Сколько операций в секунду выполняет c
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | B enq | 3783 |
| 2 | j iangly | 3772 |
| 3 | t ourist | 3706 |
| 4 | m aroonrk | 3609 |
| 5 | U m_nik | 3591 |
| 6 | f antasy | 3526 |
| 7 | k o_osaga | 3500 |
| 8 | i naFSTream | 3477 |
| 9 | c nnfls_csy | 3427 |
| 10 | z h0ukangyang | 3423 |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | awoo | 181 |
| 1 | U m_nik | 181 |
| 3 | -is-this-fft- | 172 |
| 3 | nor | 172 |
| 5 | adamant | 167 |
| 6 | m aroonrk | 165 |
| 7 | antontrygubO_o | 161 |
| 8 | SecondThread | 160 |
| 9 | YouKn0wWho | 155 |
| 10 | kostka | 153 |
AAK → Indian ICPC 2022-23 Regionals — Discussion
GlebsHP → Nebius Welcome Round Editorial
MateoCV → Codeforces Round 856 (Div. 2)
adamant → Unexpected application of cosines
GlebsHP → Nebius Welcome Round (Div. 1 + Div. 2, rated, t-shirts!)
shivanshsingh9670 → Help in a question
SsToRR → Blog about Tourist
m aroonrk → AtCoder Regular Contest 158 Announcement
hahazhou → Codeforces Round 863 (Div. 2)
chokudai → AtCoder Beginner Contest 293 Announcement
arius1408 → How to know if a number N is divisible by k ? ( N <= 10^5000000) ?
Vladosiya → Codeforces Round 855 (Div. 3) Разбор
vk705017 → why i am getting TLE ?
Diegogrc → Companies interested in hiring a Competitive Programming background eng?
nor → [Tutorial] Floors, ceilings and inequalities for beginners (with some programming tips)
Pakgamer2022 → Need Help!
-Ahmed_-_Elsayed- → Is using AI during contests to summarize the problem illegal ?
appu_nitd → Invitation to Decathlon 2023
arvindr9 → arvindr9 Stream 10
rahulgoel → Editorial for CodeCraft-22 and Codeforces Round #795 (Div. 2)
joyfullife → Getting MLE, help needed.
adamant → The 1st Universal Cup. Stage 7: Zaporizhzhia
programmerror → Convincing My Country to Participate in IOI
xyz_000 → CHelper with Latest version of IntelliJ
pRaVsha → Погода сегодня
Блог пользователя N_B_B
Автор N_B_B, 12 лет назад ,
 c++, operation
c++, operation
Комментарии (13)
Зависит от языка программирования. Зависит от типа операций. Зависит от компьютера.
Используйте запуск чтобы посмотреть время работы своей программы на сервере.
Предельная производительность: C#
 Я поделюсь 30 практиками для достижения максимальной производительности приложений, которые этого требуют. Затем, я расскажу, как применил их для коммерческого продукта и добился небывалых результатов!
Я поделюсь 30 практиками для достижения максимальной производительности приложений, которые этого требуют. Затем, я расскажу, как применил их для коммерческого продукта и добился небывалых результатов!
Приложение было написано на C# для платформы Windows, работающее с Microsoft SQL Server. Никаких профайлеров – содержание основывается на понимании работы различных технологий, поэтому многие топики пригодятся для других платформ и языков программирования.
Предисловие
Всё началось в далёком 2008 году – тогда я начал заниматься задачами сравнения и репликации реляционных баз данных. Такого рода приложения в первую очередь требуют высокого качества исполнения, т.к. потеря или порча данных может обернуться катастрофой. Во-вторых, размеры баз могут достигать сотни и тысячи гигабайт, поэтому от приложения требуется высокая производительность.
Основной упор делался на SQL Server, а так как Microsoft давно отказались от нормальной поддержки ODBC драйвера и предоставляют полный функционал только в ADO .NET provider, то приложение необходимо было писать на одном из языков для .NET Framework. Конечно сочетание High Performance Computing и платформа .NET как минимум вызывает улыбку, но не спешите с выводами.
Когда продукт был готов, результаты превзошли все ожидания, и производительность в разы превосходила лучшие решения на рынке. В данной статье я хочу поделиться с вами основными принципами, которых стоит придерживаться при написании высокопроизводительных приложений.
Принципы оптимизации
Все принципы сгруппированы в категории, а их описание может содержать утверждения без объяснения, однако все они основаны на фактах и исследованиях, которые можно легко найти в интернете.
Каждый из пунктов содержит краткую информацию, которая отображает основную суть. Некоторые детали могут быть не освещены из-за насыщенности материала, а по каждому из пунктов можно писать отдельную статью. Поэтому я настоятельно рекомендую ознакомиться с деталями каждого пункта самостоятельно из любых доступных источников, перед применением их на практике. Неверное понимание изложенного материала и пробелы в знаниях могут привести как минимум к ухудшению производительности вашего приложения.
Все примера кода являются тривиальными, и демонстрируют исключительно основную суть, а не решают конкретную задачу.
1. Хороший алгоритм.
В первую очередь, для проблемы необходимо подобрать наилучший алгоритм её решения. Только после этого можно заниматься оптимизацией. Если алгоритм выбран неправильно, никакая оптимизация не поможет.
Углублённые познания работы различных технологий – основа всех приёмов оптимизаций. И эти знания помогают в выборе алгоритма из нескольких возможных.
2. План действий.
Если вы чётко сформируете все задачи, который выполняет алгоритм, во-первых, вам будет легче понять и реализовать алгоритм, во-вторых вы сможете построить граф действий – так вы узнаете чёткий порядок их выполнения и какие действия можно выполнять параллельно.
3. Микро-задержки.
Есть некая операция, время выполнения которой занимает F секунд. Если уменьшить это время всего на 1 микросекунду, то за 100 миллионов итераций вы получите выигрыш в 100 секунд! Такие частые операции – первый кандидат для оптимизации.
Ветвление кода
4. Не используйте «if», когда всё заранее известно.
Таким образом, мы проверяем типы данных в полях только один раз при инициализации, а не на каждой записи, что очень положительно отражается на производительности. К тому же, если какой-то тип данных не поддерживается вашим кодом, то вы получите ошибку сразу, а не после чтения миллионной записи. Думаю, про вредность Boxing / Unboxing в этом примере не стоит рассказывать, и надеюсь, вы догадываетесь как это исправить.
5. Вторая причина не использовать «if».
Любой современный процессор – это не «набор транзисторов», который тупо выполняют указанные команды. Процессор – это очень сложное технологическое устройство, в котором есть свои трюки для оптимизации выполнения инструкций.
Instruction Scheduling – один из видов оптимизации, который позволяет параллельно выполнять инструкции. Представьте код:
Инструкции, вроде как идут последовательно, но данные между первым и вторым выражением никак не связаны между собой. Это значит, что ещё на этапе компиляции можно задействовать все регистры общего назначения, при этом процессор сможет выполнить операции с этими регистрами практически параллельно. А вот третье и четвёртое выражения уже имеют зависимые данные, и тут оптимизировать не получится.
Польза от параллельности очевидна, и сейчас я объясню как это связано с «if». Дело в том, что когда процессор встречает условный переход, то он заранее не может знать выполнится ли условие или нет, поэтому об эффективности оптимизаций с выполнением инструкций параллельно можно забыть, не смотря на то, что есть такие техники как Branch prediction.
Вот вам задачка: как сравнить два байта без использования оператора «if»? Метод должен возвращать -1, 0, или 1, а его сигнатура: int CompareBytes(byte a, byte b)
Сам по себе этот подход работает быстрее, чем его аналог с двумя «if». Но для данного примера компилятор лучше оптимизирует программу в целом, если будет использоваться «if» с прямым вызовом метода (без делегатов и без виртуализации). Тем не менее, такого рода подход в определённых местах может сократить время выполнения программы.
6. Эффективные циклы.
- Никаких «foreach» – эта конструкция может создать экземпляр класса, который реализует интерфейс IEnumerable (чем плохо, описано в принципах 16 и 23).
- Никогда не объявляйте переменные типами IList или IEnumerable, если вы знаете точный тип коллекции (см. принцип 24). Можно воспользоваться «var».
- По возможности, используйте встроенные массивы, а не класс List. Это связано с проверкой границ массива в индексаторе, которые сказываются на производительности. Единственный способ избежать этих проверок, написать «for» таким образом:
- Обращайтесь к элементу массива только один раз – больше шансов, что значение будет помещено только в регистр общего назначения (без лишних обращений к памяти), а также избежите лишних проверок границ массива (если таковые имеют место).
7. Разматывайте циклы.
Этот метод может привести к ухудшению производительности в некоторых случаях, поэтому требует особой аккуратности. Советую почитать для начала «Loop unwinding» на Wikipedia.
Асинхронные задачи
8. Примитивы синхронизации.
В главном потоке программы можно создать таймер, который периодически опрашивает прогресс выполнения задачи и отображает его в UI. Если бы у переменной «progress» не было модификатора «volatile», то была бы вероятность, что актуальное её значение в итерациях цикла будет храниться только в регистре процессора и для главного потока она будет всегда 0. Такой подход к чтению прогресса избавляет от надобности синхронизации потоков, которая замедляет выполнение асинхронной задачи, и тем более от ужасной методики рассылки событий на каждое изменения значения прогресса.
9. Задачи и ресурсы.
- первая считает общее количество бит в большом массиве данных в памяти
- вторая читает данные из сетевого протокола, и пишет на диск
- а третья шифрует небольшое значение с помощью AES-256
10. Пакетная обработка.
11. Переключение контекста.
Вы знаете, почему потоки могут работать «параллельно» даже, если у процессора всего одно ядро? Каждая программа имеет изолированную от других память (виртуальная память), но все они используют одни и те же регистры процессора для выполнения инструкций. Чтобы дать возможность использования регистров процессора «параллельно», придумали технику переключения контекста – сохранение состояния регистров в оперативную память при остановке выполнения программы, чтобы можно было их позже восстановить для продолжения выполнения. Т.е. система выполняет часть инструкций одной программы, сохраняет её состояние, потом загружает состояние другой программы, выполняет немного её инструкций, потом опять сохраняет состояние, и так далее. Таким образом, система много раз в секунду переключается с программы на программу, что даёт эффект «параллельности выполнения».
Переключение контекста – довольно тяжеловесная операция, поэтому слишком большое кол-во потоков ведёт к деградации производительности. Чем меньше приходится потоков на одно физическое ядро процессора, тем меньше происходит переключений контекста, тем быстрее работает система в целом.
Во избежание переключения контекста, можно привязать потоки к конкретным физическим ядрам/процессорам. Для процессов есть свойство Process.ProcessorAffinity (общая маска для всех потоков процесса), а для потоков можно использовать ProcessThread.ProcessorAffinity.
Для контроля выделения времени выполнения потоков есть приоритет – свойство Thread.Priority. Чем больше приоритет, тем больше выделяется процессорного времени на выполнение инструкций. Также есть приоритет у процессов в системе – Process.PriorityClass.
Дисковое хранилище и сети
12. Выравнивание по размеру кластера.
В сетевых протоколах передачи данных используется термин MTU (Maximum Transmission Unit) для определения размера блока данных для передачи. Но ситуация обстоит несколько сложней и остаётся для самостоятельного изучения.
13. Асинхронная запись.
Кто же не писал код, в котором в Stream последовательно записываются байты… Что в этом плохого? Давайте рассмотрим, что происходит внутри. Если помнить, что FileStream использует внутреннюю буферизацию, то всё хорошо, пока буфер заполняется. Как только он заполнился, всё его содержимое скидывается на диск. Но кто сказал, что эта операция мгновенна? (особенно если это HDD на вэб-сервере.) Поэтому, поток программы останавливается, и ждёт завершения записи. И так каждый раз когда, когда буфер полностью заполняется.
Для устранения этих задержек достаточно создать свой класс Stream, который накапливает данные в буфер, а потом ставит его в очередь на запись в отдельном потоке. Пока первый буфер стоит в очереди и собственно записывается, можно уже наполнять второй буфер (см. принцип №9). Таким образом, ожидание окончания записи заменяется задержкой синхронизации потоков. И только при закрытии Stream остаётся дождаться окончания записи в другом потоке – это необходимо для обработки ошибок. А для конечного пользователя это будет тот же прозрачный интерфейс класса Stream. По-моему, отличный выигрыш! Только не стоит забывать, что это работает только для больших файлов. Если данные занимают пару кластеров, этот подход не имеет смысла.
Также подумайте о более существенных задержках, которые возникают при передаче данных по сети (например, с использованием NetworkStream).
14. Чтение наперёд.
Как и при записи (принцип №13), чтение кластера с диска занимает время. Если стоит задача прочитать большой файл последовательно от начала до конца, то можно аналогично организовать асинхронное чтение файла наперёд во внутренние буферы. Пока один из буферов используется, в следующий происходит чтение соседнего кластера. При этом так же сохраняется прозрачность интерфейса Stream.
И не забываем о насущности проблемы при чтении данных из сетевого интерфейса.
15. Сжатие данных.
- Необходимо записать/прочитать меньше байт. Линейное уравнение отношения объёма к скорости даёт меньшее время.
- Меньше данных = меньше кластеров = меньше IO операций
Управление памятью
16. Структуры, а не классы.
- Структуры занимают меньше места в памяти, т.к. у них нет заголовка описывающий тип данных, указателей на таблицы виртуальных методов, а так же другие поля, необходимые для синхронизации и сборки мусора.
- Структуры хранятся в stack’е (но в куче, если массив). Выделение памяти в stack’е происходит очень быстро: stack – заранее выделенный буфер памяти, в котором просто резервируется место по размеру структуры (в основном, на этапе компиляции) путём уменьшения значения в stack pointer (уменьшения, т.к. данные в stack’е хранятся задом-наперёд). Когда функция завершает свою работу, то «освобождение» всех переменных в stack’е происходит один махом путём увеличения указателя stack pointer на количество байт, необходимых для переменных. А выделение и освобождение памяти в куче – это огромное количество операций, в отличие от простого вычитания и суммирования.
- Из-за того, что структуры хранятся в stack’е, они не требуют сборки мусора. Это сильно разгружает сборщик мусора и избавляет от проблемы фрагментации памяти.
- Структуры, поля которых – только value types, легко сериализовать в массив байт и обратно.
17. Освобождение памяти.
Не смотря на автоматическое освобождение памяти в .NET Framework, не стоит забывать, как работает сборка мусора. Все объекты представляются как вершины графа, а ссылки на объекты – как его рёбра. Для простоты (хоть это не так), самой первой вершиной графа можно считать класс, который определяет точку входу в приложение (с функцией main). Как только некие рёбра графа всех объектов будут убраны так, что образуется два несвязанных графа, то объекты того, который не связан с точкой входа, можно удалить из памяти.
Поскольку рёбра графа представляются ссылками, то удаление рёбер можно считать установку ссылки в значение «null». Если вы забываете это делать, ваши объекты будут переживать сборку мусора и переходить из поколения в поколение, увеличивая общий расход памяти приложением.
Здесь можно вывести для себя очень простое правило – как только объект перестаёт быть нужным, обнулите ссылку на него.
18. Повторное использование памяти.
На уровень ниже
19. «unsafe» и указатели.
Код с пометкой «unsafe» позволяет в C# использовать указатели, и это открывает широкие возможности для оптимизации. Вы можете интерпретировать массив байт как угодно – как массив int или структур Guid, вы забываете про проверки границ массива, вы можете выравнивать адреса в памяти, и т.п. Без использования unsafe кода никак не получится максимально оптимизировать приложение, которое интенсивно работает с большими объёмами данных в памяти.
20. Компактное хранение.
Очень часто структуры содержат данные, которые можно легко вычислить. Поэтому, стоит задуматься о балансе между вычислением значения поля «на лету» и использовании памяти для хранения значений таких полей в каждом элементе массива.
И, вдобавок, если много элементов массива имеют поле с абсолютно одинаковыми значениями, то можно сгруппировать такие элементы и хранить значение в группе, а не в поле каждого элемента.
21. Выравнивание в памяти.
Представьте себе структуру данных:
Общий её размер составляет 5 байт. Скажем, у вас есть массив S[], и некая функция в цикле что-то делает с полем «b». Предположим, что оператор «new» выделил кусок памяти для массива, и указатель на первый элемент равен 0x100000 – здесь я просто хочу подчеркнуть, что адрес является степенью двойки, или, по крайней мере, кратен 4 или 8. Теперь для первого элемента в массиве адрес для поля «b» будет 0x100001, для второго – 0x100006, третьего – 0x10000B, и т.д. Некоторые архитектуры процессоров требуют, чтобы адреса для чтения или записи были кратны размеру машинного слова – это и называется «выровненный адрес». Для архитектур x86 и x86-64 (где размер машинного слова 4 и 8 байт соответственно) таких требований нет, однако чтение и запись по выровненным адресам дают лучшую производительность.
Для выравнивания структур данных используется метод padding – добавление лишних байт, чтобы все размеры всех полей структуры были кратны указанному числу байт. Если выровнять нашу структуру на 4 байта, то получится:
Чтобы не писать всё это руками, в .NET Framework есть StructLayoutAttribute. Имейте в виду, выравнивание может очень негативно обернуться для производительности – добавляя лишние байты, размер данных может сильно увеличиться, что приводит к большему количеству обращений к памяти.
Тут есть и ещё интересная сторона. Практически все знают, что у процессоров есть внутренний кэш, да и ещё нескольких уровней. Но далеко не все знают, как он работает. Вкратце, есть так называемые cache lines – небольшие блоки памяти (например, 32 байта), в которые записываются данные из оперативной памяти по выровненному адресу (на размер кэш линии). Если взять наш пример со структурой «S» размером 5 байт, то процедура, которая в цикле последовательно обращается к данным элементов массива, будет на самом деле читать первые 6 элементов из кэша процессора (при размере кэш-линии в 32 байта; я имею в виду, что процессор это будет делать, кэш-то у него). Для седьмого элемента первые два байта структуры хранятся в последних двух байтах кэш-линии, а остальные три байта структуры – в физической памяти. При чтении происходит кэш-промах, и тогда процессору приходится читать данные из физической памяти, что намного медленнее чтения из кэша. Из этого следует, чем больше будет обращений к кэшированной памяти, тем быстрее будет работать приложение. В вопросе «PInvoke for GetLogicalProcessorInformation» на StackOverflow вы можете взять код для получения размера кэш линий.
Вторая, не менее интересная сторона, заключается в понимании как происходит выделение физической памяти. Каждый процесс имеет свою виртуальную память, которая неким образом соотносится с реальной физической памятью. В распространённой модели постраничной фрагментации памяти, где каждая страница памяти обычно занимает 4 KiB, последовательная виртуальная память размером 8 KiB может ссылаться на две НЕпоследовательные страницы физической памяти. Помните «файл подкачки»? Как вы думаете, какими кусками Windows записывает туда и считывает оттуда память? Так что выравнивание адресов в памяти на размер страницы иногда может быть большим плюсом.
22. Преимущества x86-64.
Две операции вместо 11 – по-моему, очень хорошо!
23. Вызов функций.
- Безусловный переход по адресу в памяти.
- Запись и чтение адреса из stack’а для CALL/RET.
- Запись и чтение аргументов метода из stack’а.
- Задержкам, связанным с обращением к памяти. А операции с регистрами выполняются намного быстрее.
- Невозможности эффективно использовать регистры процессора при компиляции IL в родной код.
- Отсутствию возможности для процессора проанализировать инструкции наперёд и выполнить их параллельно (из-за JMP-подобных инструкций).
Если помнить, что структура Guid занимает 16 байт, то при вызове такого метода в stack будет записано 32 байта, чтобы передать аргументы g1 и g2. Вместо этого, вы можете написать:
И тогда, для каждого аргумента будет передан указатель на него, а не его значение, и это будет 4 байта для 32-разрадного процесса, и 8 байт для 64-разрадного процесса. Более того, появится вероятность, что адреса на аргументы будут переданы через регистры процессора, а не stack (в зависимости от соглашения вызова).
Пример 2. Тривиальный метод, который умножает два числа, и метод, который его вызывает:
Если бы метод Foo просто делал умножения вместо вызова метода Multiply, тогда бы значения a и b просто были помещены в регистры процессора и умножены. Вместо этого мы заставляем компилятор генерировать лишний код, который делает кучу операций с памятью, да и ещё безусловный переход! А если метод вызывается миллионы раз в секунду? Вспомните про принцип №3.
Поэтому в таких языках, как C++ есть модификатор метода inline, который указывает компилятору, что тело метода необходимо вставить в вызывающий метод. Правда, и в .NET Framework только с версии 4.5 наконец-то можно делать inline методы (в предыдущих версиях невозможно было форсировано делать inline — только на усмотрение компилтора). А если говорить о микроконтроллерах, код для которых пишется на assembler, то там зачастую вообще запрещены вызовы функций. Хочешь выполнить код функции – делай Copy Paste.
Только не спешите переписывать код вашей программы в одну большую функцию – это приведёт к раздутию кода, которое сделает приложение ещё медленнее.
24. Виртуальные функции.
Мы сделали класс «Y» закрытым для наследования, и написали два метода, которые вызывают метод «B» класса «Y». В методе Slow мы объявляем тип переменной как «X», и при вызове метода «B» у экземпляра класса «Y» компилятор генерирует код обращения к виртуальной таблице, потому что класс «X» открыт для наследования.
Напротив, в методе Fast компилятор знает, что класс «Y» закрыт для наследования, а также он знает, что этот класс переопределят метод «B». И это говорит ему, что неоднозначных ситуаций здесь быть не может, есть только единственный метод «B» класса «Y», который будет вызван в таком случае. Поэтому, надобность в обращении к виртуальной таблице отпадает, не смотря на то, что метод «B» виртуальный. В таких случаях компилятор сгенерирует код прямого вызова метода «B», что положительно скажется на производительности.
Трюки и уловки
25. Reverse engineering.
Иногда производительность приложения упирается в третесторонние компоненты, на которые вы не можете никак повлиять. Или всё-таки можете. Приведу реальный пример, SqlDataReader в методе GetValue для колонки с типом данных «xml» в конечном итоге вернёт вам String либо XmlReader. А задача состоит в том, чтобы сравнить два значения типа «xml» из двух разных источников. Вроде бы ничего особенного – взял да и сравнил две строки, да ещё можно использовать StringComparison.Oridnal чтоб вообще быстро было. Однако если копнуть глубже, и посмотреть в реализацию SqlDataReader, то можно узнать что на самом деле XML данные приходят клиенту в бинарном формате. Это значит, что конвертация таких данных в строку требует дополнительных ресурсных затрат, немалых затрат. Но если потрать время и покопаться в реализации, то можно заставить SqlDataReader думать (с помощью рефлексии), что вместо «xml» ему приходит обычный тип «varbinary». Таким образом, вам теперь просто необходимо проверить два массива байт на равенство, и никаких конвертаций. Конечно, если два массива отличаются, и вы хотите сравнить XML без учёта пробелов, комментариев, и регистра символов, то достаточно (с помощью той же рефлексии) создать два XmlReader на основе полученных байт, и сравнивать элементы XML.
26. Лишние действия.
Если вы играли в какую-нибудь 3D компьютерную игру, и случайно (или специально) попали за предел уровня, то вы, скорее всего, видели что пустое пространство ни чёрное и ни белое, а содержит мусор от предыдущих кадров. Этот эффект является результатом оптимизации игрового движка.
В 3D графике результат отрисовки 3D мира помещается в некий буфер кадра. Если вы загляните в любой туториал для начинающих, то там будет примерно такой код: залить буфер кадра белым или чёрным цветом, нарисовать 3D модель. В таких примерах заливка цветом служит просто фоном, на котором посередине вращается какая-нибудь фигура.
А теперь вспомните любую игру. Вы помните хоть где-то монотонный фон? Особенно, если действия разворачиваются в секретном бункере нацистов. Из этого следует, что перед отрисовкой сцены нет никакого смысла заливать буфер кадра каким-либо цветом, пусть там остаётся предыдущий кадр – всё равно весь кадр будет перетёрт новым изображением. А ведь Full HD (1920×1080) кадр с 32-битной глубиной цвета – это почти 8 MiB! И чтобы залить все однородным цветом, тоже нужно время. Хоть и небольшое, но нужно, причём делать это надо на каждом кадре (а их может быть около 100 в секунду). Таким образом, отсутствие элементарного бесполезного действия очень позитивно сказывается на FPS в игре.
Как это относится к .NET Framework? На самом деле, это относится к любой программе, написанной на любом языке. Вся операционная система просто кишит кучей бесполезных действий, которые выполняются тысячи раз в секунду. Но это отдельная тема, поэтому остановимся на тривиальном примере – оператор new. При создании нового экземпляра класса все его поля установлены в 0 или null, а в массиве все элементы тоже установлены в 0. Мы принимаем это как должное, и должен согласиться да – это очень удобно, и если бы значения были случайными, то это привело бы к множествам ошибок. На самом деле, на уровне системы память выделяется в таком виде, какой была освобождена – при освобождении никто не заботится об обнулении байт. Т.е. платформа .NET в пользу удобности делает действия, которые обычно лишние при выделении больших блоков памяти. Зачем инициализировать массив байт в ноль, если такой буфер будет заполнен данными с диска?
Решением могло бы стать использование GlobalAlloc (без флага GMEM_ZEROINIT) и GC.AddMemoryPressure, но при оптимальном подходе операция выделения памяти не будет слишком частой, поэтому инициализацией в 0 можно пренебречь. Речь в этом пункте, конечно же, не о памяти, а о выполнении бесполезных действий, так что суть вы уловили.
Изобретение велосипеда
27. Реализация «Format» и «ToString».
Не заставляйте программу искать куда и в каком виде вы хотите вставить строковое значение при использовании String.Format, если вы заранее знаете. Перепишите код на String.Concat или StringBuilder – будет быстрее. Лучше не представлять сколько действий выполняется, чтобы найти в строке “<0>” и подставить значение в указанном формате.
Для особого класса задач, можно и заняться реализацией ToString. Например, в разработанном приложении для формирования DML инструкций (INSERT/UPDATE/DELETE; во второй части статьи я объясню что к чему) были написаны свои методы для конвертации значений всех типов данных SQL Server в строку, которые конечно-же не создавали новый объект String. Такая оптимизация дала прирост производительности в 3 раза!
28. Слияние алгоритмов.
Другим примером велосипеда станет самодельный лексер для языка T-SQL, который необходим был для подсветки синтаксиса в текстовом редакторе. При получении очередного токена типа identifier необходимо определить, является ли он ключевым словом. Организовать список всех ключевых слов проще всего в Hashset. Тогда, чтоб проверить является ли токен ключевым словом, достаточно написать:
- Метод «ToUpperInvariant» создаёт новый экземпляр String.
- Метод «ToUpperInvariant» сам по себе очень тяжеловесный в реализации.
- При совпадении хэш кодов, сравниваются две строки. Хоть и побайтно, но сравниваются.
И никаких новых экземпляров строк, никакой сложной логики ToUpper для code points, которые не могут быть использованы в ключевых словах, да и хэш код сразу готов. На самом деле тут можно всё ещё намного круче оптимизировать, но это уже выходит за рамки данного пункта.
29. Изобретайте и экспериментируйте!
- Генерировать скрипт на диск, при этом делать индексный файл, который указывает на смещение от начала файла до каждой строки в тексте.
- Сделать свой компонент text view, который не грузит всё в память, а запрашивает конкретные строчки для отображения (для этого нужен индексный файл).
- Делать лексический разбор скрипта асинхронно, уже после того как первые строчки будут отображены в text view. О своём прогрессе лексер сообщает text view, который обновляет раскраску текста.
- Лексер обычно имеет состояние, которые выражается простым целочисленным числом «int». Зная это состояние и позицию в тексте можно продолжать синтаксический разбор с указанной позиции. А чтобы не хранить все токены для каждой строчки, которая сейчас не отображается на экране, достаточно хранить состояние лексера на начало строки. Как только строку необходимо будет отобразить на экране, необходимо сделать её лексический разбор, используя известное состояние. Это происходит очень быстро, и экономит огромное кол-во памяти. Поэтому, задача асинхронного лексера – разобрать весь текст и сохранить состояние для каждой строки в том же индексном файле, который используется для хранения смещений строк от начала текста. Таким образом, на каждую строку в индексном файле приходится 8 байт: 4 – смещение, 4 – состояние.
30. Вопреки всему.
Хочу отметить немаловажный факт, что приложение после серьёзной оптимизации может измениться в архитектуре некоторых компонентов, причём это зачастую противоречит многим известным вам шаблонам проектирования. Вот утрированный пример – класс, который перемножает числа:
Во-первых, непонятно почему метод «Multiply» не принимает параметров, но возвращает некий результат умножения. Во-вторых, нарушена инкапсуляция. Именного такого рода, казалось бы, казусы могут иногда встречаться после тотальной оптимизации, причём они имеют серьёзную аргументацию. Хочу повторить, что этот пример просто показывает, как могут нарушаться понятия и принципы ООП, и не представляет особой ценности.
Если производительность крайне важна, не бойтесь изменять код до такой степени, что его можно назвать «вонючим». Однако имейте в виду, такие подходы очень плохо отражаются на простоте и понимании архитектуры, кода и его связанности, поддержки и развитию приложения, и зачастую ведут к большому кол-ву ошибок.
От слов к делу
Чтобы не быть голословным, я хочу показать, как применил все вышеописанные принципы (именно все, даже больше) при разработке движка сравнения и синхронизации, которая заняла у меня примерно 5 месяцев. К сожалению, я не могу рассказать обо всех секретах, раскрыть имя компании и имя продукта – статья не для рекламы. Чтобы не приводить просто цифры, вначале я хочу разъяснить для чего нужно такое приложение, и описать общий принцип его работы.
Сравнение и синхронизация баз
- Модель, которая описывает поведение и содержимое базы (таблицы, представления, процедуры, и т.д.; назовём эту часть database schema)
- Собственно данные базы, которые хранятся согласно модели (в основном, табличные данные; назовём эту часть database data)
Общий алгоритм
- Выбрать два источника данных для сравнения. В основном, источниками являются «живые» базы, однако это может быть и файл резервной копии, либо другой альтернативный источник.
- Построить программную модель схемы из выбранных источников. Для сравнения, необходимо знать какие таблицы есть в базе, какие у них колонки, и какие типы данных там хранятся.
- Настроить соответствие таблиц между двумя источниками. В каждой базе есть свой набор таблиц, и необходимо сравнивать таблицу Customers из первой базы с таблицей Customers из второй базы, таблицу Products – с таблицей Products, и так далее. Такое же соответствие необходимо установить между колонками в выбранных парах таблиц.
- Сравнить данные таблиц. В основном, сравнение происходит по ключевым колонкам – они отвечают за уникальность записи в таблице. В результате такого сравнения мы можем получить 4 основных набора записей:
• существующие только в первой таблице (нет схожих записей во второй)
• существующие только во второй таблице
• различные записи (данные отличаются в не-ключевых колонках)
• идентичные записи (данные во всех колонках идентичны)
Все эти записи (кроме идентичных), необходимо сохранить на локальный диск в некий кэш, который будет использован в следующих шагах. - Анализ сравнения, настройка синхронизации. На этом этапе пользователь может заняться анализом разницы, и выбрать таблицы и записи для частичной синхронизации, а также настроить различные опции для достижения желаемого результата. На этом этапе так же формируется план действий для синхронизации (удалить 10 записей там, обновить 5 записей тут, вставить 50 записей туда, и т.п.)
- Выполнение синхронизации. По построенному плану и кэшу записей из предыдущих шагов, формируется SQL скрипт, который применяет изменения. Его можно выполнять на лету по мере формирования, либо просто сохранить на диск для отложенного выполнения.
Быстродействие в цифрах
- Intel i7-2630QM (4 cores @ 2GHz, 2.9GHz in Turbo, 8 logical threads)
- 12 Gb RAM DDR3 @ 1333 MHz (9-9-9-24)
- Intel SSD X25-M 120 Gb (250 Mb/s read, 35000 IOPS; 100Mb/s write, 8600 IOPS)
- Microsoft SQL Server 2008 R2 Developer Edition 64-bit
- Windows 7 Ultimate x64
В итоге
Каждая задача требует индивидуального подхода, а оптимизация её решения включает комбинации различных концепций. Существует намного больше других принципов, которые не освещены в данной статье, некоторые из которых попросту не могут быть применимы к платформе .NET.
Есть много споров о сравнении быстродействия платформы .NET с приложениями, написанных на C++. За мою жизненную практику, в сложных алгоритмических задачах связка C++ и Assembler дают выигрыш от 1.5 до 2.5 раз по сравнению с C#. Это значит, что критические части можно выносить в unmanaged DLL. Однако на реальном примере я показал, что и на C# можно писать очень эффективный код.
И всё же не стоит досконально оптимизировать каждый кусок кода там, где это не требуется. Многие принципы ведут к усложнению архитектуры и понимания кода, а также поддержки и расширения вашего приложения, что выливается в кол-во потраченного времени. В данной статье я не призываю вернуться в каменный век, отказавшись от всех удобств платформы .NET, а просто хочу показать, как можно делать простые вещи сложно, но очень эффективно. Всегда вначале стоит определиться с целью приложения, требованиями к быстродействию и бюджетом, а потом решать как это реализовывать.
Очень хотелось по каждому из пунктов написать поподробнее, добавить кучу изображений и примеров для лучшего понимая, но тогда это получилась бы не статья, а книга. Тем не менее, я надеюсь, что она поможет в первую очередь тем, кто вообще не знает в какую сторону смотреть, если стоит задача оптимизации кода высокопроизводительного приложения.
Подробно и просто о процессорах для персонального компьютера

Терафлопс (TFLOPS) — величина, используемая для измерения производительности компьютеров, показывающая, сколько операций с плавающей запятой в секунду выполняет данная вычислительная система. 1 терафлопс = 1 триллион операций в секунду = 1000 миллиардов операций в секунду. Обычно имеются в виду операции над плавающими числами размера 64 бита в формате IEEE 754.
TFLOPS = 1012 FLOPS = 103 GFLOPS
Чтобы найти пиковую производительность ЭВМ R, терафлопс, нужно тактовую частоту F, МГц, умножить на число процессоров (процессорных ядер) n, домножить на количество инструкций с плавающей запятой на такт (4 для процессоров Core2 — 2 операции Float Multiple Add) и поделить на 1******0:
Так, например, пиковая производительность компьютера на базе двухъядерного процессора AMD Phenom 9500 sAM2+ с тактовой частотой 2,2 ГГц равна:
2200 МГц × 2 ядра × 4×10-6 = 17,6 млрд операций в секунду = 0,0176 терафлопс.
Для четырехядерного процессора Core 2 Quad Q6600:
2400 МГц × 4 ядра × 4×10-6 = 38,4 млрд операций в секунду = 0,0384 терафлопс.
Скопипастено с Википедии
Т.е. находите нужные данные для своего процессора, подставляете их в формулу и находите кол-во операций в секунду.
Для моего Intel Pentium 4:
3000 х 1 х 2 х 10-6 = 6 млрд операций в секунду = 0.006 терафлопс.

В конце прошлого века для описания мощных и производительных вычислительных машин применялся термин «суперкомпьютер». Такие устройства стоили очень дорого и были довольно громоздкими. Иногда суперкомпьютер занимал несколько комнат и требовал специальный температурный режим для работы.
Для оценки производительности и сравнения таких вычислительных машин ввели термин «FLOPS»
История появления процессора
Первые компьютерные процессоры, основу которых составляло механическое реле, появились в пятидесятых годах прошлого века. Спустя какое-то время появились модели с электронными лампами, которые в итоге были заменены на транзисторы. Сами же компьютеры представляли собой довольно габаритные и дорогостоящие устройства.
Последующее развитие процессоров свелось к тому, что было принято решение входящие в них компоненты, представить в одной микросхеме. Позволило осуществить данную задумку появление интегральных полупроводниковых схем.
В 1969 г. компания Busicom заказала двенадцать микросхем у Intel , которые они планировали использовать в собственной разработке – в настольном калькуляторе. Уже в то время разработчиков Intel посещала идея заменить несколько микросхем одной. Идею одобрило руководство корпорации, поскольку подобная технология позволяла существенно сократить расходы на производстве микросхем, при этом у специалистов появилась возможность сделать процессор универсальным для использования его в других вычислительных устройствах.

В результате чего появился первый микропроцессор Intel 4004, который выполнял 60 тыс. операций в секунду.
Логика микропроцессора
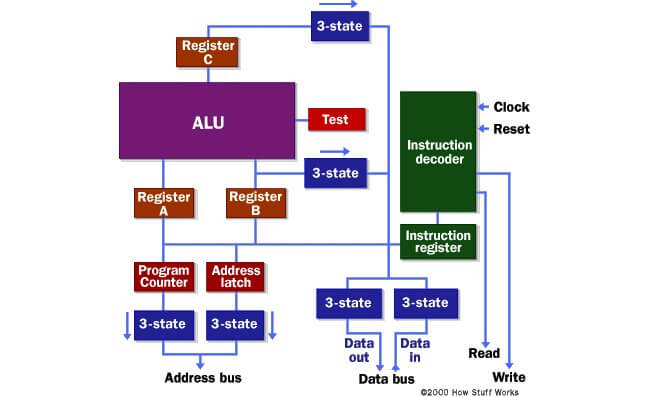
Чтобы понять, как работает микропроцессор, следует изучить логику, на которой он основан, а также познакомиться с языком ассемблера. Это родной язык микропроцессора.
Микропроцессор способен выполнять определенный набор машинных инструкций (команд). Оперируя этими командами, процессор выполняет три основные задачи:
- C помощью своего арифметико-логического устройства, процессор выполняет математические действия: сложение, вычитание, умножение и деление. Современные микропроцессоры полностью поддерживают операции с плавающей точкой (с помощью специального арифметического процессора операций с плавающей точкой)
- Микропроцессор способен перемещать данные из одного типа памяти в другой
- Микропроцессор обладает способностью принимать решение и, на основании принятого им решения, «перепрыгивать», то есть переключаться на выполнение нового набора команд
- Address bus (адресную шину). Ширина этой шины может составлять 8, 16 или 32 бита. Она занимается отправкой адреса в память
- Data bus (шину данных): шириной 8, 16, 32 или 64 бита. Эта шина может отправлять данные в память или принимать их из памяти. Когда говорят о «битности» процессора, речь идет о ширине шины данных
- Каналы RD (read, чтения) и WR (write, записи), обеспечивающие взаимодействие с памятью
- Clock line (шина синхронизирующих импульсов), обеспечивающая такты процессора
- Reset line (шина стирания, шина сброса), обнуляющая значение счетчика команд и перезапускающая выполнение инструкций
Поскольку информация достаточно сложна, будем исходить из того, что ширина обеих шин — и адресной и шины данных — составляет всего 8 бит. И кратко рассмотрим компоненты этого сравнительно простого микропроцессора:
- Регистры A, B и C являются логическими микросхемами, используемыми для промежуточного хранения данных
- Address latch (защелка адреса) подобна регистрам A, B и C
- Счетчик команд является логической микросхемой (защелкой), способной приращивать значение на единицу за один шаг (если им получена соответствующая команда) и обнулять значение (при условии получения соответствующей команды)
- ALU (арифметико-логическое устройство) может осуществлять между 8-битными числами действия сложения, вычитания, умножения и деления или выступать в роли обычного сумматора
- Test register (тестовый регистр) является специальной защелкой, которая хранит результаты операций сравнения, производимых АЛУ. Обычно АЛУ сравнивает два числа и определяет, равны ли они или одно из них больше другого. Тестовый регистр способен также хранить бит переноса последнего действия сумматора. Он хранит эти значения в триггерной схеме. В дальнейшем эти значения могут использоваться дешифратором команд для принятия решений
- Шесть блоков на диаграмме отмечены, как «3-State». Это буферы сортировки. Множество источников вывода могут быть соединены с проводом, но буфер сортировки позволяет только одному из них (в один момент времени) передавать значение: «0» или «1». Таким образом буфер сортировки умеет пропускать значения или перекрывать источнику вывода возможность передавать данные
- Регистр команд (instruction register) и дешифратор команд (instruction decoder) держат все вышеперечисленные компоненты под контролем
На данной диаграмме не отображены линии управления дешифратора команд, которые можно выразить в виде следующих «приказов»:
- «Регистру A принять значение, поступающее в настоящий момент от шины данных»
- «Регистру B принять значение, поступающее в настоящий момент от шины данных»
- «Регистру C принять значение, поступающее в настоящий момент от арифметико-логического устройства»
- «Регистру счетчика команд принять значение, поступающее в настоящий момент от шины данных»
- «Адресному регистру принять значение, поступающее в настоящий момент от шины данных»
- «Регистру команд принять значение, поступающее в настоящий момент от шины данных»
- «Счетчику команд увеличить значение [на единицу]»
- «Счетчику команд обнулиться»
- «Активировать один из из шести буферов сортировки» (шесть отдельных линий управления)
- «Сообщить арифметико-логическому устройству, какую операцию ему выполнять»
- «Тестовому регистру принять тестовые биты из АЛУ»
- «Активировать RD (канал чтения)»
- «Активировать WR (канал записи)»
В дешифратор команд поступают биты данных из тестового регистра, канала синхронизации, а также из регистра команд. Если максимально упростить описание задач дешифратора инструкций, то можно сказать, что именно этот модуль «подсказывает» процессору, что необходимо сделать в данный момент.
Компьютерный час
На этом этапе мы переходим от человеческих наносекунд к микросекундам: компьютерный час равен 1.44 мкс.
Может выполниться пузырьковая сортировка небольшого массива, когда-то написанная мной в образовательных целях. (вдумайтесь: если процессор каждую секунду делает по простому действию, то для сортировки маленького массива ему понадобятся часы!)
За десяток-другой часов процессор может запросить и получить данные у достаточно производительного SSD.
Сколько операций в секунду современный компьютер может выводить?

Если уже вы начали говорить о количестве операций в секунду, то могу сказать, что в этом случае мощность компьютеров меряется в flops, т.е в количестве операций с плавающей точкой в секунду (по простому что-то типа обычного десятичного числа, в форме типо 51,1535434 ). Почему именно числа с плавающей точной объяснять не буду, т.к. читать курс компьютерной арифметики нет желания
Для действительно огромных вычислений уже давно люди создали и до сих пор разрабатывают все более мощные «суперкомпьютеры». Их используют в специфических целях, например для прогноза погоды, моделирования ядерных взрывов, к примеру установив суперкомпьютер в систему водоснабжения, можно сделать так, что он будет проводить мониторинг, анализировать полученные данные и будет выявлять вероятные проблемы еще задолго до их возникновения.
На сегодняшний день самым мощным суперкомпьютером( ru.wikipedia.org/wiki/Суперком… ) является Jaguar( ru.wikipedia.org/wiki/Jaguar_(суперкомпьютер) ), его производительность( top500.org/lists/2009/11/press… ) 1.75 petaflop/s, а максимально теоретически возможная 2,3 петафлопс (приставка пета это *10^15, т.е. 1 750 000 000 000 000 операций с плавающей точкой в 1 секунду).
Только в случае суперкомпьютеров такое измерение производительности не всегда является корректным, т.к. количество операция в секунду зависит от типа задачи выполняемой этим компьютером, возможен такой вариант, что суперкомпьютеру для выполнения задачи нужно часто обращаться к периферийным устройствам(например проводить какой-то мониторинг, как с системой водоснабжения) или считывать, или записывать много информации, тогда у него явно будет производительность, измеряемая в флопсах ниже, т.к. это не основная его цель.
Современный настольный компьютер имеет производительность порядка 0.1 Терафлопс.
Но если говорить об обычных, настольных компьютерах, то здесь тоже количество операций в секунду не всегда решающий фактор, т.к. если компьютер предназначен для игр, то ему более важна производительность видеокарты, а не процессора. И опятьже это зависит от задачи, поставленной компьютеру. Серверные компьютерыы будут быстрее в этом плане, т.к. обычно напичканы более дорогими игрушками, да они и созданы для таких вещей. Сегодня при желании можно в компьютер поставить 2 восьмиядерных процессора (core i7).
Как повысить частоту?
Мало кто знает, но мощность процессора можно повысить. Как увеличить производительность CPU? Чтобы ответить на этот вопрос, нужно понять от чего она зависит. Тактовая частота прямо пропорциональна произведению множителя, который закладывается при проектировании, на частоту шины. Причем встречаются два вида множителей – заблокированные и открытые. Не трудно понять, что первые не поддаются разгону.

Процедура увеличения тактовой частоты проводится на устройствах с разблокированным множителем. Для того, чтобы произвести разгон необходимо обладать специальными знаниями, уметь работать с БИОС и знать английский язык (хотя бы уметь читать). Процедура увеличения частоты довольно-таки сложна и неопытные пользователи вряд ли смогут ее произвести без негативных последствий для ПК. Если вкратце, то суть разгона в том, чтобы постепенно увеличивать частоту шины процессора через вышеупомянутый множитель.
Важно! Разгон CPU – опасная процедура, которая может негативно сказаться на компьютере, а то и вовсе вывести его из строя. Это связано с тем, что при повышении частоты процессор начинает сильнее нагреваться. Соответственно, если у вас слабая система охлаждения, то CPU может попросту сгореть.
Принцип работы процессорных ядер и многопоточности
В современных операционных системах одновременно работает множество процессов.
Нагрузка от операционной системы на процессор идет по так называемому конвейеру, на который «выкладываются» нужные задачи для ядра. В качестве примера возьмем одно ядро процессора на частоте 4 ГГц с одним ALU (арифметико-логическое устройство) и одним FPU (математический сопроцеесор). Частота в 4 ГГц означает, что ядро исполняет 4 миллиарда тактов в секунду. К ядру по конвейеру поступают задачи, требующие исполнительной мощности, на которые тратится процессорное время.

Часто происходят случаи, когда для выполнения необходимой операции процессору приходится ждать данные из кеша более низкой скорости (L3 кеш), или же оперативной памяти. Данная ситуация называется кэш-промах. Это происходит, когда в кэше ядра не была найдена запрошенная информация и приходится обращаться к более медленной памяти. Также существуют и другие причины, заставляющие прерывать выполнение операции ядром, что негативно сказывается на производительности.
Данный конвейер можно представить, как настоящую сборочную линию на заводе — рабочий (ядро) выполняет работу, поступающую к нему на ленту. И если необходимо взять нужный инструмент, работник отходит, оставляя конвейер простаивать без работы. То есть, исполняемая задача прерывается. Инструментом, за которым пошел рабочий, в данном случае является информация из оперативной памяти или же L3 кэша. Поскольку L1 и L2 кэш намного быстрее, чем любая другая память в компьютере, работа с вычислениями теряет в скорости.
На конвейере с одним потоком не могут выполняться одновременно несколько процессов. Ядро постоянно прерывает выполнение одной операции для другой, более приоритетной. Если появятся две одинаково приоритетные задачи, одна из них обязательно будет остановлена, ведь ядро не сможет работать над ними одновременно. И чем больше поступает задач одновременно, тем больше прерываний происходит.
Подробный разбор

ТЧ измеряет количество задач, которые может обработать процессор за одну секунду. Величину измеряют в Герцах (в честь фамилии учёного). Гц обозначают количество повторений операций в секунду. Также, ею можно измерить и другие показатели. Если вы совершаете 2 вдоха за одну секунду, значит ваша частота дыхания равна двум Герцам.
Существует два вида тактовой частоты:
- внешняя (скорость обмена данными от процессора к оперативной памяти);
- внутренняя (влияет на качество и быстроту вычислений внутри самого процессора).
В процессоре выполняются различные операции, которые вычисляют те или иные параметры. Эти вычисления и есть ТЧ.
Сама единица Гц (Герц), встречается редко. В основном для обозначения берутся мегаГерцы, килоГерцы и т.д.

Например, если вы услышали, что в процессоре 4ГГц, то это значит, что он может обрабатывать до четырех миллиардов вычислений в секунду. Сегодня, такие показатели являются средними. Скоро частота в тераГерц, станет стандартом для процессоров.
Сколько операций в секунду выполняет c

Для оценки производительности и сравнения таких вычислительных машин ввели термин «FLOPS»
FLOPS — внесистемная единица, которая используется для измерения производительности компьютеров. Она показывает, сколько операций с плавающей запятой в секунду выполняет данная вычислительная система.
Самые мощные суперкомпьютеры

Суперкомпьютер Cray 1
Вычислительная машина Cray 1, которая одной из первых заслужила титул «суперкомпьютера», была создана в 1974 году. Её производительность оценивалась в 180 миллионов операций в секунду.

Суперкомпьютеры NEC SX-2 (слева) и М-13 (справа)
Порог в 1 миллиард флопс (1 Гигафлопс) был преодолен уже в 1983 году. На тот момент рекордсменами считались суперкомпьютеры NEC SX-2 (производительность 1.3 Гфлопс) и М-13 академика Карцева (2.4 Гфлопс).

Суперкомпьютер ASCI Red
В середине 90-х вычислительная мощность суперкомпьютеров вычислялась уже триллионами флопс. Граница 1 Тфлопс была впервые преодолена в 1996-ом компьютером ASCI Red.

Суперкомпьютер IBM Roadrunner
1 квадриллион флопс (1 Петафлопс) покорился суперкомпьютеру IBM Roadrunner в 2008 году, аналитики полагают, что к 2020 году появятся экзафлопсные компьютеры, способных выполнять 1 квинтиллион операций с плавающей точкой в секунду.

Суперкомпьютер Sunway TaihuLight
C 1993 ведется международный рейтинг Top500 для оценки и сравнения производительности суперкомпьютеров. Сейчас топ возглавляет китайская разработка Sunway TaihuLight с вычислительной мощностью 93 петафлопс, запущенная в июне 2016 года.
Современные компьютеры и игровые консоли

Большая вычислительная мощность с 90-х годов становится доступна в домашних и офисных компьютерах.
Популярный процессор 1999-2000 годов Intel Pentium III 500—1000 МГц имел производительность до 1-2 гигафлопс.
В 2010 топовые модели были на уровне AMD Athlon II X4 640 3,0 ГГц с мощностью до 37,4 гигафлопс.
Относительно современный Intel Core i7 (Haswell) с частотой 3,0-3,5 ГГц бьет планку в 350 гигафлопс.
Современные игровые консоли имеют такую производительность:
Microsoft Xbox One — 1,23 терафлопса,
Sony PlayStation 4 — 1,84 терафлопса,
Nintendo Wii U — 352 гигафлопса.
Мобильные гаджеты в нашем кармане

Процессоры в последних моделях iPhone и iPad имеют мощность, которая измеряется в десятках и сотнях Гигафлопс. Новинка 2011-го года – Apple A5, который был «сердцем» iPhone 4S, iPad 2, iPad Mini, Apple TV 3 и iPod Touch пятого поколения, выдавал до 16 Гигафлопс.
Представленный в 2014 году Apple A8 (iPhone 6/ 6 Plus, iPad mini 4 и Apple TV 4) может похвастаться показателем уже в 115 Гигафлопс.
Начинка нового iPhone 7 и iPhone 7 Plus (процессор A10 Fusion) выжимает более 400 Гигафлопс.

Если сравнить эти показатели с суперкомпьютерами 80-90х, то видим, что iPhone 4S сопоставим с самыми мощными вычислительными устройствами конца 80-х годов, а топовая техника начала 90-х по производительности не далеко ушла от современного iPhone 7.
К чему все это
Увлеченные презентациями новых iPhone и iPad, в постоянных сравнениях Apple и Samsung, в череде анонсов Xiaomi и Meizu мы просто перестали обращать внимание на простые вещи. Всего за 10-20 лет технологии шагнули вперед настолько, что гаджеты, помещающиеся в кармане джинсов, можно сравнивать с компьютерами, которые не поместились бы в нашей квартире.