3)Структуры данных. Очередь, стек.
Очередь — структура данных с дисциплиной доступа к элементам «первый пришёл — первый вышел». Добавление элемента возможно лишь в конец очереди, выборка — только из начала очереди, при этом выбранный элемент из очереди удаляется.
Обычно start указывает на голову очереди, end — на элемент, который заполнится, когда в очередь войдёт новый элемент. При добавлении элемента в очередь в q[end] записывается новый элемент очереди, а end уменьшается на единицу. Если значение end становится меньше 1, то мы как бы циклически обходим массив и значение переменной становится равным n. Извлечение элемента из очереди производится аналогично: после извлечения элемента q[start] из очереди переменная start уменьшается на 1. С такими алгоритмами одна ячейка из n всегда будет незанятой (так как очередь с n элементами невозможно отличить от пустой), что компенсируется простотой алгоритмов.
Преимущества данного метода: возможна незначительная экономия памяти по сравнению со вторым способом; проще в разработке.
Недостатки: максимальное количество элементов в очереди ограничено размером массива. При его переполнении требуется перевыделение памяти и копирование всех элементов в новый массив.
Стек— структура данных, в которой доступ к элементам организован по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»). Чаще всего принцип работы стека сравнивают со стопкой тарелок: чтобы взять вторую сверху, нужно снять верхнюю.

Добавление элемента, называемое также проталкиванием (push), возможно только в вершину стека (добавленный элемент становится первым сверху). Удаление элемента, называемое также выталкиванием (pop), тоже возможно только из вершины стека, при этом второй сверху элемент становится верхним.
4) Структуры данных. Односвязный, двухсвязный список. Линейные и кольцевые списки.
Структура данных — программная единица, позволяющая хранить и обрабатывать множество однотипных и/или логически связанных данных
В информатике, список — это абстрактный тип данных, представляющий собой упорядоченный набор значений, в котором некоторое значение может встречаться более одного раза.
Односвязный список (Однонаправленный связный список)

Здесь ссылка в каждом узле указывает на следующий узел в списке. В односвязном списке можно передвигаться только в сторону конца списка. Узнать адрес предыдущего элемента, опираясь на содержимое текущего узла невозможно.
Двусвязный список (Двунаправленный связный список)
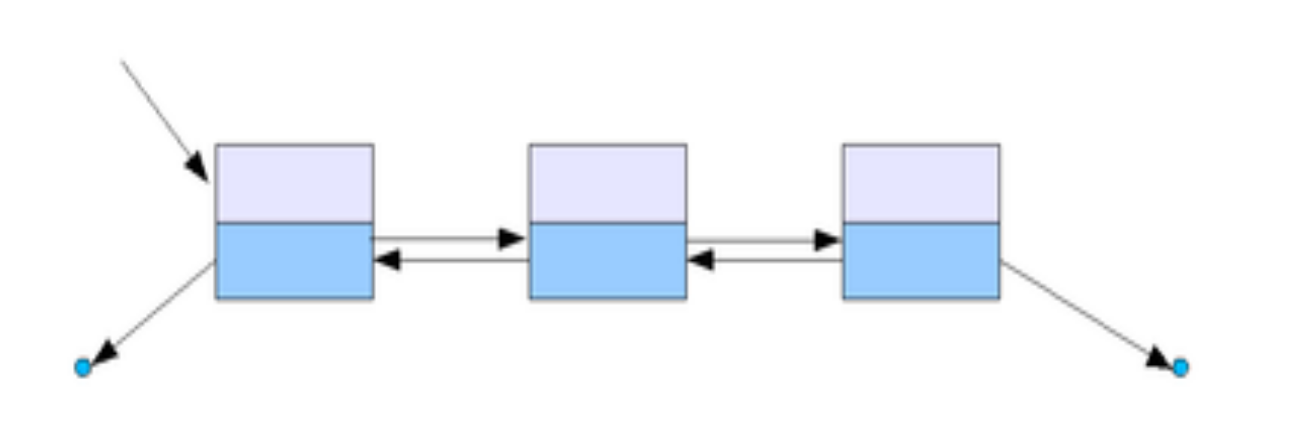
Здесь ссылки в каждом узле указывают на предыдущий и на последующий узел в списке. По двусвязному списку можно передвигаться в любом направлении — как к началу, так и к концу. В этом списке проще производить удаление и перестановку элементов, так как всегда известны адреса тех элементов списка, указатели которых направлены на изменяемый элемент.
Линейный однонаправленный список — это структура данных, состоящая из элементов одного типа, связанных между собой.
В информатике линейный список обычно определяется как абстрактный тип данных (АТД), формализующий понятие упорядоченной коллекции данных.
На практике линейные списки обычно реализуются при помощи массивов и связных списков. Иногда термин «список» неформально используется также как синоним понятия «связный список».
К примеру, АТД нетипизированного изменяемого списка может быть определён как набор из конструктора и четырёх основных операций:
операция, проверяющая список на пустоту;
операция добавления объекта в список;
операция определения первого (головного) элемента списка;
операция доступа к списку, состоящему из всех элементов исходного списка, кроме первого.
Кольцевой связный список
Разновидностью связных списков является кольцевой (циклический, замкнутый) список. Он тоже может быть односвязным или двусвязным. Последний элемент кольцевого списка содержит указатель на первый, а первый (в случае двусвязного списка) — на последний.
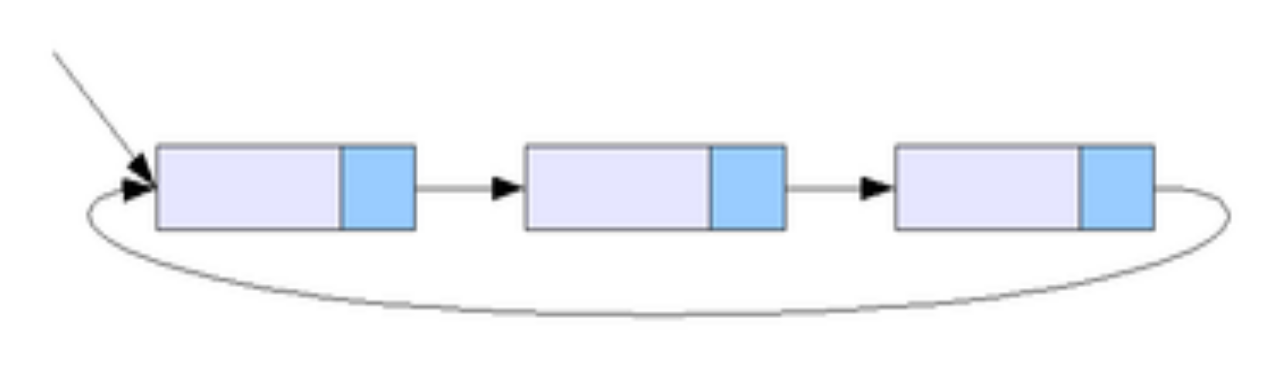
Реализация такой структуры происходит на базе линейного списка. С каждым кольцевым списком есть указатель на первый элемент. В этом списке константы NULL не существует.
Так же существуют циклические списки с выделенным головным элементом, облегчающие полный проход через список.
5) Задачи сортировки. Свойства алгоритмов сортировки. Сортировка пузырьком. Модификации.
Задача сортировки заключается в том, чтобы каждый элемент некоторой последовательности удовлетворял условию, что каждый последующий элемент больше предыдущего.
Свойства алгоритмов сортировки:
1 время сортировки – основной параметр, характеризующий быстродейственность алгоритма.
2 память – ряд алгоритмов требует выделения дополнительной памяти под временное хранение данных. При оценке используемой памяти обычно не учитывается место, которое занимает исходный массив и не зависящие от входной последовательности затраты памяти, например, на хранение кода программы.
3 устойчивость. Устойчивая сортировка не меняет взаимного расположения элементов, такое свойство может быть очень полезным, если элементы состоят из нескольких полей, причем сортировка происходит по одному из них.
4 естественность поведения – эффективность метода при обработке уже отсортированных или частично отсортированных данных. Алгоритм будет вести себя естественно, если учитывает эту характеристику входной последовательности и ведет себя лучше.
5 сфера применения. Внутренние сортировки – они работают с данными в оперативной памяти с произвольным доступом. Внешние сортировки – упорядочивают информацию, расположенную на внешних носителях, есть некоторые ограничения: доступ к носителю осуществляется последовательно, объем данных не позволяет разместиться в ОЗУ.
Идея: шаг сортировки состоит в проходе снизу вверх по массиву, по пути просматриваются пары соседних элементов. Если элементы некоторой пары находятся в неправильном порядке, то их меняют местами.
Методы улучшения: первое улучшение заключается, в запоминании производился ли на данном проходе какой-либо обмен. Если нет, алгоритм заканчивает работу; процесс улучшения можно продолжить, если запоминать не только сам факт обмена, но и индекс последнего обмена.
6) Задачи сортировки. Свойства алгоритмов сортировки. Сортировка вставками. Модификации.
Идея: делаются проходы по части массива, и в его начале «вырастает» отсортированная последовательность. Последовательность a[0]. a[i] упорядочена. При этом по ходу алгоритма в нее будут вставляться (см. название метода) все новые элементы. Как говорилось выше, последовательность к этому моменту разделена на две части: готовую a[0]. a[i] и неупорядоченную a[i+1]. a[n]. На следующем, (i+1)-м каждом шаге алгоритма берем a[i+1] и вставляем на нужное место в готовую часть массива. Поиск подходящего места для очередного элемента входной последовательности осуществляется путем последовательных сравнений с элементом, стоящим перед ним. В зависимости от результата сравнения элемент либо остается на текущем месте (вставка завершена), либо они меняются местами и процесс повторяется.
Алгоритм можно слегка улучшить. Заметим, что на каждом шаге внутреннего цикла проверяются 2 условия. Можно объединить из в одно, поставив в начало массива специальный сторожевой элемент. Он должен быть заведомо меньше всех остальных элементов массива. Тогда при j=0 будет заведомо верно a[0] <= x. Цикл остановится на нулевом элементе, что и было целью условия j>=0. Таким образом, сортировка будет происходить правильным образом, а во внутреннем цикле станет на одно сравнение меньше. Однако, отсортированный массив будет не полон, так как из него исчезло первое число. Для окончания сортировки это число следует вернуть назад, а затем вставить в отсортированную последовательность a[1]. a[n].
7) Задачи сортировки. Свойства алгоритмов сортировки. Сортировка Шелла. Модификации.
Сортировка Шелла является довольно интересной модификацией алгоритма сортировки простыми вставками. Рассмотрим следующий алгоритм сортировки массива a[0].. a[15].
1. Вначале сортируем простыми вставками каждые 8 групп из 2-х элементов (a[0], a[8[), (a[1], a[9]), . , (a[7], a[15]).
2. Потом сортируем каждую из четырех групп по 4 элемента (a[0], a[4], a[8], a[12]), . (a[3], a[7], a[11], a[15]). В нулевой группе будут элементы 4, 12, 13, 18, в первой — 3, 5, 8, 9 и т.п.
3. Далее сортируем 2 группы по 8 элементов, начиная с (a[0], a[2], a[4], a[6], a[8], a[10], a[12], a[14]).
4. В конце сортируем вставками все 16 элементов. Очевидно, лишь последняя сортировка необходима, чтобы расположить все элементы по своим местам. Hа самом деле они продвигают элементы максимально близко к соответствующим позициям, так что в последней стадии число перемещений будет весьма невелико. Последовательность и так почти отсортирована. Ускорение подтверждено многочисленными исследованиями и на практике оказывается довольно существенным. Единственной характеристикой сортировки Шелла является приращение — расстояние между сортируемыми элементами, в зависимости от прохода. В конце приращение всегда равно единице — метод завершается обычной сортировкой вставками, но именно последовательность приращений определяет рост эффективности.
Использованный в примере набор . 8, 4, 2, 1 — неплохой выбор,
особенно, когда количество элементов — степень двойки. Однако гораздо
лучший вариант предложил Р.Седжвик. Его последовательность имеет вид

При использовании таких приращений среднее количество операций: O(n7/6), в худшем случае — порядка O(n4/3). Обратим внимание на то, что последовательность вычисляется в порядке, противоположном используемому: inc[0] = 1, inc[1] = 5, . Формула дает сначала меньшие числа, затем все большие и большие, в то время как расстояние между сортируемыми элементами, наоборот, должно уменьшаться. Поэтому массив приращений inc вычисляется перед запуском собственно сортировки до максимального расстояния между элементами, которое будет первым шагом в сортировке Шелла. Потом его значения используются в обратном порядке. При использовании формулы Седжвика следует остановиться на значении
Структуры данных: кольцевой (циклический, замкнутый) связный список
Кольцевой (циклический, замкнутый) связный список — это разновидность связного списка, при которой первый элемент указывает на последний, а последний — на первый. Кольцевой (циклический, замкнутый) связный список можно сделать как из односвязного (однонаправленного), так и из двусвязного (двунаправленного) списка.
Кольцевой связный список из односвязного
В односвязном списке указатель next последнего узла указывает на первый узел:
Кольцевой связный список из двусвязного
В двусвязном списке указатель next последнего узла указывает на первый узел, а указатель previous первого — на последний. Так получается кольцевой связный список в обоих направлениях:
Здесь надо учитывать следующие важные моменты:
- next последней ссылки указывает на первую ссылку списка в обоих случаях — в односвязном списке и в двусвязном.
- previous первой ссылки указывает на последнюю ссылку в двусвязном списке.
Базовые операции
Это основные операции, проводимые над списками:
- Вставка элемента в начало списка.
- Удаление элемента из начала списка.
- Отображение списка.
Вставка
В этом коде показана операция вставки в кольцевом связном списке на основе односвязного :
Пример
Удаление
В этом коде показана операция удаления в кольцевом связном списке на основе односвязного:
Отображение списка
В этом коде показана операция отображения списка в кольцевом связном списке:
Чем отличается кольцевой список от линейного
Линейный список — это динамическая структура данных, каждый элемент которой посредством указателя связывается со следующим элементом.
Из определения следует, что каждый элемент списка содержит поле данных ( D ata ) (оно может иметь сложную структуру) и поле ссылки на следующий элемент ( next ). Поле ссылки последнего элемента должно содержать пустой указатель ( NULL ).
Так как ссылка всего одна (только на следующий элемент), то такой список является односвязным .
Когда говорят о линейном списке, то, как правило, подразумевают именно односвязный список.
Пример . Сформировать список, содержащий целые числа 3, 5, 1, 9 .
Решение . При работе с динамическими структурами данных можно рекомендовать следующий порядок действий.
а) Прежде всего необходимо определить две структуры :
структура, содержащая характеристики данных, то есть все те поля с данными, которые необходимы для решения поставленной задачи (в нашем случае имеется всего одно поле целого типа). Назовём эту структуру Data ;
структура, содержащая поле типа Data и поле — адрес последующего элемента next . Вторую структуру назовём List .
Тексты этих структур необходимо расположить в начале программы (до main() и других функций). Вот возможная реализация структур:
Такой подход позволит в дальнейшем изменять в широких пределах структуру с собственно данными, никак не затрагивая при этом основную структуру List .
Итак, мы описали структурный тип, с помощью которого можно создать наш односвязный список. Графически создаваемый список можно изобразить так, как это показано на рисунке ниже:
б) В программе (обычно в функции main() ) определяем указатель на начало будущего списка :
Пока список пуст, и указатель явно задан равным константе NULL .
в) Выполняем первоначальное заполнение списка .
Создадим первый элемент:
u = new List; // Выделяем память под элемент списка
u->d.a = 3; // Заполняем поля с данными
// (здесь это всего одно поле)
u->next = NULL;// Указатель на следующий элемент пуст
После включения первого элемента список можно изобразить так:
Продолжим формирование списка, добавляя новые элементы в его конец. Для удобства заведём вспомогательную переменную-указатель, которая будет хранить адрес последнего элемента списка:
x = u; // Сейчас последний элемент списка совпадает с его началом
Таким образом, к области памяти можно обратиться через два указателя.
Выделяем место в памяти для следующего элемента списка и перенаправляем указатель x на выделенную область памяти:
x->next = new List;
Затем определяем значение этого элемента списка:
Получилась такая схема:
Этот процесс продолжаем до тех пор, пока не будет сформирован весь список.
Действия со сформированным списком
Сформировав начальный список, можно выполнять с ним различные действия. Настоятельно рекомендуется каждую операцию со списком оформлять в виде отдельной функции. Такой подход заметно упрощает разработку программы и возможную её дальнейшую модификацию. Понятно, что и только что рассмотренное формирование начального списка также лучше записать в виде функции.
1. Просмотр списка — осуществляется последовательно, начиная с его начала. Указатель последовательно ссылается на первый, второй, и т.д. элементы списка до тех пор, пока весь список не будет пройден. Приведём пример реализации просмотра, например, для вывода списка на экран монитора :
void Print(List *u)
Обратиться к функции можно так:
Здесь и далее в примерах u — это указатель на начало списка.
2. Поиск первого вхождения в список элемента, соответствующего заданным требованиям:
List * Find(List *u, Data &x)
if(p->d.a == x.a) // условие для поиска
Возможный вызов функции:
List * v = Find(u, x);
где x — объект типа Data .
3. Добавление нового элемента в начало списка :
void Add_Beg(List **u, Data &x)
List *t = new List;
Возможный вызов функции:
где x — объект типа Data .
4. Вставка нового элемента в произвольное место списка по какому-нибудь принципу, например, вставка в отсортированный по возрастанию список :
void Insert(List **u, Data &x)
// вставка в список одного элемента перед элементом,
// меньшим или равным данному x
List *p = new List;
if(*u == 0) // исходный список пуст — вставка в начало
if(t->d.a >= p->d.a) // исходный список не пуст —
// вставка в начало
t->next = p; // добавляем в конец списка
Возможный вызов функции:
где x — объект типа Data .
Эта функция позволяет сразу формировать упорядоченный список .
5. Удаление элемента из линейного списка :
void Delete(List **u, Data &x)
if(*u == 0) // исходный список пуст — удалять нечего!
if(t->d.a == x.a) // исходный список не пуст —
// исходный список не пуст —
//удаляется не первый элемент
Возможный вызов функции:
где x — объект типа Data .
6. Удаление (очистка) всего списка
Когда данные, хранящиеся в списке, становятся ненужными, можно очистить весь список, т.е. освободить память, которую занимали все элементы списка. Выполнять эту операцию желательно сразу после того, как список стал не нужен. Реализация этой операции может быть такой:
void Clear(List **u)
// удаление (очистка) всего списка
Возможный вызов функции:
Мы рассмотрели наиболее важные действия со списками. По аналогии с ними можно реализовать и другие действия, которые могут потребоваться для решения практических задач.
Двухсвязные линейные списки
Как мы уже говорили, линейные списки могут быть односвязными и двухсвязными.
Каждый элемент односвязного списка кроме собственно данных содержит поле с адресом следующего элемента. Работу с такими списками мы только что рассмотрели.
В двухсвязном списке каждый элемент имеет поля с данными и два указателя: один указатель хранит адрес предшествующего элемента списка, второй — адрес последующего элемента. Вполне естественно для работы с двухсвязным списком использовать два указателя, хранящие адреса начала и конца такого списка. На рисунке ниже даётся графическое представление двухсвязного списка.
Рассмотрим особенности работы с двухсвязным списком.
1. Как и в случае с односвязным списком, создадим две структуры. Тексты этих структур расположим в начале программы (до main() и других функций). Вот возможная реализация структур:
List2 *prev; // указатель на предшествующий элемент
List2 *next; // указатель на последующий элемент
2. Затем создаём два указателя:
List2 *Begin = NULL; // Начало списка
List2 *End = NULL; // Конец списка
3. Теперь можно формировать какой-то начальный список. Делаем это по аналогии с тем, как делали при работе с односвязными списками. Начнём формировать список из трёх чисел 3 , 5 и 1 :
// Создаём первый элемент
List2 *t = new List2;
// Настроим на него оба указателя
// Создаём второй элемент
t->next = new List2;
// Создаём третий элемент
t->next = new List2;
Всё, список из трёх чисел создан. Приведём хотя бы некоторые действия с этим списком.
1. Обход списка в прямом направлении и его вывод на экран монитора :
void print_forward(List2 *Begin)
Возможный вызов функции:
Как видим, полученная реализация по сути является копией функции print() для печати односвязного списка.
2. Обход списка в обратном направлении и его вывод на экран монитора :
void print_back(List2 *End)
Возможный вызов функции:
И здесь сходство большое. Важно обратить внимание на оператор, за счет которого выполняется движение назад:
На других операциях с двухсвязными списками останавливаться не будем, так как их можно разработать по аналогии с операциями для односвязных списков.
Кольцевой список
Кольцевой список — это список, у которого последний элемент связан с первым. Кольцевой список можно сделать как односвязным, так и двухсвязным. Рассмотрим вкратце односвязный кольцевой список.
Схема кольцевого списка представлена на рисунке ниже (используем те же данные, что и для ранее рассмотренного односвязного списка, т.е. список из чисел 3, 5, 1, 9 ):
Используем те же структуры ( Data и List ), что применяли для односвязного списка. Точно так же определяем указатель на начало будущего списка:
и так же делаем начальное заполнение списка. Но в конце, после того, как для нашего примера мы занесли число 9 в список, требуется «замкнуть» список на начало :
В итоге будет получен кольцевой список.
Операции для кольцевого списка можно выполнять те же, что и для обычного списка, но здесь будет присутствовать одна особенность: список замкнут, поэтому проверка того факта, что достигнут конец цикла, выполняется по другому. Покажем это на примере распечатки кольцевого цикла:
Русские Блоги
Линейный список (последовательный список, линейный связанный список, кольцевой односвязный список, двусвязный список)
1. Основная концепция линейного стола:
(1). Определение линейной таблицы:
Линейная таблица — это конечная последовательность, состоящая из n (n> = 0) элементов данных одного типа. Отметить как: L=(a1,a2. ai. an )
Количество n элементов в линейной таблице определяется как длина линейной таблицы, когда Пустая таблица при n = 0 。
Когда n> 0, логическая структура линейной таблицы показана на рисунке ниже: 
Логические характеристики:
(1) .Если он содержит хотя бы один элемент, есть только один начальный элемент;
(2) .Если он содержит хотя бы один элемент, есть только один элемент;
(3) .В дополнение к начальному элементу другие элементы имеют только один элемент-предшественник;
(4) За исключением хвостового узла, другие элементы имеют только один элемент-преемник.
(5). Каждый элемент в линейной таблице имеет уникальный порядковый номер (логический порядковый номер). В одной линейной таблице может быть несколько элементов с одинаковым значением, но их порядковые номера разные.
Несколько концепций линейных таблиц: 
(2). Основные операции линейных таблиц:
- Основные операции линейного стола L:
Для вышеупомянутой линейной таблицы абстрактного типа данных могут быть выполнены некоторые более сложные операции. Например, объединение двух или более линейных таблиц в одну; или разделение линейной таблицы на две или более; или повторное копирование линейной таблицы.
2. Список абстрактных типов данных линейной таблицы:
2. Последовательное представление и реализация линейной таблицы:
(1). Концепция:
- определение : Порядок линейной таблицы означает, что элементы данных линейной таблицы последовательно сохраняются в одной и той же группе ячеек памяти с последовательными адресами.
- Отношение между местом хранения LOC (a i + 1) элемента данных i + 1 и местом хранения LOC (ai) элемента данных i в линейной таблице следующее: LOC(a i+1)=LOC(ai)+l ;
- Вообще говоря, место хранения i-го элемента данных ai линейной таблицы: LOC(ai)=LOC(a1)+(i-1)*l ;

- Пока начальная позиция линейной таблицы определена, любой элемент данных в линейной таблице может быть доступен случайным образом, поэтому структура данных хранения линейной таблицы является одной Случайное хранение Структура данных.
(2). Выделить память:
- Линейный стол Динамическое размещение Последовательная структура хранения:
- Линейный стол Статическое размещение Последовательная структура хранения:
выделить: Динамическое распределение может быть расширено после того, как пространство израсходовано, а статическое — нет.
(3). Реализация основных операций таблицы последовательности:
1**.** Инициализируем линейную таблицу:
Основная операция: установите для поля длины таблицы последовательности L значение 0
Код выглядит следующим образом:
2. Уничтожьте линейную таблицу:
Основная операция: поскольку пространство памяти таблицы последовательностей L выделяется динамически, его следует активно освобождать, когда в нем нет необходимости.
Код выглядит следующим образом:
3. Операция по поиску длины линейной таблицы:
Основная операция: вернуть значение поля длины таблицы последовательности L.
Код выглядит следующим образом:
4. Найдите i-й элемент в линейной таблице:
Основная операция: вернуть специальное значение 0 (ложь), если битовая последовательность (логический порядковый номер) i недействительна, вернуть 1 (истина), если она действительна, и использовать ссылочный параметр e для возврата i-го элемента Значение
Код выглядит следующим образом:
5. Поиск по значению:
Основная операция: найти первый элемент со значением e в таблице последовательностей L и вернуть его позицию (логический порядковый номер) после его нахождения, в противном случае вернуть 0 (поскольку логический порядковый номер линейной таблицы равен 1 Вначале мы используем 0, чтобы указать, что элемент со значением e не найден).
Код выглядит следующим образом:
6. Алгоритм вставки:
Основная операция:
· Новый элемент e вставляется в позицию логического порядкового номера i в таблице последовательностей L (если вставка успешна, элемент e становится i-м элементом линейной таблицы);
· Допустимое значение i — 1 <= i <= L.length + 1. Если i недействительно, возвращается 0 (что указывает на ошибку вставки);
· При активации переместите L.elem [i-1… L.length-1] на одну позицию назад, вставьте e в L.elem [i-1] и увеличьте длину таблицы последовательности. 1 и вернуть 1 (что указывает на успешную вставку).
Код выглядит следующим образом:
7. Удалить алгоритм:
Основная операция:
· Номер логической последовательности в таблице последовательности удаления L — это элемент i;
· Допустимое значение i — 1 <= i <= L.length. Когда i недействительно, возвращается 0 (удаление не удалось);
· Если допустимо, переместите L.elem [i . L.length-1] вперед на одну позицию, уменьшите длину таблицы последовательности на 1 и верните 1 (что указывает на успешное удаление).
Код выглядит следующим образом:
3. Цепное представление и реализация линейной таблицы:
(1). Линейный связанный список:
Ⅰ. Концепция:
- Цепная структура хранения линейного стола характеризуется набором Произвольная единица хранения Храните элементы данных линейной таблицы (эта группа единиц хранения может быть непрерывной или прерывистой).
- Следовательно, чтобы выразить логическую взаимосвязь между ai и ai + 1, для ai, помимо хранения собственной информации, также необходимо сохранить сообщение, указывающее его непосредственного преемника (то есть место хранения непосредственного преемника). Эти две части информации образуют хранимое изображение элемента данных ai, называемого Узел , На следующем рисунке представлена принципиальная схема узла:

- Среди них домен, в котором напрямую хранится информация об элементах данных, называется Поле данных , Домен, в котором хранится непосредственно следующее место хранения, называется Поле указателя , Информация, хранящаяся в поле указателя, называется указатель или цепь 。
- Линейная структура:

- Первый узел элемента в связанном списке называется Первый узел , Последний элемент называется Конечный узел , Его поле указателя (следующее) пусто (NULL).
Ⅱ. Объявление типа узла:
Ⅲ. Осуществление основных операций:
1. Инициализируйте односвязный список:
Основная операция: создать пустой односвязный список, в котором есть только один головной узел, на который указывает L. Следующее поле узла пусто, и значение в поле данных не задано.
Код выглядит следующим образом:
2. Уничтожьте односвязный список:
Код выглядит следующим образом:
3. Найдите длину односвязного списка:
Основная операция: установить целочисленную переменную i в качестве счетчика, начальное значение i равно 0, а p изначально указывает на первую базу данных. Затем следующие поля глаз просматриваются в обратном направлении одно за другим, и значение i увеличивается на 1. Когда узел, на который указывает p, пуст, процесс завершается, и значение i является длиной таблицы.
Код выглядит следующим образом:
4. Найдите элемент, значение которого равно e, в односвязном списке:
Основная операция: используйте p для обхода узлов в односвязном списке L с самого начала, используйте счетчик i для подсчета пройденных узлов, начальное значение равно 0. Во время обхода, если p не Если он пуст, узел, на который указывает p, является узлом, который нужно найти. Если поиск успешен, алгоритм возвращает порядок i. В противном случае алгоритм возвращает 0, чтобы указать, что такой узел не найден.
Код выглядит следующим образом:
5. Вставка односвязного списка:
Основная операция:
· Вставить узел со значением x в i-ю позицию в односвязном списке L.
· Теперь найдите узел i-1 в односвязном списке L и верните 0, если он не найден.
· Когда он найден, укажите на узел с помощью p, создайте новый узел s со значением x и вставьте его после узла p.
Код выглядит следующим образом:
6. Удаление односвязного списка:
Основная операция: · Удалить i-й узел в односвязном списке L;
· Сначала найдите i-1-й узел в односвязном списке L, если он не найден, верните 0.
· При обнаружении укажите узел с помощью p, а затем пусть q указывает на узел-преемник (то есть узел, который необходимо удалить).
· Если узел, на который указывает q, пуст, вернуть 0, в противном случае удалить узел q и освободить его занятое пространство
Код выглядит следующим образом:
(2). Циркулярный односвязный список:
- Циркулярный односвязный список — это вариант односвязного списка. Следующая точка конечного узла связанного списка не NULL, а указывает на передний конец односвязного списка 。

- Чтобы упростить операцию, головной узел часто добавляется в кольцевой односвязный список.

- Пустое условие для кругового односвязного списка: L->next == L ;
- Особенностью односвязного списка является то, что, пока известен адрес определенного узла в таблице, можно искать адреса всех других узлов.
- В процессе поиска ни одно из следующих полей узлов не пусто
(3). Двусвязный список:
Ⅰ. Концепция:
- Двусвязный список относится к линейному связанному списку, по которому можно перемещаться в направлениях предшественник и последователь. Структура каждого узла двусвязного списка:

- Два указателя в двусвязном списке указывают на логическую связь между узлами.
- Поле указателя, указывающее на предыдущий узел
- Поле указателя рядом с его узлом-преемником
Ⅱ. Объявление типа двусвязного списка:
Как и односвязные списки, двусвязные списки также делятся на Ациклический двусвязный список (называемый двусвязным списком) с участием Двойной круговой связанный список 。
Ⅲ. Основные операции двустороннего кругового связного списка:
1. Расчет длины:
Основная операция: она точно такая же, как алгоритм вычисления длины одного кругового связанного списка.
Код выглядит следующим образом:
2. Вставить:
Основная операция: сначала найдите i-1-й узел в дважды кольцевом связанном списке, в случае успеха найдите узел (указанный p), создайте новое значение с помощью e Для узла s вставьте узел s после p.
Код выглядит следующим образом:
3. Удалить:
Основная операция: сначала найдите i-й узел в двустороннем круговом связанном списке, в случае успеха найдите узел (указанный p) и передайте указатели узла-предшественника и узла-преемника Изменение домена для удаления узла p
Код выглядит следующим образом: