Оценка сложности и эффективности алгоритмов
Их используют для того, чтобы сравнивать алгоритмы между собой. Одни алгоритмы работают быстрее, но требуют больше памяти, а другие наоборот.
Для большинства алгоритмов время выполнения и количество памяти нельзя выразить одним числом. Чем больше элементов будет во входящем массиве, тем дольше будут выполняться поиск и сортировка.
Для описания эффективности алгоритмов придумали нотацию Big-O.
Постоянная сложность — О(1)
Самый эффективный алгоритм в теории работает за постоянное время и расходует постоянное количество памяти. Как ни увеличивай объем входящих данных, сложность алгоритма не повысится. Эффективность (или сложность) такого алгоритма называют константным и записывают как O(1).
Пример алгоритма с постоянной сложностью:
На вход получаем массив arr и индекс i . Возвращаем элемент массива на позиции i .
Скорость выполнения и объем требуемой памяти этого алгоритма не зависит от длины входящего массива, поэтому сложность считается постоянной.
Линейная сложность — O(n)
Сложность многих алгоритмов растет прямо пропорционально изменению количества входящих данных.
Хороший пример — линейный поиск:
Если поиск в массиве из 10 элементов занимает 5 секунд, то в массиве из 100 элементов мы будем искать 100 секунд. В 10 раз дольше.
Такую сложность (эффективность) называют линейной и записывают как О(n).
Но, заметь, что алгоритму линейного поиска не нужна дополнительная память. Поэтому, по этой характеристике он получает высший балл — O(1).
Квадратичная сложность — O(n^2^)
Простые алгоритмы сортировки, такие как сортировка пузырьком или сортировка выбором имеют сложность О(n^2^).
Это не очень эффективно. При росте длины массива в 10 раз, время выполнения алгоритма увеличится в 10^2^ (в 100) раз!
Так происходит из-за того, что в алгоритме используется вложенный цикл. Сложность одного прохода мы оцениваем как O(n). Но проходим мы его не один раз, а **n **раз. Поэтому и получается сложность O(n * n) = O(n^2^).
Логарифмическая сложность — O(log n)
Алгоритмы, которые на каждой итерации могут сократить количество анализируемых данных имеют логарифмическую сложность — O(log n).
В качестве примера можно представить двоичный поиск. На каждой итерации мы можем отбросить половину данных и работать только с оставшимися.
Name already in use
web-developer-cheatsheet / General / Алгоритмическая сложность.md
- Go to file T
- Go to line L
- Copy path
- Copy permalink
0 contributors
Users who have contributed to this file
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents
Copy raw contents
Copy raw contents
Сложность алгоритмов обычно оценивают по времени выполнения или по используемой памяти. В обоих случаях сложность зависит от размеров входных данных: массив из 100 элементов будет обработан быстрее, чем аналогичный из 1000. При этом точное время мало кого интересует: оно зависит от процессора, типа данных, языка программирования и множества других параметров. Важна лишь асимптотическая сложность, т. е. сложность при стремлении размера входных данных к бесконечности.
Допустим, некоторому алгоритму нужно выполнить 4n^3 + 7n условных операций, чтобы обработать n элементов входных данных. При увеличении n на итоговое время работы будет значительно больше влиять возведение n в куб, чем умножение его на 4 или же прибавление 7n . Тогда говорят, что временная сложность этого алгоритма равна О(n^3) , т. е. зависит от размера входных данных кубически.
Использование заглавной буквы О (или так называемая О-нотация) пришло из математики, где е е применяют для сравнения асимптотического поведения функций. Формально O(f(n)) означает, что время работы алгоритма (или объ ем занимаемой памяти) раст ет в зависимости от объ ема входных данных не быстрее, чем некоторая константа, умноженная на f(n) .
O(1) — константная сложность
Случается, что время работы алгоритма вообще не зависит от размера входных данных. Тогда сложность обозначают как O(1) . Например, для определения значения третьего элемента массива не нужно ни запоминать элементы, ни проходить по ним сколько-то раз. Всегда нужно просто дождаться в потоке входных данных третий элемент и это будет результатом, на вычисление которого для любого количества данных нужно одно и то же время.
O(n) — линейная сложность
Такой сложностью обладает, например, алгоритм поиска наибольшего элемента в не отсортированном массиве. Нам прид ется пройтись по всем n элементам массива, чтобы понять, какой из них максимальный.
O(log n) — логарифмическая сложность
Простейший пример — бинарный поиск. Если массив отсортирован, мы можем проверить, есть ли в н ем какое-то конкретное значение, методом деления пополам. Проверим средний элемент, если он больше искомого, то отбросим вторую половину массива — там его точно нет. Если же меньше, то наоборот — отбросим начальную половину. И так будем продолжать делить пополам, в итоге проверим log n элементов.
O(n^2) — квадратичная сложность
Такую сложность имеет, например, алгоритм сортировки вставками. В канонической реализации он представляет из себя два вложенных цикла: один, чтобы проходить по всему массиву, а второй, чтобы находить место очередному элементу в уже отсортированной части. Таким образом, количество операций будет зависеть от размера массива как n * n , т. е. n2 .
Анализ сложности алгоритмов. Примеры
Алгоритм — это точное предписание, однозначно определяющее вычислительный процесс, ведущий от варьируемых начальных данных к искомому результату [1].
При разработке алгоритмов очень важно иметь возможность оценить ресурсы, необходимые для проведения вычислений, результатом оценки является функция сложности (трудоемкости). Оцениваемым ресурсом чаще всего является процессорное время (вычислительная сложность) и память (сложность алгоритма по памяти). Оценка позволяет предсказать время выполнения и сравнивать эффективность алгоритмов.
Содержание:
Модель RAM (Random Access Machine)
Каждое вычислительное устройство имеет свои особенности, которые могут влиять на длительность вычисления. Обычно при разработке алгоритма не берутся во внимание такие детали, как размер кэша процессора или тип многозадачности, реализуемый операционной системой. Анализ алгоритмов проводят на модели абстрактного вычислителя, называемого машиной с произвольным доступом к памяти (RAM).
Модель состоит из памяти и процессора, которые работают следующим образом:
- память состоит из ячеек, каждая из которых имеет адрес и может хранить один элемент данных;
- каждое обращение к памяти занимает одну единицу времени, независимо от номера адресуемой ячейки;
- количество памяти достаточно для выполнения любого алгоритма;
- процессор выполняет любую элементарную операцию (основные логические и арифметические операции, чтение из памяти, запись в память, вызов подпрограммы и т.п.) за один временной шаг;
- циклы и функции не считаются элементарными операциями.
Несмотря на то, что такая модель далека от реального компьютера, она замечательно подходит для анализа алгоритмов. После того, как алгоритм будет реализован для конкретной ЭВМ, вы можете заняться профилированием и низкоуровневой оптимизацией, но это будет уже оптимизация кода, а не алгоритма.
Подсчет операций. Классы входных данных
Одним из способов оценки трудоемкости (\(T_n\)) является подсчет количества выполняемых операций. Рассмотрим в качестве примера алгоритм поиска минимального элемента массива.
При выполнении этого алгоритма будет выполнена:
- N — 1 операция присваивания счетчику цикла i нового значения;
- N — 1 операция сравнения счетчика со значением N;
- N — 1 операция сравнения элемента массива со значением min;
- от 1 до N операций присваивания значения переменной min.
Точное количество операций будет зависеть от обрабатываемых данных, поэтому имеет смысл говорить о наилучшем, наихудшем и среднем случаях. При этом худшему случаю всегда уделяется особое внимание, в том числе потому, что «плохие» данные могут быть намеренно поданы на вход злоумышленником.
Понятие среднего случая используется для оценки поведения алгоритма с расчетом на то, что наборы данных равновероятны. Однако, такая оценка достаточно сложна:
- исходные данные разбиваются на группы так, что трудоемкость алгоритма (\(t_i\)) для любого набора данных одной группы одинакова;
- исходя из доли наборов данных группы в общем числе наборов, рассчитывается вероятность для каждой группы (\(p_i\));
- оценка среднего случая вычисляется по формуле: \(\sum\limits_
Асимптотические обозначения
Подсчет количества операций позволяет сравнить эффективность алгоритмов. Однако, аналогичный результат можно получить более простым путем. Анализ проводят с расчетом на достаточно большой объем обрабатываемых данных (\( n \to \infty \)), поэтому ключевое значение имеет скорость роста функции сложности, а не точное количество операций.
При анализе скорости роста игнорируются постоянные члены и множители в выражении, т.е. функции \(f_x = 10 \cdot x^2 + 20 \) и \( g_x = x^2\) эквивалентны с точки зрения скорости роста. Незначащие члены лишь добавляют «волнистости», которая затрудняет анализ.
В оценке алгоритмов используются специальные асимптотические обозначения, задающие следующие классы функций:
- \(\mathcal
(g)\) — функции, растущие медленнее чем g; - \(\Omega(g)\) — функции, растущие быстрее чем g;
- \(\Theta(g)\) — функции, растущие с той же скоростью, что и g.
Запись \(f_n = \mathcal
Ограниченность функции g снизу функцией f записывается следующим образом: \(g_n =\Omega(f_n)\). Нотации \(\Omega\) и \(\mathcal

Асимптотические обозначения «О большое» и «Омега большое»
Если функции f и g имеют одинаковую скорость роста (\(f_n = \Theta(g_n)\)), то существуют положительные константы \(c_1\) и \(c_2\) такие, что \(\exists n_0 > 0 : \forall n > n_0, f_n \leq c_1 \cdot g_n, f_n \geq c_2 \cdot g_n\). При этом \(f_n = \Theta(g_n) \Leftrightarrow g_n = \Theta(f_n)\).

Асимптотическое обозначение «Тета большое»
Примеры анализа алгоритмов
Алгоритм поиска минимального элемента массива, приведенный выше, выполнит N итераций цикла. Трудоемкость каждой итерации не зависит от количества элементов массива, поэтому имеет сложность \(T^
Алгоритм пузырьковой сортировки (bubble sort) использует два вложенных цикла. Во внутреннем последовательно сравниваются пары элементов и если оказывается, что элементы стоят в неправильном порядке — выполняется перестановка. Внешний цикл выполняется до тех пор, пока в массиве найдется хоть одна пара элементов, нарушающих требуемый порядок [2].
Трудоемкость функции swap не зависит от количества элементов в массиве, поэтому оценивается как \(T^
- \(T^
_n = \mathcal (\sum\limits_ 1) = \mathcal (\sum\limits_ (n ^2)\); - \(T^
_n = \Omega(1 \cdot \sum\limits_ 1) = \Omega(n)\).
В алгоритме сортировки выбором массив мысленно разделяется на упорядоченную и необработанную части. На каждом шаге из неупорядоченной части массива выбирается минимальный элемент и добавляется в отсортированную часть [2].
Для поиска наименьшего элемента неупорядоченной части массива используется функция indMin, принимающая массив, размер массива и номер позиции, начиная с которой нужно производить поиск. Анализ сложности этой функции можно выполнить аналогично тому, как это сделано для функции min — количество операций линейно зависит от количества обрабатываемых элементов: \( T^
У сортировки выбором нет ветвлений, которые могут внести различия в оценку наилучшего и наихудшего случаев, ее трудоемкость: \(T^
Математический аппарат анализа алгоритмов
Выше были рассмотрены асимптотические обозначения, используемые при анализе скорости роста. Они позволяют существенно упростить задачу отбросив значительную часть выражения. Однако, в математическом анализе имеется целый ворох таких приемов.
Формулы суммирования
В примерах, рассмотренных выше, мы уже сталкивались с нетривиальными формулами суммирования. Чтобы дать оценку суммы можно использовать ряд известных тождеств:
- вынос постоянного множителя за знак суммы: \(\sum\limits_
(c \cdot f_i) = c \cdot \sum\limits_ \cdot f_i\); - упрощение суммы составного выражения: \(\sum\limits_
(f_i + g_i) = \sum\limits_ (f_i) + \sum\limits_ (g_i)\); - сумма чисел арифметической прогрессии: \(\sum\limits_
(i^p) = \Theta(n^ - сумма чисел геометрической прогрессии: \(\sum\limits_
(a^i) = \frac — 1)>\). При \( n \to \infty \) возможны 2 варианта: - если a < 1, то сумма стремится к константе: \(\Theta(1)\);
- если a > 1, то сумма стремится к бесконечности: \(\Theta(a^
- если a = 0, формула неприменима, сумма стремится к N: \(\Theta(n)\);
Первые из этих тождеств достаточно просты, их можно вывести используя метод математической индукции. Если под знаком суммы стоит более сложная формула, как в двух последних тождествах — суммирование можно заменить интегрированием (взять интеграл функции гораздо проще, ведь для этого существует широкий спектр приемов).
Суммирование и интегрирование
Известно, что интеграл можно понимать как площадь фигуры, размещенной под графиком функции. Существует ряд методов аппроксимации (приближенного вычисления) интеграла, к ним относится, в частности, метод прямоугольников. Площадь под графиком делится на множество прямоугольников и приближенно вычисляется как сумма их площадей. Следовательно, возможен переход от интеграла к сумме и наоборот.

аппроксимация интеграла левыми прямоугольниками

аппроксимация интеграла правыми прямоугольниками
На рисунках приведен пример аппроксимации функции \(f_x = \log x\) левыми и правыми прямоугольниками. Очевидно, они дадут верхнюю и нижнюю оценку площади под графиком:
- \(\int\limits_a^n f_x dx \leq \sum\limits_
f_i \leq \int\limits_ - \(\int\limits_a^n f_x dx \geq \sum\limits_
f_i \geq \int\limits_
В частности, такой метод позволяет оценить алгоритмы, имеющие логарифмическую сложность (две последние формулы суммирования).
Сравнение сложности алгоритмов. Пределы
Сложность алгоритмов определяется для больших объемов обрабатываемых данных, т.е. при \(n\to\infty\). В связи с этим, при сравнении трудоемкости двух алгоритмов можно рассмотреть предел отношения функций их сложности: \(\lim\limits_
\frac \). В зависимости от значения предела возможно сделать вывод относительно скоростей роста функций: - предел равен константе и не равен нулю, значит функции растут с одной скоростью:\(f_n = \Theta(g_n)\);
- предел равен нулю, следовательно \(g_n\) растет быстрее чем \(f_n\): \(f_n = \mathcal
(g_n)\); - предел равен бесконечности, \(g_n\) растет медленнее чем \(f_n\): \(f_n = \Omega(g_n)\).
Если функции достаточно сложны, то такой прием значительно упрощает задачу, т.к. вместо предела отношения функций можно анализировать предел отношения их производных (согласно правилу Лопиталя): \(\lim\limits_
\frac = \lim\limits_ \frac - \(\lim\limits_
\frac = \frac<0><0>или \frac <\infty><\infty>\); - \( f_n \) и \(g_n\) дифференцируемы;
- \( g’_n \ne 0 \) при \(n \to \infty\);
- \(\exists \lim\limits_
\frac
Допустим, требуется сравнить эффективность двух алгоритмов с оценками сложности \(\mathcal
(a^n)\) и \(\mathcal (n^b)\), где a и b — константы. Известно, что \((c^x)’ =c^x \cdot ln(c)\), но \((x^c)’ = c \cdot x^ \). Применим правило Лопиталя к пределу отношения наших функций b раз, получим: \(\lim\limits_ \frac <\mathcal (a^n)><\mathcal (n^b)> = \lim\limits_ \frac <\mathcal (a^n * ln^b (a))><\mathcal (b!)> = \infty\). Значит функция \(a^n\) имеет более высокую скорость роста. Без использования пределов и правила Лопиталя такой вывод может казаться не очевидным. Логарифмы и сложность алгоритмов. Пример
По определению \(\log_a
= b \Leftrightarrow x = a^b\). Необходимо знать, что \(x \to \infty \Rightarrow \log_a \to \infty\), однако, логарифм — это очень медленно растущая функция. Существует ряд формул, позволяющих упрощать выражения с логарифмами: - \(\log_a
= \log_a + \log_a< y>\); - \(\log_a
- \(\log_a
=\frac<\log_b ><\log_b>\).
При анализе алгоритмов обычно встречаются логарифмы по основанию 2, однако основание не играет большой роли, поэтому зачастую не указывается. Последняя формула позволяет заменить основание логарифма, домножив его на константу, но константы отбрасываются при асимптотическом анализе.
Логарифмической сложностью обладают алгоритмы, для которых не требуется обрабатывать все исходные данные, они используют принцип «разделяй и властвуй». На каждом шаге часть данных (обычно половина) отбрасывается. Примером может быть функция поиска элемента в отсортированном массиве (двоичного поиска):
Очевидно, что на каждом шаге алгоритма количество рассматриваемых элементов сокращается в 2 раза. Количество элементов, среди которых может находиться искомый, на k-том шаге определяется формулой \(\frac
<2^k>\). В худшем случае поиск будет продолжаться пока в массиве не останется один элемент, т.е. чтобы определить количество итераций для верхней оценки, достаточно решить уравнение \(1 = \frac <2^k>\Rightarrow 2^i = n \Rightarrow i = \log_2 n\). Следовательно, алгоритм имеет логарифмическую сложность: \(T^ _n = \mathcal (\log n)\). Результаты анализа. Замечания. Литература
Оценка сложности — замечательный способ не только сравнения алгоритмов, но и прогнозирования времени их работы. Никакие тесты производительности не дадут такой информации, т.к. зависят от особенностей конкретного компьютера и обрабатывают конкретные данные (не обязательно худший случай).
Анализ алгоритмов позволяет определить минимально возможную трудоемкость, например:
- алгоритм поиска элемента в неупорядоченном массиве не может иметь верхнюю оценку сложности лучше, чем \(\mathcal
(n)\). Это связано с тем, что невозможно определить отсутствие элемента в массиве (худший случай) не просмотрев все его элементы; - возможно формально доказать, что не возможен алгоритм сортировки произвольного массива, работающий лучше чем \(\mathcal
(n \cdot \log n)\) [5].
Нередко на собеседованиях просят разработать алгоритм с лучшей оценкой, чем возможно. Сами задачи при этом сводятся к какому-либо стандартному алгоритму. Человек, не знакомый с асимптотическим анализом начнет писать код, но требуется лишь обосновать невозможность существования такого алгоритма.
Введение в анализ сложности алгоритмов (часть 3)
От переводчика: данный текст даётся с незначительными сокращениями по причине местами излишней «разжёванности» материала. Автор абсолютно справедливо предупреждает, что отдельные темы могут показаться читателю чересчур простыми или общеизвестными. Тем не менее, лично мне этот текст помог упорядочить имеющиеся знания по анализу сложности алгоритмов. Надеюсь, что он окажется полезен и кому-то ещё.
Из-за большого объёма оригинальной статьи я разбила её на части, которых в общей сложности будет четыре.
Я (как всегда) буду крайне признательна за любые замечания в личку по улучшению качества перевода.Логарифмы

Если вы знаете, что такое логарифмы, то можете спокойно пропустить этот раздел. Глава предназначается тем, кто незнаком с данным понятием или пользуется им настолько редко, что уже забыл что там к чему. Логарифмы важны, поскольку они очень часто встречаются при анализе сложности. Логарифм — это операция, которая при применении её к числу делает его гораздо меньше (подобно взятию квадратного корня). Итак, первая вещь, которую вы должны запомнить: логарифм возвращает число, меньшее, чем оригинал. На рисунке справа зелёный график — линейная функция f(n) = n , красный — f(n) = sqrt(n) , а наименее быстро возрастающий — f(n) = log(n) . Далее: подобно тому, как взятие квадратного корня является операцией, обратной возведению в квадрат, логарифм — обратная операция возведению чего-либо в степень.Поясню на примере. Рассмотрим уравнение
Чтобы найти из него x , спросим себя: в какую степень надо возвести 2, чтобы получить 1024? Ответ: в десятую. В самом деле, 2 10 = 1024 , что легко проверить. Логарифмы помогают нам описать данную задачу, используя новую нотацию. В данном случае, 10 является логарифмом 1024 и записывается, как log( 1024 ). Читается: «логарифм 1024». Поскольку мы использовали 2 в качестве основания, то такие логарифмы называются «по основанию 2». Основанием может быть любое число, но в этой статье мы будем использовать только двойку. Если вы ученик-олимпиадник и не знакомы с логарифмами, то я рекомендую вам попрактиковаться после того, как закончите чтение этой статьи. В информатике логарифмы по основанию 2 распространены больше, чем какие-либо другие, поскольку часто мы имеем всего две сущности: 0 и 1. Также существует тенденция разбивать объёмные задачи пополам, а половин, как известно, тоже бывает всего две. Поэтому для дальнейшего чтения статьи вам достаточно иметь представление только о логарифмах по основанию 2.
- 2 x = 64
- (2 2 ) x = 64
- 4 x = 4
- 2 x = 1
- 2 x + 2 x = 32
- (2 x) * (2 x ) = 64
- Методом проб и ошибок, находим, что x = 6 . Таким образом, log( 64 ) = 6
- По свойству степеней (2 2 ) x можно записать как 2 2 x . Таким образом, получим, что 2x = 6 (потому что log( 64 ) = 6 из предыдущего примера) и, следовательно, x = 3
- Используя знания, полученные при решении предыдущего примера, запишем 4 как 2 2 . Тогда наше уравнение превратится в (2 2 ) x = 4, что эквивалентно 2 2 x . Заметим, что log( 4 ) = 2 (поскольку 2 2 = 4), так что мы получаем 2x = 2 , откуда x = 1 . Это легко заметить по исходному уравнению, поскольку степень 1 даёт основание в качестве результата
- Вспомнив, что степень 0 даёт результатом 1 (т.е. log( 1 ) = 0 ), получим x = 0
- Здесь мы имеем дело с суммой, поэтому непосредственно взять логарифм не получится. Однако, мы замечаем, что 2 x + 2 x — это тоже самое, что и 2 * (2 x ) . Умножение на 2 даст 2 x + 1 , и мы получим уравнение 2 x + 1 = 32 . Находим, что log( 32 ) = 5 , откуда x + 1 = 5 и x = 4 .
- Мы перемножаем две степени двойки, следовательно, можем объединить их в 2 2x . Остаётся просто решить уравнение 2 2x = 64 , что мы уже делали выше. Ответ: x = 3
Практическая рекомендация: на соревнованиях алгоритмы часто реализуются на С++. Как только вы проанализировали сложность вашего алгоритма, так сразу можете получить и грубую оценку того, как быстро он будет работать, приняв, что в секунду выполняется 1 000 000 команд. Их количество считается из полученной вами функции асимптотической оценки, описывающей алгоритм. Например, вычисление по алгоритму с Θ( n ) займёт около секунды при n = 1 000 000.
Рекурсивная сложность
А теперь давайте обратимся к рекурсивным функциям. Рекурсивная функция — это функция, которая вызывает сама себя. Можем ли мы проанализировать её сложность? Следующая функция, написанная на Python, вычисляет факториал заданного числа. Факториал целого положительного числа находится как произведение всех предыдущих положительных целых чисел. Например, факториал 5 — это 5 * 4 * 3 * 2 * 1 . Обозначается он как «5!» и произносится «факториал пяти» (впрочем, некоторые предпочитают «ПЯТЬ. 11»).
Давайте проанализируем эту функцию. Она не содержит циклов, но её сложность всё равно не является константной. Что ж, придётся вновь заняться подсчётом инструкций. Очевидно, что если мы применим эту функцию к некоторому n , то она будет вычисляться n раз. (Если вы в этом не уверены, то можете вручную расписать ход вычисления при n = 5 , чтобы определить, как это на самом деле работает.) Таким образом, мы видим, что эта функция является Θ( n ) .
Если вы всё же не уверены в этом, то вы всегда можете найти точную сложность путём подсчёта количества инструкций. Примените этот метод к данной функции, чтобы найти её f( n ), и убедитесь, что она линейная (напомню, что линейность означает Θ( n ) ).
Логарифмическая сложность
Одной из известнейших задач в информатике является поиск значения в массиве. Мы уже решали её ранее для общего случая. Задача становится интереснее, если у нас есть отсортированный массив, в котором мы хотим найти заданное значение. Одним из способов сделать это является бинарный поиск. Мы берём средний элемент из нашего массива: если он совпадает с тем, что мы искали, то задача решена. В противном случае, если заданное значение больше этого элемента, то мы знаем, что оно должно лежать в правой части массива. А если меньше — то в левой. Мы будем разбивать эти подмассивы до тех пор, пока не получим искомое.
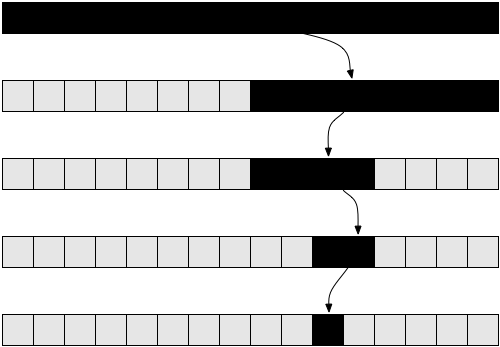
Вот реализация такого метода в псевдокоде:Приведённый псевдокод — упрощение настоящей реализации. На практике этот метод описать проще, чем воплотить, поскольку программисту нужно решить некоторые дополнительные вопросы. Например, защиту от ошибок на одну позицию (off-by-one error, OBOE), да и деление на два не всегда может давать целое число, поэтому потребуется применять функции floor() или ceil() . Однако, предположим, что в нашем случае деление всегда будет успешным, наш код защищён от ошибок off-by-one, и всё, что мы хотим — это проанализировать сложность данного метода. Если вы никогда раньше не реализовывали бинарный поиск, то можете сделать это на вашем любимом языке программирования. Такая задача по-настоящему поучительна.
Если вы не уверены, что метод работает в принципе, то отвлекитесь и решите вручную какой-нибудь простой пример.
Теперь давайте попробуем проанализировать этот алгоритм. Ещё раз, в этом случае мы имеем рекурсивный алгоритм. Давайте для простоты предположим, что массив всегда разбивается ровно пополам, игнорируя +1 и -1 части в рекурсивном вызове. К этому моменту вы должны быть уверены, что такое небольшое изменение, как игнорирование +1 и -1, не повлияет на конечный результат оценки сложности. В принципе, обычно этот факт необходимо доказывать, если мы хотим проявить осторожность с математической точки зрения. Но на практике это очевидно на уровне интуиции. Также для простоты давайте предположим, что наш массив имеет размер одной из степеней двойки. Опять-таки, это предположение никоим образом не повлияет на конечный результат расчёта сложности алгоритма. Наихудшим сценарием для данной задачи будет вариант, когда массив в принципе не содержит искомое значение. В этом случае мы начинаем с массива размером n на первом рекурсивном вызове, n / 2 на втором, n / 4 на третьем и так далее. В общем, наш массив разбивается пополам на каждом вызове до тех пор, пока мы не достигнем единицы. Давайте запишем количество элементов в массиве на каждом вызове:
0-я итерация: n
1-я итерация: n / 2
2-я итерация: n / 4
3-я итерация: n / 8
…
i-я итерация: n / 2 i
…
последняя итерация: 1Заметьте, что на i-й итерации массив имеет n / 2 i элементов. Мы каждый раз разбиваем его пополам, что подразумевает деление количества элементов на два (равноценно умножению знаменателя на два). Проделав это i раз, получим n / 2 i . Процесс будет продолжаться, и из каждого большого i мы будем получать меньшее количество элементов до тех пор, пока не достигнем единицы. Если мы захотим узнать, на какой итерации это произошло, нам нужно будет просто решить следующее уравнение:
Равенство будет истинным только тогда, когда мы достигнем конечного вызова функции binarySearch() , так что узнав из него i , мы будем знать номер последней рекурсивной итерации. Умножив обе части на 2 i , получим:
Если вы прочли раздел о логарифмах выше, то такое выражение будет для вас знакомым. Решив его, мы получим:
Этот ответ говорит нам, что количество итераций, необходимых для бинарного поиска, равняется log( n ) , где n — размер оригинального массива.
Если немного подумать, то это имеет смысл. Например, возьмём n = 32 (массив из 32-х элементов). Сколько раз нам потребуется разделить его, чтобы получить один элемент? Считаем: 32 → 16 → 8 → 4 → 2 → 1 — итого 5 раз, что является логарифмом 32. Таким образом, сложность бинарного поиска равна Θ( log( n ) ) .
Последний результат позволяет нам сравнивать бинарный поиск с линейным (нашим предыдущим методом). Несомненно, log( n ) намного меньше n , из чего правомерно заключить, что первый намного быстрее второго. Так что имеет смысл хранить массивы в отсортированном виде, если мы собираемся часто искать в них значения.
Практическая рекомендация: улучшение асимптотического времени выполнения программы часто чрезвычайно повышает её производительность. Намного сильнее, чем небольшая «техническая» оптимизация в виде использования более быстрого языка программирования.