Оконные функции SQL
2 Май 2020 , Data engineering, 74243 просмотров, Introduction to Window Functions in SQL
Оконные функции SQL это, пожалуй, самая мистическая часть SQL для многих веб-разработчиков. Нередко встретишь и тех, кто и вовсе никогда о них не слышал. Да что греха таить, я сам продолжительное время не знал об их существовании, решая задачи далеко не самым оптимальным способом.
Оконные функции это функции применяемые к набору строк так или иначе связанных с текущей строкой. Наверняка всем известны классические агрегатные функции вроде AVG , SUM , COUNT , используемые при группировке данных. В результате группировки количество строк уменьшается, оконные функции напротив никак не влияют на количество строк в результате их применения, оно остаётся прежним.
Привычные нам агрегатные функции также могут быть использованы в качестве оконных функций, нужно лишь добавить выражение определения «окна». Область применения оконных функций чаще всего связана с аналитическими запросами, анализом данных.
Из чего состоит оконная функция
Лучше всего понять как работают оконные функции на практике. Представим, что у нас есть таблица с зарплатами сотрудников по департаментам. Вот как она выглядит:
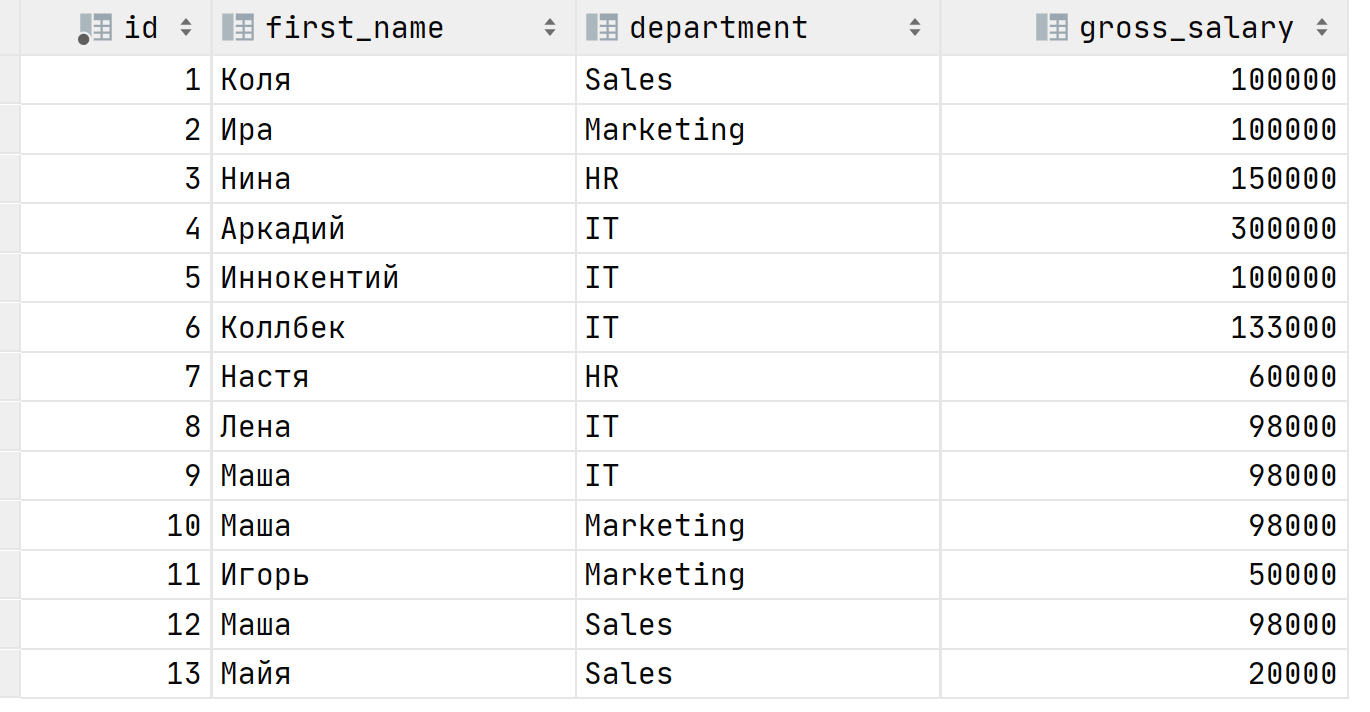
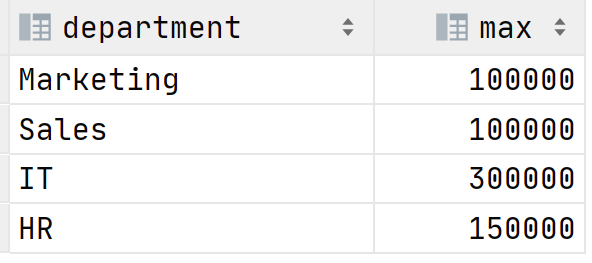
В связи с пандемией коронавируса необходимо оптимизировать расходы путем сокращения сотрудников или понижения их зарплат. Ваш вечнонедовольный директор приходит к вам с просьбой выяснить кто получает больше всего в каждом департаменте. Как поступить? Можно использовать агрегатные функции, в нашем случае MAX , чтобы выяснить максимальную зарплату в каждом отделе:
Результат выполнения запроса:
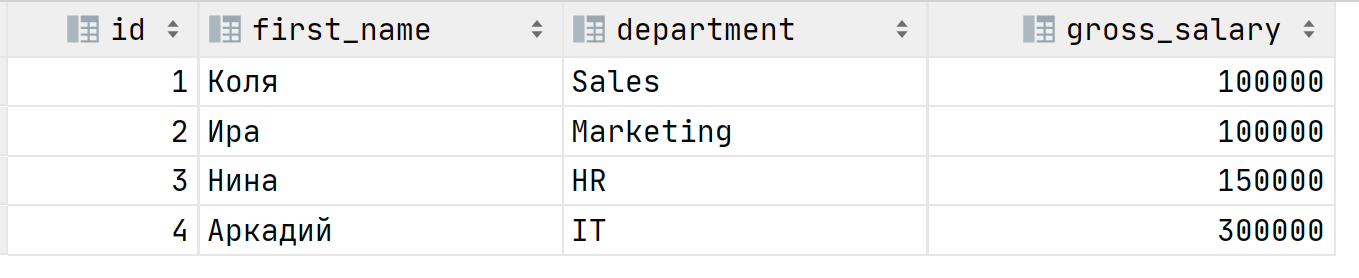
Чтобы узнать кто эти «счастливчики» на сокращение можно выделить запрос в подзапрос и объединить с исходной таблицей путём JOIN:
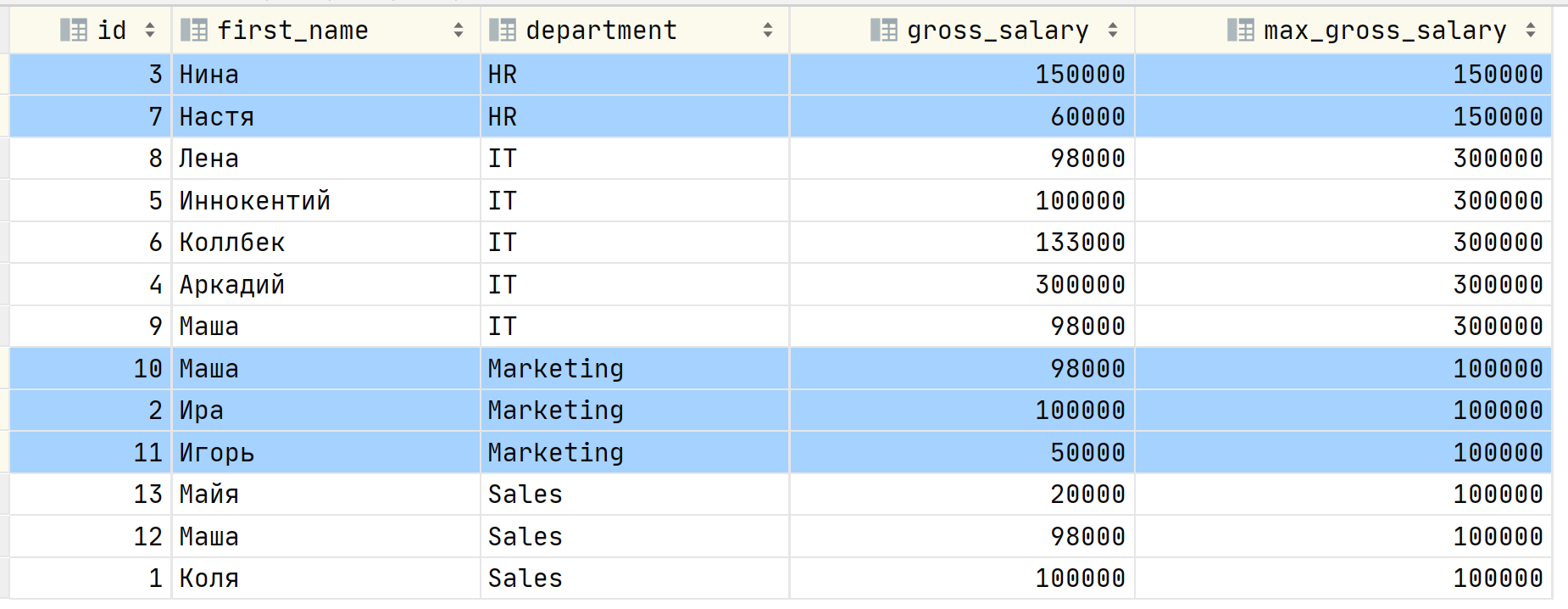
Но тут вы вспоминаете, что эту же задачу можно решить, используя оконные функции, которые вы проходили на одной из лекций по SQL в универе в бородатом году. Как? Используя всё ту же агрегатную функцию MAX , задав «окно». Окном в нашем случае будут сотрудники одного департамента (строки с одинаковым значением в колонке department).
Окно задаётся через выражение OVER (PARTITION BY <колонки>), т.е. строки мы как бы группируем по признаку в указанных колонках, конкретно в этом случае по признаку принадлежности к департаменту в компании. Результат запроса:
Чтобы отфильтровать потенциальных кандидатов на сокращение можно выделить запрос в подзапрос:
Результат будет точно таким же как и при объединении. Итак, с чувством собственного величия, ощущая себя цифровым палачом вы отправляете результат своему начальнику. Он смотрит на вывод и говорит, что у Аркадия из IT отдела зарплата 300 000, но другой сотрудник в этом же отделе может получать 295 000, разница между ними будет несущественна. Покажи мне пропорцию зарплат в отделе относительно суммы всех зарплат в этом отделе, а также относительно всего фонда оплаты труда!
Как решать? Можно пойти тем же путём, используя подзапросы:
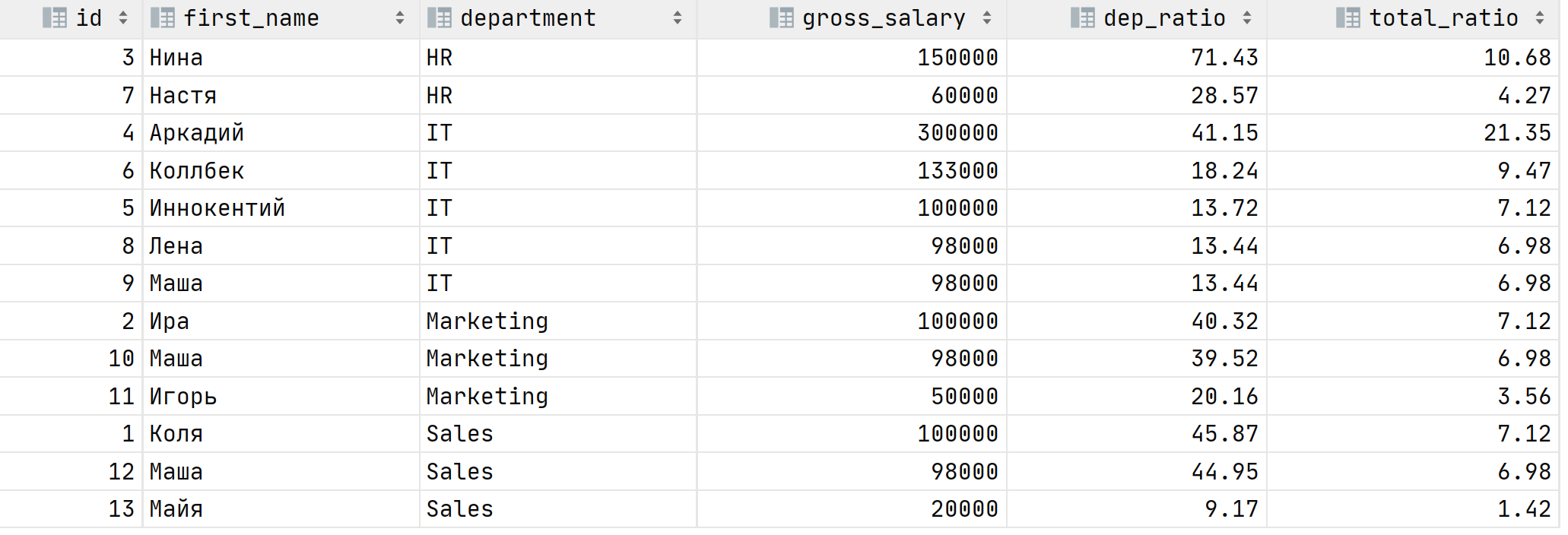
На этой таблице видно, что зарплата Нины это 71% расходов на HR отдел, но лишь 10.5% от всего ФОТ, а вот Аркадий выделился, конечно. Его зарплата это 41% от зарплаты всего IT отдела и 21% от всего ФОТ! Идеальный кандидат на сокращение �� Но не кажется ли вам, что SQL запрос малость сложный? Давайте попробуем его написать через оконные функции:
Кратко, понятно, содержательно! Выражение OVER() означает, что окном для применения функции являются все строки, т.е. SUM(gross_salary) OVER() , означает что сумма будет посчитана по всем зарплатам независимо от департамента в котором работает сотрудник.
Что дальше
В примере выше мы использовали исключительно агрегатные функции как оконные, но в стандарте SQL есть исключительно оконные функции, которые невозможно использовать как агрегатные, это значит, что их невозможно применить при обычной группировке. Вот лишь часть оконных функций, доступных в PostgreSQL:
- first_value
- last_value
- lead
- lag
- rank
- dense_rank
- row_number
Со всеми доступными оконными функциями можно ознакомиться в официальной документации PostgreSQL.
Использование оконных функций
В задаче определения самого высокооплачиваемого сотрудника мы использовали агрегатные функции MAX , SUM , давайте рассмотрим чисто оконную функцию first_value . Она возвращает первое значение согласно заданного окна, т.е. применимо к нашей задаче она должна вернуть имя сотрудника у которого самая высокая зарплата в департаменте.
last_value делает то же самое только наоборот, возвращает самую последнюю строчку. Давайте найдём с помощью неё самого низкооплачиваемого сотрудника в департаменте.
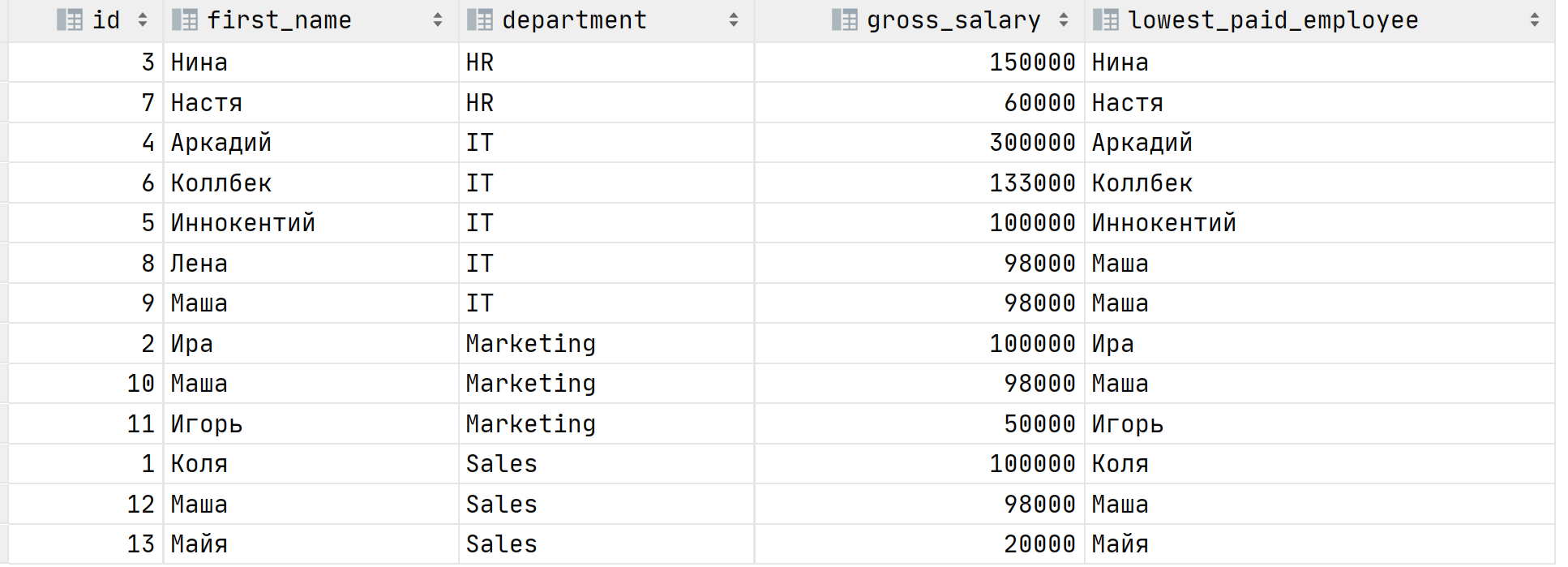
Если внимательно взглянуть на результат выполнения запроса, то можно понять, что он неверный. Почему? А потому что мы не указали диапазон/границы окна относительно текущей строки. По умолчанию, если не задано выражение ORDER BY внутри OVER , то границами окна являются все строки, если ORDER BY задан, то границей для текущей строки будут все предшествующие строки и текущая, в терминах SQL это ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW . В этом можно убедиться, если внимательно взглянуть на результат выполнения крайнего запроса.
Как исправить ситуацию? Расширить границы окна. Перепишем наш запрос, указав в качестве границ все предшествующие строки в окне и все последующие. В терминах SQL это выражение ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING :
Визуально это выглядит примерно как на картинке ниже.
Как посчитать всё на свете одним SQL-запросом. Оконные функции PostgreSQL

Я с удивлением обнаружил, что многие разработчики, даже давно использующие postgresql, не понимают оконные функции, считая их какой-то особой магией для избранных. Ну или в лучшем случае «копипастят» со StackOverflow выражения типа «row_number() OVER ()», не вдаваясь в детали. А ведь оконные функции — полезнейший функционал PostgreSQL.
Попробую по-простому объяснить, как можно их использовать.
Для начала хочу сразу пояснить, что оконные функции не изменяют выборку, а только добавляют некоторую дополнительную информацию о ней. Т.е. для простоты понимания можно считать, что postgres сначала выполняет весь запрос (кроме сортировки и limit), а потом только просчитывает оконные выражения.
Синтаксис примерно такой:
Окно — это некоторое выражение, описывающее набор строк, которые будет обрабатывать функция и порядок этой обработки.
Причем окно может быть просто задано пустыми скобками (), т.е. окном являются все строки результата запроса.
Например, в этом селекте к обычным полям id, header и score просто добавится нумерация строк.
В оконное выражение можно добавить ORDER BY, тогда можно изменить порядок обработки.
Обратите внимание, что я добавил еще и в конце всего запоса ORDER BY id, при этом рейтинг посчитан все равно верно. Т.е. посгрес просто отсортировал результат вместе с результатом работы оконной функции, один order ничуть не мешает другому.
Дальше — больше. В оконное выражение можно добавить слово PARTITION BY [expression],
например row_number() OVER (PARTITION BY section), тогда подсчет будет идти в каждой группе отдельно:
Если не указывать партицию, то партицией является весь запрос.
Тут сразу надо немного сказать о функциях, которые можно использовать, так как есть очень важный нюанс.
В качестве функции можно использовать, так сказать, истинные оконные функции из мануала — это row_number(), rank(), lead() и т.д., а можно использовать функции-агрегаты, такие как: sum(), count() и т.д. Так вот, это важно, агрегатные функции работают слегка по-другому: если не задан ORDER BY в окне, идет подсчет по всей партиции один раз, и результат пишется во все строки (одинаков для всех строк партиции). Если же ORDER BY задан, то подсчет в каждой строке идет от начала партиции до этой строки.
Давайте посмотрим это на примере. Например, у нас есть некая (сферическая в вакууме) таблица пополнений балансов.
и мы хотим узнать заодно, как менялся остаток на балансе при этом:
Т.е. для каждой строки идет подсчет в отдельном фрейме. В данном случае фрейм — это набор строк от начала до текущей строки (если было бы PARTITION BY, то от начала партиции).
Если же мы для агрегатной фунции sum не будем использовать ORDER BY в окне, тогда мы просто посчитаем общую сумму и покажем её во всех строках. Т.е. фреймом для каждой из строк будет весь набор строк
от начала до конца партиции.
Вот такая особенность агрегатных функций, если их использовать как оконные. На мой взгляд, это довольно-таки странный, интуитивно неочевидный момент SQL-стандарта.
Оконные функции можно использовать сразу по несколько штук, они друг другу ничуть не мешают, чтобы вы там в них не написали.
Если у вас много одинаковых выражений после OVER, то можно дать им имя и вынести отдельно с ключевым словом WINDOW, чтобы избежать дублирования кода. Вот пример из мануала:
Здесь w после слова OVER идет без уже скобок.
Результат работы оконной функции невозможно отфильтровать в запросе с помощью WHERE, потому что оконные фунции выполняются после всей фильтрации и группировки, т.е. с тем, что получилось. Поэтому чтобы выбрать, например, топ 5 новостей в каждой группе, надо использовать подзапрос:
Еще пример для закрепления. Помимо row_number() есть несколько других функций. Например lag, которая ищет строку перед последней строкой фрейма. К примеру мы можем найти насколько очков новость отстает от предыдущей в рейтинге:
Прошу в коментариях накидать примеров, где особенно удобно применять оконные фунции. А также, какие с ними могут возникнуть проблемы, если таковые имеются.
Подписывайтесь на подкаст о разработке «Цинковый прод», где мы обсуждаем базы данных, языки программирования и всё на свете!
Оконные функции в SQL — что это и зачем они нужны
Многие разработчики, даже давно знакомые с SQL, не понимают оконные функции, считая их какой-то особой магией для избранных. И, хотя реализация оконных функций поддерживается с SQL Server 2005, кто-то до сих пор «копипастит» их со StackOverflow, не вдаваясь в детали. Этой статьёй мы попытаемся развенчать миф о неприступности этой функциональности SQL и покажем несколько примеров работы оконных функций на реальном датасете.
Почему не GROUP BY и не JOIN
Сразу проясним, что оконные функции — это не то же самое, что GROUP BY. Они не уменьшают количество строк, а возвращают столько же значений, сколько получили на вход. Во-вторых, в отличие от GROUP BY, OVER может обращаться к другим строкам. И в-третьих, они могут считать скользящие средние и кумулятивные суммы.
Примечание Оконные функции не изменяют выборку, а только добавляют некоторую дополнительную информацию о ней. Для простоты понимания можно считать, что SQL сначала выполняет весь запрос (кроме сортировки и limit), а уже потом считает значения окна.
Окей, с GROUP BY разобрались. Но в SQL практически всегда можно пойти несколькими путями. К примеру, может возникнуть желание использовать подзапросы или JOIN. Конечно, JOIN по производительности предпочтительнее подзапросов, а производительность конструкций JOIN и OVER окажется одинаковой. Но OVER даёт больше свободы, чем жёсткий JOIN. Да и объём кода в итоге окажется гораздо меньше.
Для начала
Оконные функции начинаются с оператора OVER и настраиваются с помощью трёх других операторов: PARTITION BY, ORDER BY и ROWS. Про ORDER BY, PARTITION BY и его вспомогательные операторы LAG, LEAD, RANK мы расскажем подробнее.
Все примеры будут основаны на датасете олимпийских медалистов от Datacamp. Таблица называется summer_medals и содержит результаты Олимпиад с 1896 по 2010: 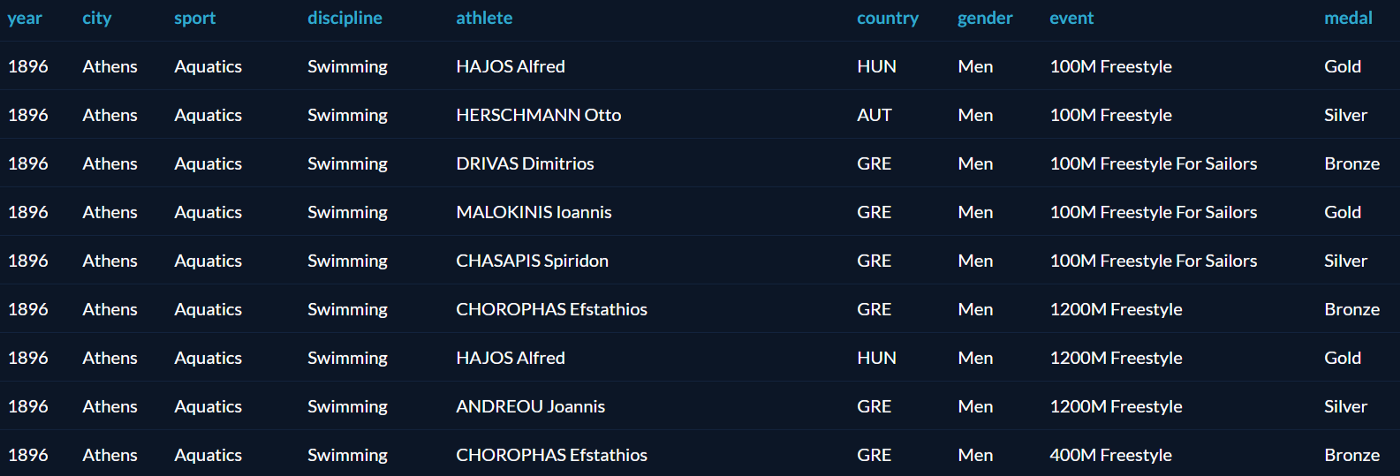
ROW_NUMBER и ORDER BY
Как уже говорилось выше, оператор OVER создаёт оконную функцию. Начнём с простой функции ROW_NUMBER, которая присваивает номер каждой выбранной записи:
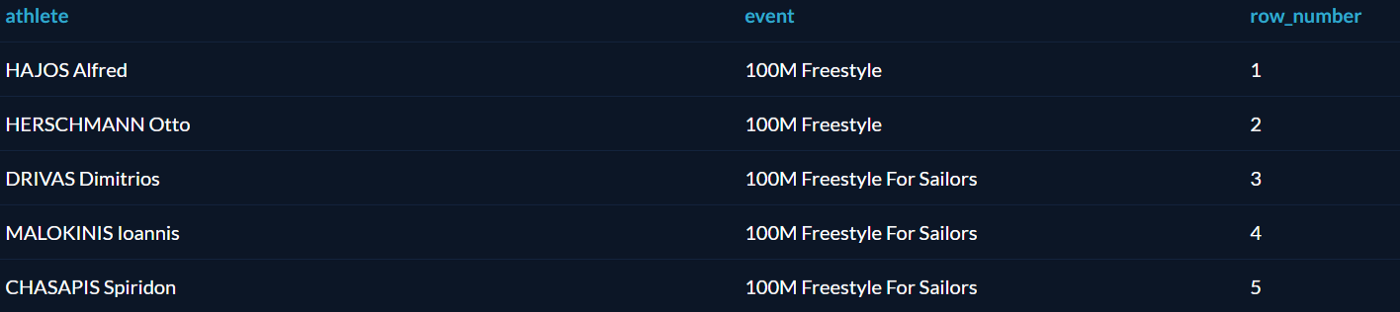
Каждая пара «спортсмен — вид спорта» получила номер, причём к этим номерам можно обращаться по имени row_number.
ROW_NUMBER можно объединить с ORDER BY, чтобы определить, в каком порядке строки будут нумероваться. Выберем с помощью DISTINCT все имеющиеся виды спорта и пронумеруем их в алфавитном порядке:

PARTITION BY и LAG, LEAD и RANK
PARTITION BY позволяет сгруппировать строки по значению определённого столбца. Это полезно, если данные логически делятся на какие-то категории и нужно что-то сделать с данной строкой с учётом других строк той же группы (скажем, сравнить теннисиста с остальными теннисистами, но не с бегунами или пловцами). Этот оператор работает только с оконными функциями типа LAG, LEAD, RANK и т. д.
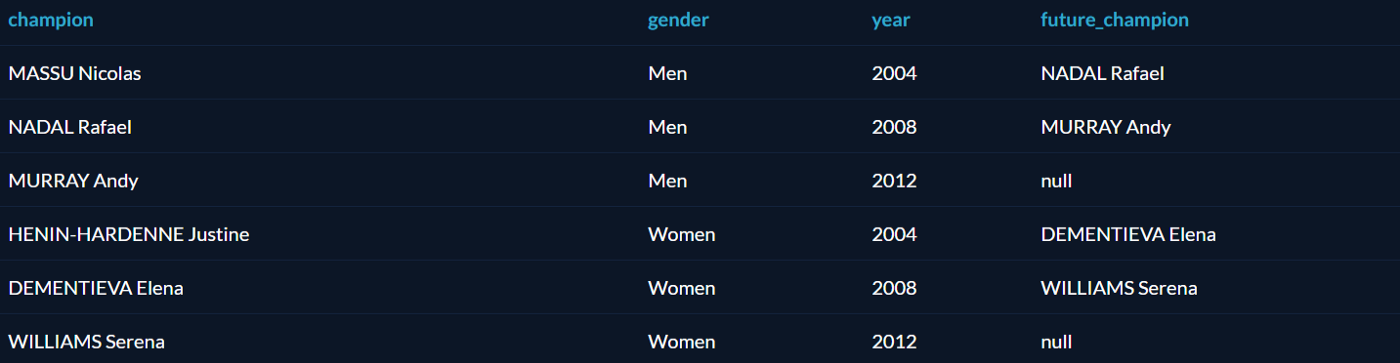
Функция LAG берёт строку и возвращает ту, которая шла перед ней. Например, мы хотим найти всех олимпийских чемпионов по теннису (мужчин и женщин отдельно), начиная с 2004 года, и для каждого из них выяснить, кто был предыдущим чемпионом.
Решение этой задачи требует нескольких шагов. Сначала надо создать табличное выражение, которое сохранит результат запроса «чемпионы по теннису с 2004 года» как временную именованную структуру для дальнейшего анализа. А затем разделить их по полу и выбрать предыдущего чемпиона с помощью LAG:

Функция PARTITION BY в таблице вернула сначала всех мужчин, потом всех женщин. Для победителей 2008 и 2012 года приведён предыдущий чемпион; так как данные есть только за 3 олимпиады, у чемпионов 2004 года нет предшественников, поэтому в соответствующих полях стоит null.
Функция LEAD похожа на LAG, но вместо предыдущей строки возвращает следующую. Можно узнать, кто стал следующим чемпионом после того или иного спортсмена:
Оператор RANK похож на ROW_NUMBER, но присваивает одинаковые номера строкам с одинаковыми значениями, а «лишние» номера пропускает. Есть также DENSE_RANK, который не пропускает номеров. Звучит запутанно, так что проще показать на примере. Вот ранжирование стран по числу олимпиад, в которых они участвовали, разными операторами:
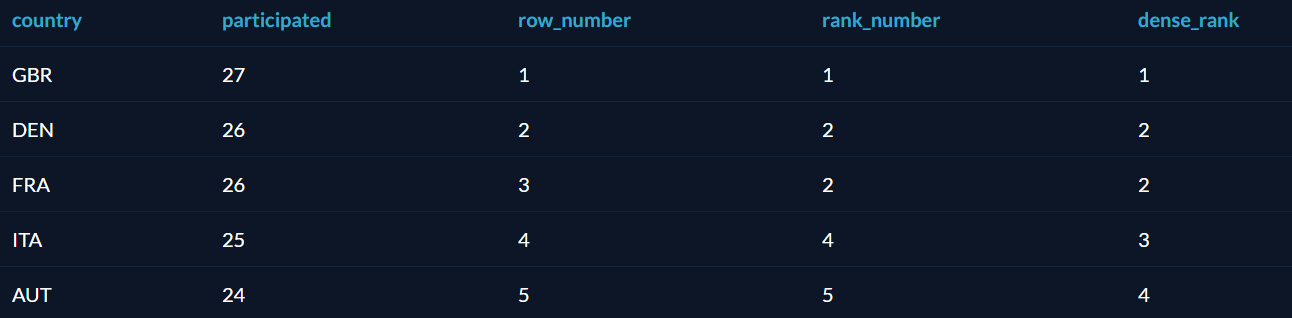
- Row_number — ничего интересного, строки просто пронумерованы по возрастанию.
- Rank_number — строки ранжированы по возрастанию, но нет номера 3. Вместо этого, 2 строки делят номер 2, а за ними сразу идёт номер 4.
- Dense_rank — то же самое, что и rank_number, но номер 3 не пропущен. Номера идут подряд, но зато никто не оказался пятым из пяти.
Напоследок
Вот так мы и разложили этот датасет по полочкам при помощи оконных функций. На этом наше введение в оконные функции заканчивается. Надеемся, это было интересно и не так сложно, как могло показаться.
Конечно, это далеко не все возможности оконных функций. Для них есть много других полезных вещей, например ROWS, NTILE и агрегирующие функции (SUM, MAX, MIN и другие), но об этом поговорим в другой раз.
Полезные оконные функции SQL
Можно бесконечно долго «воротить нос» от использования SQL для Data Preparation, отдавая лавры змеиному языку, но нельзя не признавать факт, что чаще мы используем и еще долго будем использовать SQL для работы с данными, в том числе и очень объемными.
Более того, считаем, что на текущий момент SQL окажется под рукой сотрудника с большей вероятностью, чем Python, и поможет быстро решить аналитическую задачку с приоритетом «-1».
Предложение OVER помогает «открыть окно», т.е. определить строки, с которым будет работать та или иная функция.
Предложение partion BY не является обязательным, но дополняет OVER и показывает, как именно мы разделяем строки, к которым будет применена функция.
ORDER BY определит порядок обработки строк.
В одном select может быть больше одного OVER, эта прекрасная особенность упростит выполнение аналитической задачи в дальнейшем.
Итак, оконные функции делятся на:
- Агрегатные функции
- Ранжирующие функции
- Функции смещения
- Аналитические функции
Собственно, те же, что и обычные, только встроенные в конструкцию с OVER
SUM/ AVG / COUNT/ MIN/ MAX
Для наглядности работы данных функций воспользуемся базовым набором данных (T)
Найти максимальную задолженность в каждом банке.
Для чего тут оконные функции? Можно же просто написать:
В данном контексте, действительно, применение оконных функций нецелесообразно, но, когда речь заходит о задаче:
Собрать дэшборд, в котором содержится информация о максимальной задолженности в каждом банке, а также средний размер процентной ставки в каждом банке в зависимости от сегмента, плюс еще количество договоров всего всем банкам (в голове рисуются множественные джойны из подзапросов и как-то сразу тяжело на душе). Однако, как я говорил выше, в одном select можно использовать много OVER, а также еще один прекрасный факт: набор строк в окне, связывается с текущей строкой, а не с группой агрегированных. Таким образом:
На примере AVG(procent_RATE) OVER (partition BY TB, segment) подробнее:
- Мы применяем AVG – агрегатную функцию по подсчету среднего значения к столбцу procent_RATE.
- Затем предложением OVER определяем, что будем работать с некоторым набором строк. По умолчанию, если указать OVER() с пустыми строками, то этот набор строк равен всей таблице.
- Предложением partition BY выделяем разделы в наборе строк по заданному условию, в нашем случае, в разбивке на Территориальные банки и Сегмент.
- В итоге, к каждой строке базовой таблицы применится функция по подсчету среднего из набора строк, разбитых на разделы (по Территориальным Банкам и Сегменту).
Другой тип оконных функций, надо признать, мой любимый и был использован для решения многих задач. Функции ранжирования для каждой строки в разделе возвращают значение рангов или рейтингов. Все ведь любят рейтинги, правда…?
Базовый набор данных: банки, отделы и количество ревизий.
Сами ранжирующие функции:
ROW_number – нумерует строки в результирующем наборе.
RANK -присваивает ранг для каждой строки, если найдутся одинаковые значения, то следующий ранг присваивается с пропуском.
DENSE_RANK -присваивает ранг для каждой строки, если найдутся одинаковые значения, то следующий ранг присваивается без пропуска.
NTILE – помогает разделить результирующий набор на группы.
Для понимания написанного, проранжируем таблицу по убыванию количества ревизий:
ROW_number – пронумеровал столбцы в порядке убывания количества ревизий.
RANK – проранжировал отделы во всех банках в порядке убывания количества ревизий, но как только встретились одинаковые значения (количество ревизий 95), функция присвоила им ранг 4, а следующее значение получило ранг 6.
DENSE_RANK – аналогично RANK, но как только встретились одинаковые значения, следующее значение получило ранг 5.
NTILE – функция помогла разбить таблицу на 3 группы (указал в аргументе). Так как в таблице 18 значений, в каждую группу попало по 6.
Найти второй отдел во всех банках по количеству ревизий.
Можно, конечно, воспользоваться чем-то вроде:
Но если речь идет не про второй отдел, а про трети? .. уже сложнее. Действительно, никто не списывает со счетов offset, но в этой статье говорится об оконных функциях, так почему бы не написать так:
Как и во всех других типах функций, здесь можно выделять разделы с помощью partitionby. Например, найти отдел в каждом банке, с меньшим количеством проведенных ревизий, для этого разделяем на секции по территориальным банкам, сортируем по возрастанию:
Оконные функции смещения помогут нам, когда необходимо обратиться к строке в наборе данных из окна, относительно текущей строки с некоторым смещением. Проще говоря, узнать, какое значение (событие/ дата) идет после/до текущей строки. Похоже на отличную штуку в предобработке лога данных.