---|---|---|---|
| 0 | 2 | 7 | 8 | 5 | dog |
| 1 | 3 | 3 | 6 | 7 | horse |
| 2 | 2 | 2 | 8 | 3 | duck |
| 3 | 4 | 4 | 2 | 1 | mouse |
| 4 | 4 | 4 | 2 | 1 | mouse |
В таком случае нужно убедиться, что pandas не присвоит названиям колонок значения первой строки, передав None параметру header .
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
Также можно самостоятельно определить названия, присвоив список меток параметру names .
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
В более сложных случаях когда нужно создать Dataframe с иерархической структурой на основе данных из файла CSV, можно расширить возможности функции read_csv() добавив параметр index_col , который конвертирует колонки в значения индексов.
Чтобы лучше разобраться с этой особенностью, создайте новый CSV-файл с двумя колонками, которые будут индексами в иерархии. Затем сохраните его в рабочую директорию под именем ch05_03.csv .
Создадим файл ch05_03.csv
| item1 | item2 | item3 | ||
|---|---|---|---|---|
| color | status | |||
| black | up | 3 | 4 | 6 |
| down | 2 | 6 | 7 | |
| white | up | 5 | 5 | 5 |
| down | 3 | 3 | 2 | |
| left | 1 | 2 | 1 | |
| red | up | 2 | 2 | 2 |
| down | 1 | 1 | 4 |
Использованием RegExp для парсинга файлов TXT
Иногда бывает так, что в файлах, из которых нужно получить данные, нет разделителей, таких как запятая или двоеточие. В таких случаях на помощь приходят регулярные выражения. Задать такое выражение можно в функции read_table() с помощью параметра sep .
Чтобы лучше понимать regexp и то, как их использовать для разделения данных, начнем с простого примера. Например, предположим, что файл TXT имеет значения, разделенные пробелами и отступами хаотично. В таком случае regexp подойдут идеально, ведь они позволяют учитывать оба вида разделителей. Подстановочный символ /s* отвечает за все символы пробелов и отступов (если нужны только отступы, то используется /t ), а * указывает на то, что символов может быть несколько. Таким образом значения могут быть разделены большим количеством пробелов.
| . | Любой символ за исключением новой строки |
| \d | Цифра |
| \D | Не-цифровое значение |
| \s | Пробел |
| \S | Не-пробельное значение |
| \n | Новая строка |
| \t | Отступ |
| \uxxxx | Символ Unicode в шестнадцатеричном виде |
Возьмем в качестве примера случай, где значения разделены отступами или пробелами в хаотическом порядке.
Создадим файл ch05_04.txt
| white | red | blue | green | |
|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 |
| 1 | 2 | 7 | 8 | 5 |
| 2 | 3 | 3 | 6 | 7 |
Результатом будет идеальный Dataframe , в котором все значения корректно отсортированы.
Дальше будет пример, который может показаться странным, но на практике он встречается не так уж и редко. Он пригодится для понимания принципов работы regexp. На самом деле, о разделителях (запятых, пробелах, отступах и так далее) часто думают как о специальных символах, но иногда ими выступают и буквенно-цифровые символы, например, целые числа.
В следующем примере необходимо извлечь цифровую часть из файла TXT , в котором последовательность символов перемешана с буквами.
Не забудьте задать параметр None для параметра header , если в файле нет заголовков колонок.
Создадим файл ch05_05.txt
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0 | 123 | 122 |
| 1 | 1 | 124 | 321 |
| 2 | 2 | 125 | 333 |
Еще один распространенный пример — удаление из данных отдельных строк при извлечении. Так, не всегда нужны заголовки или комментарии. Благодаря параметру skiprows можно исключить любые строки, просто присвоим ему массив с номерами строк, которые не нужно парсить.
Обратите внимание на способ использования параметра. Если нужно исключить первые пять строк, то необходимо писать skiprows = 5 , но для удаления только пятой строки — [5] .
Создадим файл ch05_06.txt
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
Чтение файлов TXT с разделением на части
При обработке крупных файлов или необходимости использовать только отдельные их части часто требуется считывать их кусками. Это может пригодится, если необходимо воспользоваться перебором или же целый файл не нужен.
Если требуется получить лишь часть файла, можно явно указать количество требуемых строк. Благодаря параметрам nrows и skiprows можно выбрать стартовую строку n ( n = SkipRows ) и количество строк, которые нужно считать после ( nrows = 1 ).
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 2 | 2 | 8 | 3 | duck |
Еще одна интересная и распространенная операция — разбитие на части того куска текста, который требуется парсить. Затем для каждой части может быть выполнена конкретная операция для получения перебора части за частью.
Например, нужно суммировать значения в колонке каждой третьей строки и затем вставить результат в объект Series . Это простой и непрактичный пример, но с его помощью легко разобраться, а поняв механизм работы, его проще будет применять в сложных ситуациях.
Запись данных в CSV
В дополнение к чтению данных из файла, распространенной операцией является запись в файл данных, полученных, например, в результате вычислений или просто из структуры данных.
Например, нужно записать данные из объекта Dataframe в файл CSV. Для этого используется функция to_csv() , принимающая в качестве аргумента имя файла, который будет сгенерирован.
Если открыть новый файл ch05_07.csv , сгенерированный библиотекой pandas, то он будет напоминать следующее:
На предыдущем примере видно, что при записи Dataframe в файл индексы и колонки отмечаются в файле по умолчанию. Это поведение можно изменить с помощью параметров index и header . Им нужно передать значение False .
Важно запомнить, что при записи файлов значения NaN из структуры данных представлены в виде пустых полей в файле.
| Unnamed: 0 | ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|---|
| 0 | blue | 6.0 | NaN | NaN | 6.0 | NaN |
| 1 | green | NaN | NaN | NaN | NaN | NaN |
| 2 | red | NaN | NaN | NaN | NaN | NaN |
| 3 | white | 20.0 | NaN | NaN | 20.0 | NaN |
| 4 | yellow | 19.0 | NaN | NaN | 19.0 | NaN |
Но их можно заменить на любое значение, воспользовавшись параметром na_rep из функции to_csv . Это может быть NULL , 0 или то же NaN .
Примечание: в предыдущих примерах использовались только объекты Dataframe , но все функции применимы и по отношению к Series .
Чтение и запись файлов HTML
pandas предоставляет соответствующую пару функций API I/O для формата HTML.
- read_html()
- to_html()
Эти две функции очень полезны. С их помощью можно просто конвертировать сложные структуры данных, такие как Dataframe , прямо в таблицы HTML , не углубляясь в синтаксис.
Обратная операция тоже очень полезна, потому что сегодня веб является одним из основных источников информации. При этом большая часть информации не является «готовой к использованию», будучи упакованной в форматы TXT или CSV . Необходимые данные чаще всего представлены лишь на части страницы. Так что функция для чтения окажется полезной очень часто.
Такая деятельность называется парсингом (веб-скрапингом). Этот процесс становится фундаментальным элементом первого этапа анализа данных: поиска и подготовки.
Примечание: многие сайты используют HTML5 для предотвращения ошибок недостающих модулей или сообщений об ошибках. Настоятельно рекомендуется использовать модуль html5lib в Anaconda.
conda install html5lib
Запись данных в HTML
Поскольку структуры данных, такие как Dataframe , могут быть большими и сложными, это очень удобно иметь функцию, которая сама создает таблицу на странице. Вот пример.
Сначала создадим простейший Dataframe . Дальше с помощью функции to_html() прямо конвертируем его в таблицу HTML.
Поскольку функции API I/O определены в структуре данных pandas, вызывать to_html() можно прямо к экземпляру Dataframe .
Результат — готовая таблица HTML, сохранившая всю внутреннюю структуру.
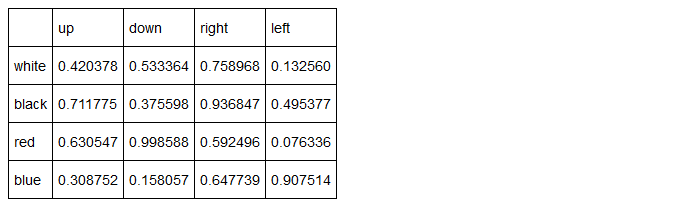
В следующем примере вы увидите, как таблицы автоматически появляются в файле HTML. В этот раз сделаем объект более сложным, добавив в него метки индексов и названия колонок.
| up | down | right | left | |
|---|---|---|---|---|
| white | 0.420378 | 0.533364 | 0.758968 | 0.132560 |
| black | 0.711775 | 0.375598 | 0.936847 | 0.495377 |
| red | 0.630547 | 0.998588 | 0.592496 | 0.076336 |
| blue | 0.308752 | 0.158057 | 0.647739 | 0.907514 |
Теперь попробуем написать страницу HTML с помощью генерации строк. Это простой пример, но он позволит разобраться с функциональностью pandas прямо в браузере.
Сначала создадим строку, которая содержит код HTML-страницы.
Теперь когда метка html содержит всю необходимую разметку, можно писать прямо в файл myFrame.html :
В рабочей директории появится новый файл, myFrame.html . Двойным кликом его можно открыть прямо в браузере. В левом верхнем углу будет следующая таблица:
Чтение данных из HTML-файла
pandas может с легкостью генерировать HTML-таблицы на основе данных Dataframe . Обратный процесс тоже возможен. Функция read_html() осуществляет парсинг HTML и ищет таблицу. В случае успеха она конвертирует ее в Dataframe , который можно использовать в процессе анализа данных.
Если точнее, то read_html() возвращает список объектов Dataframe, даже если таблица одна. Источник может быть разных типов. Например, может потребоваться прочитать HTML-файл в любой папке. Или попробовать парсить HTML из прошлого примера:
| Unnamed: 0 | up | down | right | left | |
|---|---|---|---|---|---|
| 0 | white | 0.420378 | 0.533364 | 0.758968 | 0.132560 |
| 1 | black | 0.711775 | 0.375598 | 0.936847 | 0.495377 |
| 2 | red | 0.630547 | 0.998588 | 0.592496 | 0.076336 |
| 3 | blue | 0.308752 | 0.158057 | 0.647739 | 0.907514 |
Все теги, отвечающие за формирование таблицы в HTML в финальном объекте не представлены. web_frames — это список Dataframe , хотя в этом случае объект был всего один. К нему можно обратиться стандартным путем. Здесь достаточно лишь указать на него через индекс 0.
Но самый распространенный режим работы функции read_html() — прямой парсинг ссылки. Таким образом страницы парсятся прямо, а из них извлекаются таблицы.
Например, дальше будет вызвана страница, на которой есть HTML-таблица, показывающая рейтинг с именами и баллами.
| # | Nome | Exp | Livelli | right |
|---|---|---|---|---|
| 0 | 1 | Fabio Nelli | 17521 | NaN |
| 1 | 2 | admin | 9029 | NaN |
| 2 | 3 | BrunoOrsini | 2124 | NaN |
| … | … | … | … | … |
| 247 | 248 | emilibassi | 1 | NaN |
| 248 | 249 | mehrbano | 1 | NaN |
| 249 | 250 | NIKITA PANCHAL | 1 | NaN |
Чтение данных из XML
В списке функции API I/O нет конкретного инструмента для работы с форматом XML (Extensible Markup Language). Тем не менее он очень важный, поскольку многие структурированные данные представлены именно в нем. Но это и не проблема, ведь в Python есть много других библиотек (помимо pandas), которые подходят для чтения и записи данных в формате XML.
Одна их них называется lxml и она обеспечивает идеальную производительность при парсинге даже самых крупных файлов. Этот раздел будет посвящен ее использованию, интеграции с pandas и способам получения Dataframe с нужными данными. Больше подробностей о lxml есть на официальном сайте http://lxml.de/index.html.
Возьмем в качестве примера следующий файл. Сохраните его в рабочей директории с названием books.xml .
В этом примере структура файла будет конвертирована и преподнесена в виде Dataframe . В первую очередь нужно импортировать субмодуль objectify из библиотеки.
Теперь нужно всего лишь использовать его функцию parse() .
Результатом будет объект tree, который является внутренней структурой данных модуля lxml .
Чтобы познакомиться с деталями этого типа, пройтись по его структуре или выбирать элемент за элементом, в первую очередь нужно определить корень. Для этого используется функция getroot() .
Теперь можно получать доступ к разным узлам, каждый из которых соответствует тегам в оригинальном XML-файле. Их имена также будут соответствовать. Для выбора узлов нужно просто писать отдельные теги через точки, используя иерархию дерева.
В такой способ доступ к узлам можно получить индивидуально. А getchildren() обеспечит доступ ко всем дочерним элементами.
При использовании атрибута tag вы получаете название соответствующего тега из родительского узла.
Русские Блоги
Программы TensorBoard и TensorFLow выполняются в разных процессах.TensorBoard автоматически прочитает последний файл журнала TensorFlow и представит последний статус текущей запущенной программы TensorFLow.
2. Процесс использования TensorBoard
- Добавить узел записи: tf.summary.scalar/image/histogram() Подождите
- Узел сводной записи: merged = tf.summary.merge_all()
- Запустите сводный узел: summary = sess.run(merged) , Получите сводный результат
- Создание экземпляра модуля записи журнала: summary_writer = tf.summary.FileWriter(logdir, graph=sess.graph) , При создании экземпляра передайте график и запишите текущий график вычислений в журнал
- Объект экземпляра модуля записи журнала вызовов summary_writer из add_summary(summary, global_step=i) Метод записи всех сводных журналов в файл
- Объект экземпляра записи журнала вызовов summary_writer из close() Метод записи в память, иначе пишет каждые 120 с
Два, визуальная классификация TensorFlow
1. Визуализация графика расчета: add_graph ()
# Launch the graph in a session.
# Create a summary writer, add the ‘graph’ to the event file.
writer = tf.summary.FileWriter(logdir, sess.graph)
Writer.close () # Запись в память при закрытии, иначе будет записываться каждые 120 секунд
2. Визуализация индикаторов мониторинга: add_summary ()
-
Во время процесса обучения визуализации, уровень точности (val acc), значение потерь (потеря обучения / теста), скорость обучения (скорость обучения), статистика веса и смещения каждого слоя (среднее, стандартное, макс. / Мин.) ) И т.д.
-
Входные параметры:
- name: имя узла операции, вертикальная ось графика, нарисованного в TensorBoard, также будет использовать это имя
- тензор: переменная, которая должна отслеживаться. Настоящий числовой тензор, содержащий одно значение.
- A scalar Tensor of type string. Which contains a Summary protobuf.
-
Визуализация Текущий раунд Обучающие / тестовые изображения или карты функций, используемые для обучения
-
Входные параметры:
- name: имя этого рабочего узла, вертикальная ось графика, нарисованного в TensorBoard, также будет использовать это имя
- tensor: A r A 4-D uint8 or float32 Tensor of shape [batch_size, height, width, channels] where channels is 1, 3, or 4
- max_outputs:Max number of batch elements to generate images for
- A scalar Tensor of type string. Which contains a Summary protobuf.
-
Визуализируйте распределение значений тензора
-
Входные параметры:
- name: имя узла операции, вертикальная ось графика, нарисованного в TensorBoard, также будет использовать это имя
- tensor: A real numeric Tensor. Any shape. Values to use to build the histogram
- A scalar Tensor of type string. Which contains a Summary protobuf.
- Merges all summaries collected in the default graph
- Поскольку в программе определено множество операций записи журналов, вызывать их по очереди очень сложно, поэтому TensoorFlow предоставляет эту функцию для организации всех операций создания журналов, например: merged = tf.summary.merge_all ()
- Эта операция не будет выполнена сразу, поэтому вам нужно явно запустить эту операцию ( summary = sess.run(merged) ) Чтобы получить итоговый результат
- Наконец, вызовите объект экземпляра записи журнала add_summary(summary, global_step=i) Метод записи всех сводных журналов в файл
3. Визуализация нескольких событий: add_event ()
- Если подкаталог каталога logdir содержит данные из другого запуска (несколько событий), то TensorBoard отобразит все данные запуска (в основном скалярные), которые можно использовать для сравнения эффекта модели при различных параметрах и настройки параметров модели. , Пусть добьется наилучшего эффекта!
- Верхняя строка — это график потерь с 200 итерациями, а нижняя — график с 400 итерациями. См. Конец процедуры.

В-третьих, украсьте граф вычислений с помощью пространства имен
- Используйте пространства имен, чтобы сделать визуализацию более иерархической, чтобы общая структура нейронной сети не была перегружена слишком большим количеством деталей.
- Все узлы в одном пространстве имен будут сокращены до одного узла, и только узлы в пространстве имен верхнего уровня будут отображаться в визуализации TensorBoard.
- доступный tf.name_scope() или tf.variable_scope() Подробности см. В заключительной процедуре.
4. Запишите все журналы в файл: tf.summary.FileWriter ()
- Отвечает за запись журналов событий (график, скаляр / изображение / гистограмма, событие) в указанный файл
-
Параметры инициализации:
- logdir: каталог, в который записано событие
- график: если передано во время инициализации sess,graph Эквивалентно вызову add_graph() Метод визуализации вычислительного графа
- flush_sec:How often, in seconds, to flush the added summaries and events to disk.
- max_queue:Maximum number of summaries or events pending to be written to disk before one of the ‘add’ calls block.
- add_event(event) :Adds an event to the event file
- add_graph(graph, global_step=None) :Adds a Graph to the event file,Most users pass a graph in the constructor instead
- add_summary(summary, global_step=None) : Добавляет буфер итогового протокола в файл событий, обязательно передайте global_step
- close() :Flushes the event file to disk and close the file
- flush() :Flushes the event file to disk
- add_meta_graph(meta_graph_def,global_step=None)
- add_run_metadata(run_metadata, tag, global_step=None)
5. Запустите TensorBoard, чтобы отобразить все диаграммы журнала.
1. Запускаем cmd под Windows
- Запустите вашу программу в указанном каталоге ( logs ) Создать event файл
- В logs В каталоге нажмите и удерживайте shift Кнопка, щелкните правой кнопкой мыши и выберите открыть здесь cmd
- В cmd , Введите следующую команду, чтобы начать tensorboard —logdir=logs Примечание. Каталог журналов указывать не нужно. Если в журналах есть несколько событий, будет сгенерирован сравнительный скалярный график, но на графике будут отображаться только последние результаты.
- Поместите сгенерированный URL ниже ( http: // DESKTOP-S2Q1MOS: 6006 # Все могут быть разными ) Скопируйте в браузер, чтобы открыть
Интеллектуальная рекомендация
Реализация JavaScript Hashtable
причина Недавно я смотрю на «Структуру данных и алгоритм — JavaScript», затем перейдите в NPMJS.ORG для поиска, я хочу найти подходящую ссылку на библиотеку и записывать его, я могу исполь.
MySQL общие операции
jdbc Транзакция: транзакция, truncate SQL заявление Transaction 100 000 хранимая процедура mysql msyql> -определить новый терминатор,Пробелов нет mysql>delimiter // mysql> -создание хранимой .
Используйте Ansible для установки и развертывания TiDB
жизненный опыт TiDB — это распределенная база данных. Настраивать и устанавливать службы на нескольких узлах по отдельности довольно сложно. Чтобы упростить работу и облегчить управление, рекомендуетс.

Последняя версия в 2019 году: использование nvm под Windows для переключения между несколькими версиями Node.js.
С использованием различных интерфейсных сред вы можете переключаться между разными версиями в любое время для разработки. Например, развитие 2018 года основано наNode.js 7x версия разработана. Тебе эт.

Шаблон проектирования — Создать тип — Заводской шаблон
Заводская модель фабрикиPattern Решать проблему: Решен вопрос, какой интерфейс использовать принципСоздайте интерфейс объекта, класс фабрики которого реализуется его подклассом, чтобы процесс создания.
Как в tensoboard прочитать файл
I’ve run several training sessions with different graphs in TensorFlow. The summaries I set up show interesting results in the training and validation. Now, I’d like to take the data I’ve saved in the summary logs and perform some statistical analysis and in general plot and look at the summary data in different ways. Is there any existing way to easily access this data?
More specifically, is there any built in way to read a TFEvent record back into Python?
If there is no simple way to do this, TensorFlow states that all its file formats are protobuf files. From my understanding of protobufs (which is limited), I think I’d be able to extract this data if I have the TFEvent protocol specification. Is there an easy way to get ahold of this? Thank you much.
9 Answers 9
As Fabrizio says, TensorBoard is a great tool for visualizing the contents of your summary logs. However, if you want to perform a custom analysis, you can use tf.train.summary_iterator() function to loop over all of the tf.Event and tf.Summary protocol buffers in the log:
You need to import it, that module level is not currently imported by default. On 2.0.0-rc2