Создание python-пакетов (aka setup scripts)
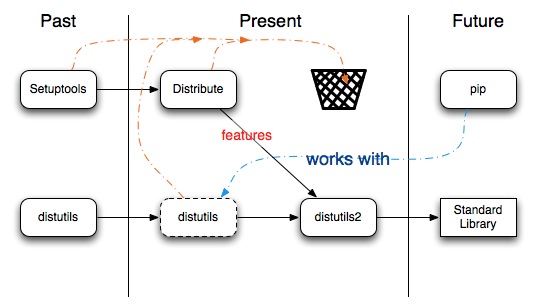
Одна из действительно полезных вещей в python — это система скриптов установки. Любой, серьезно увлекающийся python-программированием разработчик рано или поздно сталкивается с ней. Но из-за гибкости инструментария скриптов установки, их документация весьма раздута. На текущий момент имеется набор утилит (setuptools, distutils, distribute) выполняющих одинаковые задачи.
В данной статье я на конкретных примерах покажу как создать и настроить простой python-пакет.
Наш проект будет иметь следующую функциональность:
- Метод возвращающий строку: "Hello World!";
- Команда helloworld печатающая эту строку в стандартный вывод.
Создаем структуру проекта
Для начала создадим директорию для пакета. Ее минимальный набор файлов состоит из: файла дистрибьюции ( setup.py ) описывающего метаданные и python кода проекта (в нашем случае модуля helloworld).
Также, xорошим тоном считается создание в корне директории файла с описанием проекта: README.txt .
Получаем следующую структуру:
Наша корневая директория helloworld-project будет содержать мета-данные пакета и вспомогательные файлы (тесты, лицензию, документацию и т.д.), а поддиректория helloworld непосредственно сам модуль helloworld .
Теперь отредактируем файл: helloworld/core.py и добавим логику нашего приложения (получение и вывод строки "Hello World!"):
Редактируем мета-информацию (setup.py)
Заполним файл описания README.rst :
Теперь отредактируем файл setup.py :
Убедитесь, что в вашей системе доступны setuptools, в противном случае установите python-пакет distribute
Этих операций достаточно, чтобы собрать пакет дистрибьюции. Выполните команду сборки:
В случае успеха вы получите файл: dist/helloworld-1.0.tar.gz . Это полноценный, архивированный python-пакет и вы можете распространять его среди прочих разработчиков.
Виртуальное окружение
Virtualenv — пакет применяемый для создания изолированного python-окружения. Используем его для тестирования нашего проекта.
Создадим окружение env:
Команда создаст директорию env внутри нашего проекта и установит туда python, pip и distribute. Произведем в него установку нашего проекта.
И протестируем его работоспособность:
Все работает. Осталось добавить поддержку команды helloworld в консоли.
Создание команд
Для создания команды helloworld изменим файл setup.py :
В параметре entry_points мы задаем словарь с "точками вызова" нашего приложения. Ключ console_scripts задает список создаваемых исполняемых скриптов (в Windows это будут exe-файлы). В данном случае мы указали создание исполняемого скрипта helloworld при вызове которого будет запускаться метод print_message из модуля helloworld.core.
Переустановим модуль в наше окружение и проверим работу созданного скрипта (для этого прийдется активировать наше окружение):
Похоже все работает.
Работа с версиями
Номер версии важная часть любого проекта. От него зависит обновление пакетов и разрешение зависимостей. В примере выше мы указали номер версии 1.0 в файле setup.py . Более правильное решение перенести его в файл helloworld/__init__.py чтобы сделать доступным в python-коде. По существующим соглашения для хранения номера версии в модуле, используется переменная __version__.
Изменим файл setup.py , чтобы нам не приходилось редактировать номер версии в двух местах:
Существует множество систем наименования версий в python обычно рекомендуется использовать PEP386. Можно представить, что обозначение версии состоит из номера мажорного, минорного релизов (номера багфикса при необходимости), разделенных точками. В последней части версии разрешается использовать буквы латинского алфавита. Примеры из официальной документации:
Управление зависимостями
Добавим функциональности нашему проекту. Создадим команду serve которая будет запускать вебсервер отдающий страницу со строкой "Hello world!" генерируемой нашим модулем. Для этого воспользуемся пакетом Flask.
Добавляем файл helloworld/web.py :
И файл helloworld/templates/index.html :
И опишем команду serve в файле setup.py :
Теперь в нашем проекте появилась зависимость от пакета Flask. Без его установки наше приложение не будет правильно работать. За описание зависимостей в файле setup.py отвечает параметр install_requires:
Проверим установку зависимостей обновив наш пакет и работу команды serve:
Открыв браузер по адресу http://127.0.0.1:5000 вы должны увидеть нашу страницу.
Управление файлами проекта (MANIFEST.in)
На текущий момент при сборке нашего пакета distutils включает в него только python-файлы. Необходимо включить в него файл helloworld/templates/index.html без которого проект работать не будет.
Чтобы сделать это мы должны сообщить distutils какие еще файлы надо включать в наш проект. Один из способов — это создание файла MANIFEST.in :
Данная команда указывает distutils на включение в проект всех html файлов в директории helloworld/templates .
Также придется обновить setup.py :
Теперь шаблоны будут включены в наш проект.
Создание и запуск тестов
Хорошей практикой считается создание тестов для вашего проекта. Добавим простейшую реализацию, файл tests.py :
И обновим setup.py :
Теперь мы можем произвести предварительное тестирование нашего проекта:
Обратите внимание, что для запуска тестов даже не нужно создание виртуального окружения. Необходимые зависимости будут скачаны в директорию проекта в виде egg пакетов.
Публикация пакета на pypi.python.org
Прежде чем вы сможете опубликовать свой проект вам необходимо зарегистрироваться на PyPi. Запишите ваши реквизиты в файле
Все ваш проект готов к публикации. Достаточно ввести соответствующую команду:
Вы не сможете опубликовать пакет helloworld , тк данное имя проекта уже занято.
2. Writing the Setup Script¶
This document is being retained solely until the setuptools documentation at https://setuptools.readthedocs.io/en/latest/setuptools.html independently covers all of the relevant information currently included here.
The setup script is the centre of all activity in building, distributing, and installing modules using the Distutils. The main purpose of the setup script is to describe your module distribution to the Distutils, so that the various commands that operate on your modules do the right thing. As we saw in section A Simple Example above, the setup script consists mainly of a call to setup() , and most information supplied to the Distutils by the module developer is supplied as keyword arguments to setup() .
Here’s a slightly more involved example, which we’ll follow for the next couple of sections: the Distutils’ own setup script. (Keep in mind that although the Distutils are included with Python 1.6 and later, they also have an independent existence so that Python 1.5.2 users can use them to install other module distributions. The Distutils’ own setup script, shown here, is used to install the package into Python 1.5.2.)
There are only two differences between this and the trivial one-file distribution presented in section A Simple Example : more metadata, and the specification of pure Python modules by package, rather than by module. This is important since the Distutils consist of a couple of dozen modules split into (so far) two packages; an explicit list of every module would be tedious to generate and difficult to maintain. For more information on the additional meta-data, see section Additional meta-data .
Note that any pathnames (files or directories) supplied in the setup script should be written using the Unix convention, i.e. slash-separated. The Distutils will take care of converting this platform-neutral representation into whatever is appropriate on your current platform before actually using the pathname. This makes your setup script portable across operating systems, which of course is one of the major goals of the Distutils. In this spirit, all pathnames in this document are slash-separated.
This, of course, only applies to pathnames given to Distutils functions. If you, for example, use standard Python functions such as glob.glob() or os.listdir() to specify files, you should be careful to write portable code instead of hardcoding path separators:
2.1. Listing whole packages¶
The packages option tells the Distutils to process (build, distribute, install, etc.) all pure Python modules found in each package mentioned in the packages list. In order to do this, of course, there has to be a correspondence between package names and directories in the filesystem. The default correspondence is the most obvious one, i.e. package distutils is found in the directory distutils relative to the distribution root. Thus, when you say packages = [‘foo’] in your setup script, you are promising that the Distutils will find a file foo/__init__.py (which might be spelled differently on your system, but you get the idea) relative to the directory where your setup script lives. If you break this promise, the Distutils will issue a warning but still process the broken package anyway.
If you use a different convention to lay out your source directory, that’s no problem: you just have to supply the package_dir option to tell the Distutils about your convention. For example, say you keep all Python source under lib , so that modules in the “root package” (i.e., not in any package at all) are in lib , modules in the foo package are in lib/foo , and so forth. Then you would put
in your setup script. The keys to this dictionary are package names, and an empty package name stands for the root package. The values are directory names relative to your distribution root. In this case, when you say packages = [‘foo’] , you are promising that the file lib/foo/__init__.py exists.
Another possible convention is to put the foo package right in lib , the foo.bar package in lib/bar , etc. This would be written in the setup script as
A package: dir entry in the package_dir dictionary implicitly applies to all packages below package, so the foo.bar case is automatically handled here. In this example, having packages = [‘foo’, ‘foo.bar’] tells the Distutils to look for lib/__init__.py and lib/bar/__init__.py . (Keep in mind that although package_dir applies recursively, you must explicitly list all packages in packages : the Distutils will not recursively scan your source tree looking for any directory with an __init__.py file.)
2.2. Listing individual modules¶
For a small module distribution, you might prefer to list all modules rather than listing packages—especially the case of a single module that goes in the “root package” (i.e., no package at all). This simplest case was shown in section A Simple Example ; here is a slightly more involved example:
This describes two modules, one of them in the “root” package, the other in the pkg package. Again, the default package/directory layout implies that these two modules can be found in mod1.py and pkg/mod2.py , and that pkg/__init__.py exists as well. And again, you can override the package/directory correspondence using the package_dir option.
2.3. Describing extension modules¶
Just as writing Python extension modules is a bit more complicated than writing pure Python modules, describing them to the Distutils is a bit more complicated. Unlike pure modules, it’s not enough just to list modules or packages and expect the Distutils to go out and find the right files; you have to specify the extension name, source file(s), and any compile/link requirements (include directories, libraries to link with, etc.).
All of this is done through another keyword argument to setup() , the ext_modules option. ext_modules is just a list of Extension instances, each of which describes a single extension module. Suppose your distribution includes a single extension, called foo and implemented by foo.c . If no additional instructions to the compiler/linker are needed, describing this extension is quite simple:
The Extension class can be imported from distutils.core along with setup() . Thus, the setup script for a module distribution that contains only this one extension and nothing else might be:
The Extension class (actually, the underlying extension-building machinery implemented by the build_ext command) supports a great deal of flexibility in describing Python extensions, which is explained in the following sections.
2.3.1. Extension names and packages¶
The first argument to the Extension constructor is always the name of the extension, including any package names. For example,
describes an extension that lives in the root package, while
describes the same extension in the pkg package. The source files and resulting object code are identical in both cases; the only difference is where in the filesystem (and therefore where in Python’s namespace hierarchy) the resulting extension lives.
If you have a number of extensions all in the same package (or all under the same base package), use the ext_package keyword argument to setup() . For example,
will compile foo.c to the extension pkg.foo , and bar.c to pkg.subpkg.bar .
2.3.2. Extension source files¶
The second argument to the Extension constructor is a list of source files. Since the Distutils currently only support C, C++, and Objective-C extensions, these are normally C/C++/Objective-C source files. (Be sure to use appropriate extensions to distinguish C++ source files: .cc and .cpp seem to be recognized by both Unix and Windows compilers.)
However, you can also include SWIG interface ( .i ) files in the list; the build_ext command knows how to deal with SWIG extensions: it will run SWIG on the interface file and compile the resulting C/C++ file into your extension.
This warning notwithstanding, options to SWIG can be currently passed like this:
Or on the commandline like this:
On some platforms, you can include non-source files that are processed by the compiler and included in your extension. Currently, this just means Windows message text ( .mc ) files and resource definition ( .rc ) files for Visual C++. These will be compiled to binary resource ( .res ) files and linked into the executable.
2.3.3. Preprocessor options¶
Three optional arguments to Extension will help if you need to specify include directories to search or preprocessor macros to define/undefine: include_dirs , define_macros , and undef_macros .
For example, if your extension requires header files in the include directory under your distribution root, use the include_dirs option:
You can specify absolute directories there; if you know that your extension will only be built on Unix systems with X11R6 installed to /usr , you can get away with
You should avoid this sort of non-portable usage if you plan to distribute your code: it’s probably better to write C code like
If you need to include header files from some other Python extension, you can take advantage of the fact that header files are installed in a consistent way by the Distutils install_headers command. For example, the Numerical Python header files are installed (on a standard Unix installation) to /usr/local/include/python1.5/Numerical . (The exact location will differ according to your platform and Python installation.) Since the Python include directory— /usr/local/include/python1.5 in this case—is always included in the search path when building Python extensions, the best approach is to write C code like
If you must put the Numerical include directory right into your header search path, though, you can find that directory using the Distutils distutils.sysconfig module:
Even though this is quite portable—it will work on any Python installation, regardless of platform—it’s probably easier to just write your C code in the sensible way.
You can define and undefine pre-processor macros with the define_macros and undef_macros options. define_macros takes a list of (name, value) tuples, where name is the name of the macro to define (a string) and value is its value: either a string or None . (Defining a macro FOO to None is the equivalent of a bare #define FOO in your C source: with most compilers, this sets FOO to the string 1 .) undef_macros is just a list of macros to undefine.
is the equivalent of having this at the top of every C source file:
2.3.4. Library options¶
You can also specify the libraries to link against when building your extension, and the directories to search for those libraries. The libraries option is a list of libraries to link against, library_dirs is a list of directories to search for libraries at link-time, and runtime_library_dirs is a list of directories to search for shared (dynamically loaded) libraries at run-time.
For example, if you need to link against libraries known to be in the standard library search path on target systems
If you need to link with libraries in a non-standard location, you’ll have to include the location in library_dirs :
(Again, this sort of non-portable construct should be avoided if you intend to distribute your code.)
2.3.5. Other options¶
There are still some other options which can be used to handle special cases.
The optional option is a boolean; if it is true, a build failure in the extension will not abort the build process, but instead simply not install the failing extension.
The extra_objects option is a list of object files to be passed to the linker. These files must not have extensions, as the default extension for the compiler is used.
extra_compile_args and extra_link_args can be used to specify additional command line options for the respective compiler and linker command lines.
export_symbols is only useful on Windows. It can contain a list of symbols (functions or variables) to be exported. This option is not needed when building compiled extensions: Distutils will automatically add initmodule to the list of exported symbols.
The depends option is a list of files that the extension depends on (for example header files). The build command will call the compiler on the sources to rebuild extension if any on this files has been modified since the previous build.
2.4. Relationships between Distributions and Packages¶
A distribution may relate to packages in three specific ways:
It can require packages or modules.
It can provide packages or modules.
It can obsolete packages or modules.
These relationships can be specified using keyword arguments to the distutils.core.setup() function.
Dependencies on other Python modules and packages can be specified by supplying the requires keyword argument to setup() . The value must be a list of strings. Each string specifies a package that is required, and optionally what versions are sufficient.
To specify that any version of a module or package is required, the string should consist entirely of the module or package name. Examples include ‘mymodule’ and ‘xml.parsers.expat’ .
If specific versions are required, a sequence of qualifiers can be supplied in parentheses. Each qualifier may consist of a comparison operator and a version number. The accepted comparison operators are:
These can be combined by using multiple qualifiers separated by commas (and optional whitespace). In this case, all of the qualifiers must be matched; a logical AND is used to combine the evaluations.
Let’s look at a bunch of examples:
Only version 1.0 is compatible
Any version after 1.0 and before 2.0 is compatible, except 1.5.1
Now that we can specify dependencies, we also need to be able to specify what we provide that other distributions can require. This is done using the provides keyword argument to setup() . The value for this keyword is a list of strings, each of which names a Python module or package, and optionally identifies the version. If the version is not specified, it is assumed to match that of the distribution.
Provide mypkg , using the distribution version
Provide mypkg version 1.1, regardless of the distribution version
A package can declare that it obsoletes other packages using the obsoletes keyword argument. The value for this is similar to that of the requires keyword: a list of strings giving module or package specifiers. Each specifier consists of a module or package name optionally followed by one or more version qualifiers. Version qualifiers are given in parentheses after the module or package name.
The versions identified by the qualifiers are those that are obsoleted by the distribution being described. If no qualifiers are given, all versions of the named module or package are understood to be obsoleted.
2.5. Installing Scripts¶
So far we have been dealing with pure and non-pure Python modules, which are usually not run by themselves but imported by scripts.
Scripts are files containing Python source code, intended to be started from the command line. Scripts don’t require Distutils to do anything very complicated. The only clever feature is that if the first line of the script starts with #! and contains the word “python”, the Distutils will adjust the first line to refer to the current interpreter location. By default, it is replaced with the current interpreter location. The —executable (or -e ) option will allow the interpreter path to be explicitly overridden.
The scripts option simply is a list of files to be handled in this way. From the PyXML setup script:
Changed in version 3.1: All the scripts will also be added to the MANIFEST file if no template is provided. See Specifying the files to distribute .
2.6. Installing Package Data¶
Often, additional files need to be installed into a package. These files are often data that’s closely related to the package’s implementation, or text files containing documentation that might be of interest to programmers using the package. These files are called package data.
Package data can be added to packages using the package_data keyword argument to the setup() function. The value must be a mapping from package name to a list of relative path names that should be copied into the package. The paths are interpreted as relative to the directory containing the package (information from the package_dir mapping is used if appropriate); that is, the files are expected to be part of the package in the source directories. They may contain glob patterns as well.
The path names may contain directory portions; any necessary directories will be created in the installation.
For example, if a package should contain a subdirectory with several data files, the files can be arranged like this in the source tree:
The corresponding call to setup() might be:
Changed in version 3.1: All the files that match package_data will be added to the MANIFEST file if no template is provided. See Specifying the files to distribute .
2.7. Installing Additional Files¶
The data_files option can be used to specify additional files needed by the module distribution: configuration files, message catalogs, data files, anything which doesn’t fit in the previous categories.
data_files specifies a sequence of (directory, files) pairs in the following way:
Each (directory, files) pair in the sequence specifies the installation directory and the files to install there.
Each file name in files is interpreted relative to the setup.py script at the top of the package source distribution. Note that you can specify the directory where the data files will be installed, but you cannot rename the data files themselves.
The directory should be a relative path. It is interpreted relative to the installation prefix (Python’s sys.prefix for system installations; site.USER_BASE for user installations). Distutils allows directory to be an absolute installation path, but this is discouraged since it is incompatible with the wheel packaging format. No directory information from files is used to determine the final location of the installed file; only the name of the file is used.
You can specify the data_files options as a simple sequence of files without specifying a target directory, but this is not recommended, and the install command will print a warning in this case. To install data files directly in the target directory, an empty string should be given as the directory.
Changed in version 3.1: All the files that match data_files will be added to the MANIFEST file if no template is provided. See Specifying the files to distribute .
2.8. Additional meta-data¶
The setup script may include additional meta-data beyond the name and version. This information includes:
Учимся создавать пакеты Python
 Почему важно уметь создавать пакеты Python?
Почему важно уметь создавать пакеты Python?
• Пакеты легко устанавливаются (pip install demo).
• Пакеты упрощают разработку (Команда pip install -e устанавливает ваш пакет и следит за тем, чтобы он сам обновлялся в ходе всего процесса разработки).
• Пакеты легко запускать и тестировать (from demo.main import say_hello, а затем тестируем функцию).
• Пакеты легко версионировать, при этом вы не рискуете нарушить работу кода, зависящего от этого пакета (pip install demo==1.0.3).
В чем отличия между библиотекой, пакетом и модулем:
• Модуль: это .py-файл, в котором содержатся функции, образующие некоторое единство
• Пакет: это коллекция модулей, которую можно распространять
• Библиотека: это пакет, не учитывающий контекста 
Заключать код Python в пакеты достаточно просто. Для этого вам понадобится всего один скрипт setup.py, позволяющий упаковать код сразу в нескольких форматах для распространения.
1. Подготовка к упаковке
Давайте воспользуемся такой структурой каталогов, которая описана в этом посте, и создадим здесь виртуальное окружение:
Создаем файл setup.py в корневом каталоге. В этом файле мы будем описывать, каким именно образом хотим упаковать наш код. Для начала напишем следующее:
Теперь можно вызвать этот скрипт, который позволяет упаковать ваш код несколькими способами:
Давайте запустим первый вариант из списка. Если все пройдет успешно, то вы сможете импортировать ваш код следующим образом:
Теперь, когда мы в состоянии установить проект, давайте внимательнее рассмотрим аргументы, передаваемые функции setuptools.setup:
1. name: имя вашей функции
2. version: результатом каждого изменения, вносимого в код, должна быть новая версия пакета; в противном случае возможна ситуация, в которой разработчики устанавливают прежнюю версию пакета, которая вдруг станет функционировать не так как раньше и сломает код.
3. packages: список путей ко всем вашим файлам python
4. install_requires: список имен и версий пакетов (точно как в файле requirements.txt)
Как видите, я написал простую функцию read_pipenv_dependencies для считывания из Pipfile.lock зависимостей, не попадающих в разработку (non-dev). В данном случае я не хочу задавать зависимости вручную. Также я воспользуюсь os.getenv для считывания переменной окружения и определения версии пакета – пожалуй, это хорошие сюжеты для новых постов.
2. Документация
Точно как при считывании Pipfile.lock для указания зависимостей, я могу прочитать и файл README.md, чтобы отобразить полезную документацию как long_description. Подробнее о том, как это делается, рассказано в packaging.python.org.
Кроме того, можно создать полноценную веб-страницу с документацией при помощи readthedocs и sphinx. Создаем каталог для вашей документации:
Командой quickstart генерируем каталог с исходниками для вашей документации:
Теперь можно приступать к наполнению файла docs/index.rst самой документацией. Подробнее о том, как автоматизировать этот процесс, рассказано на сайте sphinx-doc.org.
3. Линтинг и тестирование
В рамках процесса упаковки целесообразно применить статический анализ кода, линтинг и тестирование.
В данном случае предпочтительно выполнить команду, которая выполнила бы стиль кода, прогнала несколько тестов и проверок, прежде, чем код можно будет зафиксировать и скинуть в удаленный репозиторий. Это делается для того, чтобы спровоцировать отказ конвейера сборки, если тесты не пройдут.
4. Makefile
По мере того, как мы быстро вводим все новые команды, нужные для упаковки нашего конкретного проекта, распространенные команды полезно записывать. В большинстве инструментов для автоматизации сборки (например, в Gradle или npm) эта возможность предоставляется по умолчанию.
Make – это инструмент, организующий компиляцию кода. Традиционно используется в c-ориентированных проектах. Но с его помощью можно выполнять и любые другие команды.
По умолчанию при использовании make выполняется первая команда из списка. Таким образом, в следующем примере будет выполнена make help, а на экран будет выведено содержимое Makefile.
Если сделать make test, то сначала будет выполнена make dev, поскольку в файле Makefile она указана как зависимость:
Теперь, как видите, новым разработчикам достаточно легко внести свой вклад в проект. Распространенные команды у них как на ладони и, например, сразу видно, как собрать колесо: make build.
5. Установка колеса
Если запустить make build, программа использует файл setup.py, чтобы создать дистрибутив колеса. Файл .whl находится в каталоге dist/, в имени файла должно присутствовать 0.0.dev0. Теперь можно указать переменную окружения, чтобы изменить версию колеса:
Имея колесо, можно создать где-нибудь на ПК новый каталог, скопировать в него колесо, а затем установить его при помощи:
Вывод списка установленных файлов:
6. Включить конфигурационные файлы
Добавить данные в пакет можно и другим способом, включив в скрипт setup.py следующие строки:
После этого можно будет прочитать файл при помощи следующей функции:
Если снова создать колесо и установить его в виртуальной среде в новом каталоге, не копируя файл данных, то можно будет обратиться к данным, выполнив вышеприведенную функцию.
7. DevOps
В рамках процесса упаковки мы хотим интегрировать изменения, внесенные многими участниками и автоматизировать интеграцию, так как для успешного релиза новой версии требуется выполнять множество повторяющихся процессов.
Здесь рассмотрим для примера Azure DevOps, где на git tags, а также в ветке master будет инициироваться процесс, представленный ниже.
Посмотрите код, и ниже мы обсудим его различные стадии и задачи:
На этапе Test мы устанавливаем проект в контейнер конвейера, не создавая виртуального окружения. Затем выполняем команды make lint и make test, точно как вы сделали бы это на вашей машине.
На этапе Build попытаемся извлечь версию пакета, ориентируясь на тег git, а еще соберем резервную версию пакета. Выполним команду python setup.py bdist_wheel для сборки колеса, учитывая, что у нас уже установлена переменная окружения, соответствующая версии пакета. Наконец, мы публикуем артефакт в числе других артефактов Azure DevOps и (по желанию) можем выложить в ленту.
Чтобы опубликовать пакет в ленте, вам потребуется файл .pypirc, а затем вы можете скопировать содержимое ленты, созданной в Azure DevOps. Выглядеть файл будет примерно так:
О том, как устанавливать пакеты из частной ленты, рассказано здесь.
How to create a setup file for your project
When you develop software, at some point you will want other people to be able to use what you have built. Sometimes it is handy if you can quickly use the code you developed yourself in the past on a new machine or a different virtual environment. We have already seen that for importing to work properly, it is very important to have well-defined packages, and that Python knows where to find them.
With a proper setup file, Python will quickly understand where to find the package, and thus importing from other places becomes trivial. It will also be possible to quickly distribute the code with other people, diminishing the barrier of adoption. Having a setup.py file is the first step into being able to switch from scripts to a package on which to rely.
Your first setup file
The examples we are going to develop are toy examples, very similar to the ones on the article about importing. But they will prove the point. You should start on an empty directory, the name doesn’t matter, but it is important not to mix it with other things, so you can follow this article without complications.
Let’s start by creating a file called first.py, with the following code inside:
This file is what we want to be able to use from other packages, etc. What we would like to be able to achieve is to run code like this:
Next to the file, let’s create a new file called setup.py, with the following code:
. warning The code we are developing is harmless, nevertheless, it is always wise to create a virtual environment to play around, and eventually discard once you understood and polished the details
To install your script, you can simply do the following from the console:
You will see some information printed to the screen. More importantly, you can now use your package from anywhere else on your computer. For example, change your directory to anywhere else on your computer, and to the following:
This is great, now you have a way of using your program from anywhere else, even from other packages.
Laying out the project
In the example above we had only one script available, and thus the structure of the program was straightforward. However, this is rarely the case. As soon as your program starts having multiple files, you will need to structure it in such a way that setup knows what files are needed. Let’s evolve the example above. Let’s create now a package with tho modules, the folder structure will look like this:
Let’s develop two very simple function inside file_a and file_b, respectively:
We need to update the setup.py file to accommodate that the program is more complex than what it was before. Fortunately, the developers at setuptools made our life very easy, we just need to write the following:
We have removed the script argument, but have added the packages argument. find_packages will automatically look for packages in a given directory. If we don’t provide any arguments, it will look in the current folder. If you want to see it in action, you can do the following within a python interpreter:
So now you see, find packages returns a list with the names of the packages we will include in the setup. If you want to have finer control, you can replace find_packages and type down exactly what you want to include in your install. Also, if your code would be inside of an extra folder, for example src , you would need to specify it: find_packages(where=’src’) . I, personally, prefer to keep the code directly in a folder next to the setup file, with a name that makes it very clear that it is the entire package inside, just like in the example in this section. Again, if you just install the code,
you will be able to use it:
With everything you know from importing files in Python, it is now dead easy to use relative, absolute imports, etc. because everything is added to the path by the installation procedure.
Installing in development mode
One of the important things to point out is that the setup process can be very helpful also while developing, not only when you are releasing the code. This can be achieved by installing the code in development mode. The only thing you need to do is to run the setup script with a different argument:
Now, if you change any of your files, it will be reflected, in your code. For example, let’s edit file_b.py*:
If you use the module again, you will see the output was modified:
. note Remember that if you change a module in Python, you will need to restart the interpreter. Once you import a module, Python will skip any new import statements of the same packages.
One of the best things about this approach is that if you add a new module to your package, it will still work fine. For example, let’s create a new module C, which uses what is already available in a and b, using two different import approaches. Create a folder called mod_c, with a file file_c.py, and add the following:
And we can simply use it:
Now you see that by having a setup.py file, using relative and absolute imports became trivial. No more worries about the system path, the python path, etc. everything is taken care of. Having a setup.py even when you are just starting makes your life much easier. You stop worrying about where the code is, how to import it, etc.
But where is the code?
At some point, you may be wondering what is happening to your code that makes it work. I will assume you are working within a virtual environment (because that is what you should be doing anyway), and that you know where is your virtual environment located (i.e. the folder where everything is stored). Navigate to the site-packages folder, in my case, it is located in:
venv is the name of the virtual environment. python3.6 is the version I am using now, but it can be different for you. Before you install anything else, just after a fresh virtual environment is created, the contents of the folder are very limited. You have pip, setuptools, and not much more. Let’s install the package in development mode:
And if you look at the contents of the site-packages folder, you will notice a new file created: My-First-Setup-File.egg-link. Pay attention that the name of the file is associated with the name argument we used in the setup.py file. You can open the file with any text editor, what do you see? Indeed, you see the full path to the directory that contains the *my_package folder. That file can tell the Python interpreter what should be added to its path to work with our module. You see that it is not a lot of work, but being able to do it from a single command pays off.
If you, on the other hand, install the package:
You will see that what gets installed in the site-packages folder is radically different, you will find a file called My_First_Setup_File-1.0-py3.6.egg. Egg files are just zip files that Python can uncompress and use when required. You can easily open the file with the same program you use to open zip files, and you will find a copy of your code. The folders, the files, etc. plus some metadata of your program, such as the author, license, etc. (which we haven’t used yet in your simple setup file). Whenever you change your project files, they won’t become available on your other programs, because now Python has its copy of the source code. Whenever you change a file you will need to run the setup script again:
And the code will be refreshed and you can use the new development. You have to be careful, because it is very easy to forget to run again the setup script, and you will be banging your head against the wall trying to find why your bugs are still there if you solved them in your code. If you are developing a solution and trying things out, you should avoid the setup install and keep the setup.py develop approach.
Installing with pip
Just for completeness, it is important to show that once you have your setup.py file in place, you can also use pip to install it by running:
Note two things: if you used the python setup.py approach, you should first remove the files created on your site-packages folder, or pip will fail with a cryptic message. Also, note the . after the install, this is important to tell pip you want to install this package. The install always takes the name of the package you would like to install. One of the advantages of using pip for installing is that you also get the uninstall for free. However, to uninstall you need to use the name you gave to your package:
Now you see that the name we gave to our package is independent of how we use it. We had to import my_package , while the actual name is My-First-Setup-File . This, in my opinion, can create a lot of headaches. For example, if you want to communicate with a serial device, you install a package called PySerial , while to use it you have to import serial . It may not seem like a big issue at the beginning until you find two packages with different names which define two different modules with the same name serial . Imagine we change the name of my_packe to serial. And we do the following:
bash pip install . pip install pyserial
If you explore the folder serial within your site-packages you will see that both your code and pyserial are mixed up. There is no warning of this clash, and the results can be an absolute disaster, especially if the top-level __init__.py file is used somehow. The example above may seem a bit far-fetched for some. But you would be surprised to know that there are two packages: pyserial and serial which are used for some very different tasks and both specify the same module name.
Installing from Github
One of the advantages of creating setup.py files is that you can directly install packages available on Github (or on any other online repository). For example, if you would like to install the code of this tutorial, which can be found here, you can run:
There are several things to note on the code above. First, it will not work on Windows as it is written. You will need to enclose the repository address with » so it understands it is the path to a repository. Note that we have used git+https because it is the simplest way of making it work. If you have configured your ssh keys properly, you can also use pip install git+git , which can give you access to private repositories as well. We have used github.com , but you can use any other version control platform you like, including Gitlab and bitbucket. The path up to website_example_code.git is simply the location of the repository, but in our case, the setup file is inside of a subdirectory, that is why we appended the #subdirectory=code/38_creating_setup_py information. But if it is not the case, you can skip that extra information.
. note In most repositories, the setup.py is at the top level, and thus you won’t need to specify a subdirectory to use it.
Now you see that it is very easy to share with others, you just need to put the code in a place that can be accessed by others. However, when you start sharing code, there are other things you need to be aware of. Imagine you update your code. In our case, we changed what function_c does. If we upload the code to Github, and then you run the same command as above, buried within a lot of information, there will be a line saying:
This means that the code was not changed, because pip found that the package was already installed. You can run the same code with the extra —upgrade argument, and you will see that indeed it updates the code.
Just to close the discussion with pip installations, there is a very nice feature that allows you to install the package in editable mode, meaning that you can make changes and submit them to version control. This is ideal if you are willing to contribute to a package that is part of the requirements of your current project. In that case, you can run pip like this:
And if you explore your virtual environment, you will find a folder called src in which the package is available. Not only that, but the package itself is a git repository you can use as any other repository. You will also find a file within site-packages linking to the directory where the code is, including its subdirectory.
Adding an entry point
So far everything is working great, and probably you have plenty of ideas in your head about what can be done with a setup file. But what we have seen up to now is only the beginning. In the examples above, we have always installed a package that could be imported from other packages. This is great for a lot of applications, but in a lot of situations, you would like to be able to run your program directly, without the need to import from another script. That is when entry points become your best friends.
Let’s creat a new file, called start.py at the top directory, my_package, and let’s add the following:
This file in itself does not do anything, but the function main will generate an output of we run it. If we go back to setup.py, we can add the following:
Note that we have added a new argument, called entry_points . We want to have a console script, meaning something we can run as a command from the terminal. We call it my_start , and then we specify the path to it in the form module.file:function . The last argument must be a callable, something we can execute. If you install our package again:
We will be able to run my_start directly from the terminal:
If you want to know where the command is located, you can run (Linux and Mac, not Windows):
Windows users need to run:
So, the script is located inside the bin folder of your virtual environment. One of the nicest things of doing this is that if you are on Windows it will also work. You see that it creates an executable .exe file. The function you run as an entry point can be further extended with arguments, etc. but this is for another discussion.
If you are building an application with a user interface, instead of using console_scripts you can use gui_scripts . On Windows, this will allow you to run the program without opening a terminal in the background, and this will look more professional. But is nothing you can’t live without.
Remember that you can add as many entry points as you wish. If your program can perform very different tasks, perhaps you would prefer to have different entry points instead of an endless list of arguments which alter the behavior. It is up to you to choose what you believe is the best approach.
For consistency, there is one extra thing to mention. Right now, with the entry point, we have a script that runs a specific task, but we can’t run our package directly from Python. Thus, let’s create a file at the top-level directory of the package, called main.py, with the following:
It’s the same as our start file, but with the extra two lines at the end. Now, we can run our package directly:
If you look around other packages, you will see that many define a __main__ file and then an entry point using it. We could redefine our entry point, and it will look like:
Adding dependencies
Right now we have a package that is completely independent of anything else around. Therefore, the next step is to add dependencies to the setup.py file. As an example, let’s assume we want to have numpy (regardless of its version) and Django before version 3.0. We can add the following to the setup.py file:
You will see that if we run the setup script, python will automatically fetch the latest numpy version and Django 2.2 (even though 3.0 is available). Working with dependencies can be a nightmare, and pip is not great at solving conflicts. Imagine you have two packages which require different versions of some libraries, the one you install the latest is the one that prevails. And this is even without considering that those libraries have other requirements, etc. There are other package managers which are more powerful than pip and take into account all the dependencies to find the sweet spot that satisfies all the requirements.
Difference with requirements files
A common issue when people start working with setup files is that they wonder what is the role requirement files have if you can specify everything in the setup file. The general answer is that requirement files are normally used to keep track of an environment, and therefore they normally include the specific version of the libraries used. This ensures that you can reproduce almost the same environment that the person developing the code had. Setup files, on the other hand, should be more accommodating. In the end, what we want is to make it simple for users to get our code running. Therefore, normally they include the minimum version of libraries to run, or the maximum version, in case future changes of a library would break things.
The reality is that there are no hard-written rules. You have to put yourself in the shoes of your users and decide what would make their life easier. Is it pin-pointing the versions of every library in the environment, or is it giving flexibility? If it would be a developer looking into your code, one of the options is to always download the code, install everything from requirements.txt and then run setup.py. If things are well configured, the last step won’t download anything, since all the dependencies will be present in our environment. And then you know both people have the same versions installed while developing.
There is also the option of not adding any requirements in your setup and asking users to install everything in the requirements file to use your library. This approach is very user-unfriendly, but it also works. So, you see, there is a lot of flexibility for you to decide what approach you think is best in your particular situation.
Extra Dependencies
Setup files also give us the option to define extra dependencies, which are not always necessary, but which can enhance the functionality of our program in some cases. We simply define them as an extra argument for the setup function:
And to install them, we can run a pip command:
Note that this works also with libraries available on PyPI, for example, scikit-learn can be installed with extra dependencies:
Extra dependencies are a great feature when you have dependencies that are hard to install in some systems, or which take a lot of resources, or which are conflicting, just like serial and pyserial above. Note that nothing prevents you from installing both opt1 and opt2 , thus the conflict can still arise.
Where to next
This was an introduction to develop your first setup.py file. The topic is far from over, but with what you have up to now, you can go a long way. Something very useful is to pay attention to the libraries you use and how they behave. For example, you can check the setup file of scikit-learn, or of Django. They can be much more complex than what you need, but they can also point you in the right direction if you are looking for inspiration on how to structure your code. If you are curious about more down-to-earth examples, you can see the one I’ve developed for the Python for the Lab workshop, or for the startup in which I’m working. Many of the arguments of setup.py which are available (and almost trivial), such as author , website were skipped in this tutorial, since they don’t bring much to the discussion, and you can quickly add them.
An obvious step once you have your setup file in order is to release your code through PyPI. This topic will be covered soon. Something we didn’t discuss, and which I hope grabbed your attention is that when you run python setup.py install some folders are created, such as build and dist . Go ahead and explore them, see what is inside and try to understand what is happening when you install the package as we have just done.
Finally, another very interesting topic is what happens if you want to release your package to be installed through conda instead of pip. Conda is a great package manager, that allows you to install also non-python libraries and manage dependencies much more efficiently than what pip does. However, developing a package which is conda-installable requires some extra steps, which will also be covered later.