§ 43. Деревья
Как вы знаете из учебника 10 класса, дерево — это структура, отражающая иерархию (отношения подчинённости, многоуровневые связи). Напомним некоторые основные понятия, связанные с деревьями.
Дерево состоит из узлов и связей между ними (они называются дугами). Самый первый узел, расположенный на верхнем уровне (в него не входит ни одна стрелка-дуга), — это корень дерева. Конечные узлы, из которых не выходит ни одна дуга, называются листьями. Все остальные узлы, кроме корня и листьев, — это промежуточные узлы.
Из двух связанных узлов тот, который находится на более высоком уровне, называется родителем, а другой — сыном. Корень — это единственный узел, у которого нет родителя; у листьев нет сыновей.
Используются также понятия «предок» и «потомок». Потомок какого-то узла — это узел, в который можно перейти пострелкам от узла-предка. Соответственно, предок какого-то узла — это узел, из которого можно перейти по стрелкам в данный узел.
В дереве на рис. 6.11 родитель узла Е — это узел В, а предки узла Е — это узлы А и В, для которых узел Е — по томок. Потомками узла А (корня дерева) являются все остальные узлы.
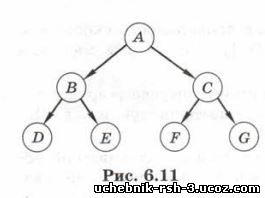 Высота дерева — это наибольшее расстояние (количество дуг) от корня до листа. Высота дерева, приведённого на рис. 6.11, равна 2.
Высота дерева — это наибольшее расстояние (количество дуг) от корня до листа. Высота дерева, приведённого на рис. 6.11, равна 2.
Формально дерево можно определить следующим образом:
- пустая структура — это дерево;
- дерево — это корень и несколько связанных с ним отдельных
(не связанных между собой) деревьев.
Чаще всего в информатике используются двоичные (или бинарные) деревья, т. е. такие, в которых каждый узел имеет не более двух сыновей. Их также можно определить рекурсивно.
Деревья широко применяются в следующих задачах:
- поиск в большом массиве не меняющихся данных;
- сортировка данных;
- вычисление арифметических выражений;
- оптимальное кодирование данных (метод сжатия Хаффмана).
Известно, что для того, чтобы найти заданный элемент в неупорядоченном массиве из N элементов, может понадобиться N сравнений. Теперь предположим, что элементы массива организованы в виде специальным образом построенного дерева, например как показано на рис. 6.12.
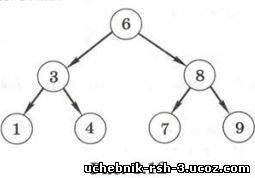
Значения, связанные с узлами дерева, по которым выполняется поиск, называются ключами этих узлов (кроме ключа узел может содержать множество других данных). Перечислим важные свойства дерева, показанного на рис. 6.12:
- слева от каждого узла находятся узлы, ключи которых
меньше или равны ключу данного узла; - справа от каждого узла находятся узлы, ключи которых
больше или равны ключу данного узла.
Дерево, обладающее такими свойствами, называется двоичным деревом поиска.
Например, пусть нужно найти узел, ключ которого равен 4. Начинаем поиск по дереву с корня. Ключ корня — 6 (больше заданного), поэтому дальше нужно искать только в левом поддереве и т. д. Если при линейном поиске в массиве за одно сравнение отсекается 1 элемент, здесь — сразу примерно половина оставшихся. Количество операций сравнения в этом случае пропорционально \og2N, т. е. алгоритм имеет асимптотическую сложность O(logaJV). Конечно, нужно учитывать, что предварительно дерево должно быть построено. Поэтому такой алгоритм выгодно применять в тех случаях, когда данные меняются редко, а поиск выполняется часто (например, в базах данных).
Обход двоичного дерева
Обойти дерево — это значит "посетить" все узлы по одному разу. Если перечислить узлы в порядке их посещения, мы представим данные в виде списка.
Существуют несколько способов обхода дерева:
• КЛП — «корень — левый — правый» (обход в прямом порядке):
посетить корень обойти левое поддерево обойти правое поддерево
• ЛКП — «левый — корень — правый» (симметричный обход):
обойти левое поддерево
обойти правое поддерево
• ЛПК — «левый — правый — корень» (обход в обратном по
рядке):
обойти левое поддерево обойти правое поддерево посетить корень
Как видим, это рекурсивные алгоритмы. Они должны заканчиваться без повторного вызова, когда текущий корень — пустое дерево.
Рассмотрим дерево, которое может быть составлено для вычисления арифметического выражения (1 + 4) * (9 — 5) (рис. 6.13).
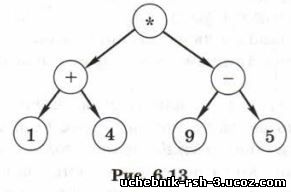
Выражение вычисляется по такому дереву снизу вверх, т. е. посещение корня дерева — это последняя выполняемая операция.
Различные типы обхода дают последовательность узлов:
В первом случае мы получили префиксную форму записи арифметического выражения, во втором — привычную нам инфиксную форму (только без скобок), а в третьем — постфиксную форму. Напомним, что в префиксной и в постфиксной формах скобки не нужны.
Обход КЛП называется «обходом в глубину», потому что сначала мы идём вглубь дерева по левым поддеревьям, пока не дойдём до листа. Такой обход можно выполнить с помощью стека следующим образом:
записать в стек корень дерева
нц пока стек не пуст
выбрать узел V с вершины стека
посетить узел V
если у узла V есть правый сын то
добавить в стек правого сына V
все
если у узла V есть левый сын то
добавить в стек левого сына V
все
кц
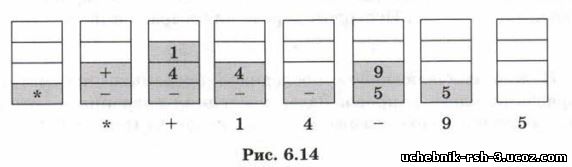
На рисунке 6.14 показано изменение состояния стека при таком обходе дерева, изображенного на рис. 6.13. Под стеком записана метка узла, который посещается (например, данные из этого узла выводятся на экран).
Существует ещё один способ обхода, который называют обходом в ширину. Сначала посещают корень дерева, затем — всех его сыновей, затем — сыновей сыновей («внуков») и т. д., постепенно спускаясь на один уровень вниз. Обход в ширину для приведённого выше дерева даст такую последовательность посещения узлов:
Для того чтобы выполнить такой обход, применяют очередь. В очередь записывают узлы, которые необходимо посетить. На псевдокоде обход в ширину можно записать так:
записать в очередь корень дерева нц пока очередь не пуста
выбрать первый узел V из очереди
посетить узел V
если у узла V есть левый сын то добавить в очередь левого сына V
все
если у узла V есть правый сын то добавить в очередь правого сына V
все
кц
Вычисление арифметических выражений
Один из способов вычисления арифметических выражений основан на использовании дерева. Сначала выражение, записанное в линейном виде (в одну строку), нужно «разобрать» и построить соответствующее ему дерево. Затем в результате прохода по этому дереву от листьев к корню вычисляется результат.
Для простоты будем рассматривать только арифметические выражения, содержащие числа и знаки четырёх арифметических операций: + — * /. Построим дерево для выражения
Нужно сначала найти последнюю операцию, просматривая выражение слева направо. Здесь последняя операция — это второе вычитание, оно оказывается в корне дерева (рис. 6.15).
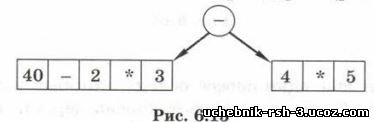
Как выполнить этот поиск в программе? Известно, что операции выполняются в порядке приоритета (старшинства): сначала операции с более высоким приоритетом (слева направо), потом — с более низким (также слева направо). Отсюда следует важный вывод.
В корень дерева нужно поместить поспеднюю из операций с наименьшим приоритетом.
Теперь нужно построить таким же способом лез поддеревья (рис. 6.16).
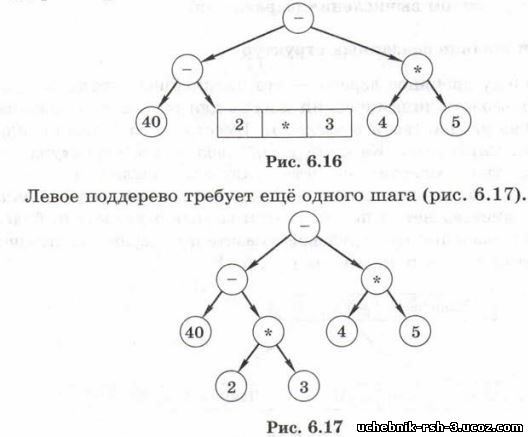
Эта процедура рекурсивная, её можно записать в виде псевдокода:
найти последнюю выполняемую операцию
если операций нет то
все
поместить найденную операцию в корень дерева
построить левое поддерево
построить правое поддерево
Рекурсия заканчивается, когда в оставшейся части строки нет ни одной операции, значит, там находится число (это лист дерева).
Теперь вычислим выражение по дереву. Если в корне находится знак операции, её нужно применить к результатам вычисления поддеревьев:
nl:=значение левого поддерева
п2:=значение правого поддерева
Снова получился рекурсивный алгоритм.
Возможен особый случай (на нём заканчивается рекурсия), когда корень дерева содержит число (т. е. это лист). Это число и будет результатом вычисления выражения.
Использование связанных структур
Поскольку двоичное дерево — это нелинейная структура данных, использовать динамический массив для размещения элементов не очень удобно (хотя возможно). Вместо этого будем использовать связанные узлы. Каждый такой узел — это структура, содержащая три области: область данных, ссылка на левое поддерево (указатель) и ссылка на правое поддерево (второй указатель). У листьев нет сыновей, в этом случае в указатели будем записывать значение nil (нулевой указатель). Дерево, состоящее из трёх таких узлов, показано на рис. 6.18.
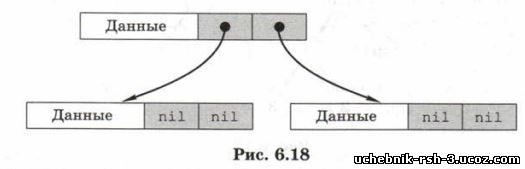
В данном случае область данных узла будет содержать одно поле — символьную строку, в которую записывается знак операции или число в символьном виде.
Введём два новых типа: TNode — узел дерева, и PNode — указатель (ссылку) на такой узел:
type
PNode = "TNode;
left, right: PNode
end;
Самый важный момент — выделение памяти под новую структуру. Предположим, что р — это переменная-указатель типа PNode. Для того чтобы выделить память под новую структуру и записать адрес выделенного блока в р, используется процедура
Как программа определяет, сколько памяти нужно выделить? Чтобы ответить на этот вопрос, вспомним, что указатель р указы-вает на структуру типа TNode, размер которой и определяет раз-мер выделяемого блока памяти.
Для освобождения памяти служит процедура Dispose (англ. dispose — ликвидировать):
Dispose(p);
В основной программе объявим одну переменную типа PNode — это будет ссылка на корень дерева:
var T: PNode;
Вычисление выражения сводится к двум вызовам функций:
T:=Tree(s);
writeIn('Результат: ', Calc (Т) ) ;
Здесь предполагается, что арифметическое выражение записано в символьной строке s, функция Tree строит в памяти дерево по этой строке, а функция Calc — вычисляет значение выражения по готовому дереву.
При построении дерева нужно выделять в памяти новый узел и искать последнюю выполняемую операцию — это будет делать функция LastOp. Она возвращает О, если ни одной операции не обнаружено, в этом случае создаётся лист — узел без потомков. Если операция найдена, её обозначение записывается в поле data, а в указатели записываются адреса поддеревьев, которые строятся рекурсивно для левой и правой частей выражения:
function Tree(s: string): PNode;
var k: integer;
New(Tree); (выделить память>
if k=0 then begin
end
else begin
Тгее Л .right:=Tree(Copy(s,k+1,Length(s)-k))
end
end;
Функция Calc тоже будет рекурсивной:
function Calc(Tree: PNode) : integer,
var nl, n2, res: integer;
begin
if Tree-4, left = nil then
Val(Tree".data, Calc, res) else begin
nl:=Calc(ТгееЛ.left);
case Tree^.data[1] of
else Calc:=MaxInt end
end;
Если ссылка, переданная функции, указывает на лист (нет левого поддерева), то значение выражения — это результат преобразова-ния числа из символьной формы в числовую (с помощью процеду¬ры Val). В противном случае вычисляются значения для левого и правого поддеревьев и к ним применяется операция, указанная в корне дерева. В случае ошибки (неизвестной операции) функ¬ция возвращает значение Maxlnt — максимальное целое число.
Осталось написать функцию LastOp, Нужно найти в символь-ной строке последнюю операцию с минимальным приоритетом. Для этого составим функцию, возвращающую приоритет опера¬ции (переданного ей символа):
function Priority(op: char): integer;
begin
case op of
'+','-': Priority:=1;
'*','/': Priority:=2;
else Priority:=100
end
end;
Сложение и вычитание имеют приоритет 1, умножение и деле¬ние — приоритет 2, а все остальные символы (не операции) — приоритет 100 (условное значение).
Функция LastOp может выглядеть так:
function LastOp(s: string): integer;
var 1, minPrt: integer;
for i:=l to Length(s) do
if Priority(s[i])<=minPrt then begin
end
end;
Обратите внимание, что в условном операторе указано нестрогое неравенство, чтобы найти именно последнюю операцию с наименьшим приоритетом. Начальное значение переменной minPrt можно выбрать любое между наибольшим приоритетом операций (2) и условным кодом не-операции (100). Тогда если найдена любая операция, условный оператор срабатывает, а если в строке нет операций, условие всегда ложно и в переменной LastOp остается начальное значение 0.
Хранение двоичного дерева в массиве
Двоичные деревья можно хранить в (динамическом) массиве почти так же, как и списки. Вопрос о том, как сохранить структуру (взаимосвязь узлов), решается следующим образом. Если нумерация элементов массива А начинается с 1, то сыновья элемента A[i] — это A[Z*i] и AJS4+1>. На рисунке 6.19 показан порядок расположения элементов в массиве для дерева, соответствующего выражению
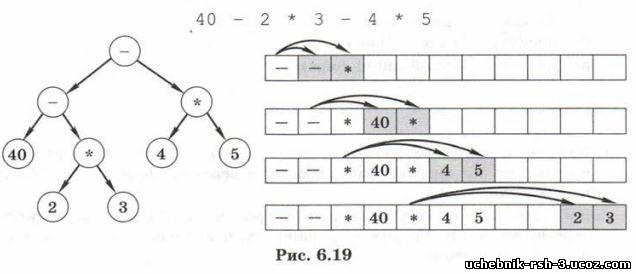
Алгоритм вычисления выражения остаётся прежним, изменяется только метод хранения данных. Обратите внимание, что некоторые элементы остались пустыми, это значит, что их родитель — лист дерева.
Терминология и определения¶
После того, как мы рассмотрели примеры деревьев, дадим формальные определения им и их компонентам.
Узел Узел — это основная часть дерева. Он может иметь название, которое мы будем называть “ключом”. Также узел может содержать дополнительную информацию, которую мы будем называть “полезной нагрузкой”. Хотя во многих алгоритмах для деревьев ей не уделяется достаточно внимания, для приложений, использующих эту структуру данных, она часто оказывается критичным фактором. Ветвь Ветвь — другая фундаментальная часть дерева. Оно соединяет два узла вместе, показывая наличие между ними определённых отношений. Каждый узел (кроме корня) имеет ровно одну входящую ветвь. При этом он может иметь несколько исходящих ветвей. Корень Корень дерева — единственный узел, не имеющий входящих ветвей. На рисунке 2 / — корень дерева. Путь Путь — это упорядоченный список узлов, соединённых ветвями. Например, Mammal \(\rightarrow\) Carnivora \(\rightarrow\) Felidae \(\rightarrow\) Felis \(\rightarrow\) Domestica — это путь. Дети (потомки) Набор узлов \(c\) , имеющих входящие ветви от одного узла, называются его детьми. На рисунке 2 узлы log/, spool/ и yp/ — потомки узла var/. Родитель (предок) Узел является родителем всех узлов, с которыми связан исходящими ветвями. На рисунке 2 узел var/ является родителем узлов log/, spool/ и yp/. Братья Узлы дерева, являющиеся детьми одного родителя, называют братьями. Примером могут послужить etc/ и usr/ в дереве файловой системы. Поддерево Поддерево — это набор узлов и ветвей, состоящий родителя и всех его потомков. Лист Лист — это узел, у которого нет детей. Например, Human и Chimpanzee — листья на рисунке 1. Уровень Уровень узла \(n\) — это число ветвей в пути от корня до \(n\) . Например, уровень Felis на рисунке 1 равен пяти. По определению, уровень корня — нулевой. Высота Высота дерева равна максимальному уровню любого его узла. Например, высота дерева на рисунке 2 равна двум.
А теперь, определившись с основной терминологией, дадим дереву формальное определение. Фактически, мы дадим две формулировки: первая будет включать узлы и ветви, а вторая (чью полезность мы докажем на практике) будет рекурсивной.
Определение 1: Дерево состоит из набора узлов и набора ветвей, соединяющих пары узлов. Оно имеет следующие свойства:
- Один из узлов дерева определён, как его корень.
- Каждый узел \(n\) (кроме корневого) соединяется ветвью с единственным другим узлом \(p\) , где \(p\) — родитель \(n\) .
- Каждый узел соединён с корнем единственно возможным путём.
- Если каждый из узлов дерева имеет максимум двух потомков, то такая структура называется двоичным деревом.
На рисунке 3 изображено дерево, удовлетворяющее определению 1. Стрелки на ветвях показывают направление связи.
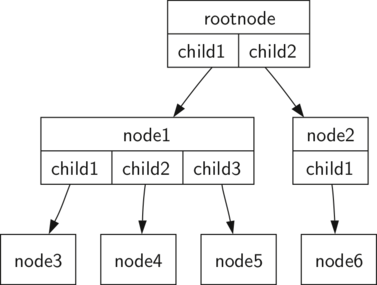
Рисунок 3: Дерево, содержащее набор узлов и ветвей.
Определение 2: Дерево либо пусто, либо содержит корень и нуль или более поддеревьев, каждое из которых тоже является деревом. Корень каждого поддерева соединён ветвью с родительским деревом.
Рисунок 4 иллюстрирует это определение. Используя его, можно сказать, что изображённая структура имеет как минимум четыре узла, поскольку каждый из треугольников, представляющих поддеревья, должен иметь корень. В этом дереве может быть намного больше узлов, но сказать точнее нельзя до тех пор, пока мы не продвинемся по нему глубже.
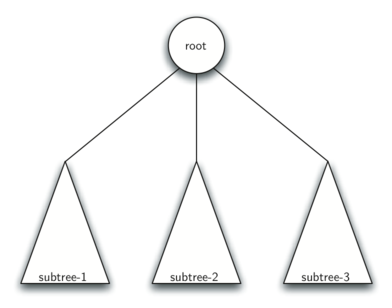
Рисунок 4: Рекурсивное определение дерева
readers online now | | Back to top
© Copyright 2014 Brad Miller, David Ranum. Created using Sphinx 1.2.3.
Структура данных B-дерево
Всем привет! Мы запустили новый набор на курс «Алгоритмы для разработчиков» и сегодня хотим поделиться интересным переводом, подготовленным для студентов данного курса.

В деревьях поиска, таких как двоичное дерево поиска, AVL дерево, красно-чёрное дерево и т.п. каждый узел содержит только одно значение (ключ) и максимум двое потомков. Однако есть особый тип дерева поиска, который называется B-дерево (произносится как Би-дерево). В нем узел содержит более одного значения (ключа) и более двух потомков. B-дерево было разработано в 1972 году Байером и МакКрейтом и называлось Сбалансированное по высоте дерево поиска порядка m (Height Balanced m-way Search Tree). Свое современное название B-дерево получило позже.
B-дерево можно определить следующим образом:
B-дерево – это сбалансированное дерево поиска, в котором каждый узел содержит множество ключей и имеет более двух потомков.
Здесь количество ключей в узле и количество его потомков зависит от порядка B-дерева. Каждое B-дерево имеет порядок.
B-дерево порядка m обладает следующими свойствами:
Свойство 1: Глубина всех листьев одинакова.
Свойство 2: Все узлы, кроме корня должны иметь как минимум (m/2) – 1 ключей и максимум m-1 ключей.
Свойство 3: Все узлы без листьев, кроме корня (т.е. все внутренние узлы), должны иметь минимум m/2 потомков.
Свойство 4: Если корень – это узел не содержащий листьев, он должен иметь минимум 2 потомка.
Свойство 5:Узел без листьев с n-1 ключами должен иметь n потомков.
Свойство 6: Все ключи в узле должны располагаться в порядке возрастания их значений.
Например, B-дерево 4 порядка содержит максимум 3 значения ключа и максимум 4 потомка для каждого узла.
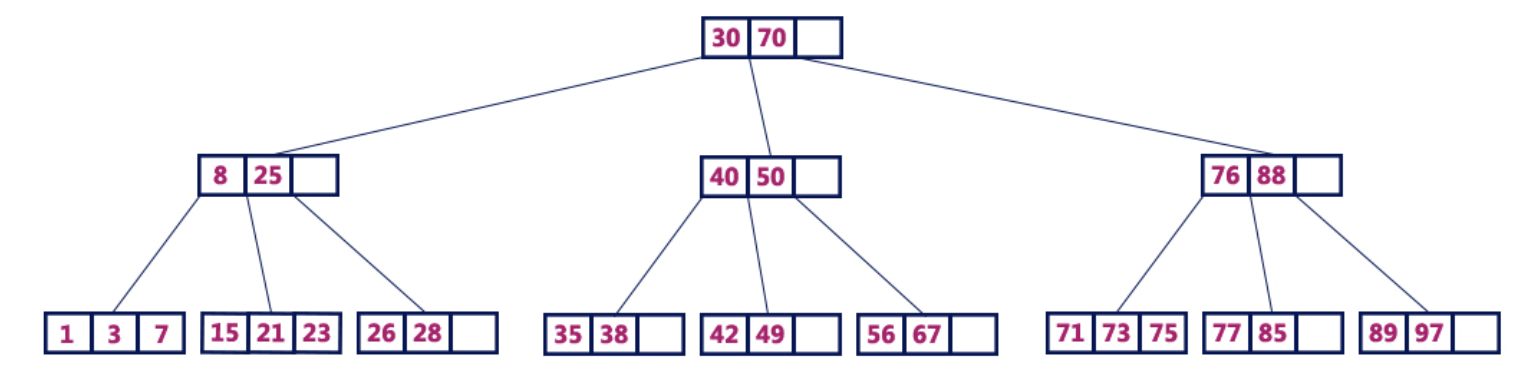
B-дерево 4 порядка
Операции над B-деревом
- Поиск
- Вставка
- Удаление
Поиск по B-дереву
Поиск по B-дереву аналогичен поиску по двоичному дереву поиска. В двоичном дереве поиска поиск начинается с корня и каждый раз принимается двустороннее решение (пойти по левому поддереву или по правому). В В-дереве поиск также начинается с корневого узла, но на каждом шаге принимается n-стороннее решение, где n – это общее количество потомков рассматриваемого узла. В В-дереве сложность поиска составляет O(log n). Поиск происходит следующим образом:
Шаг 1: Считать элемент для поиска.
Шаг 2: Сравнить искомый элемент с первым значением ключа в корневом узле дерева.
Шаг 3: Если они совпадают, вывести: «Искомый узел найден!» и завершить поиск.
Шаг 4: Если они не совпадают, проверить больше или меньше значение элемента, чем текущее значение ключа.
Шаг 5: Если искомый элемент меньше, продолжить поиск по левому поддереву.
Шаг 6: Если искомый элемент больше, сравнить элемент со следующим значением ключа в узле и повторять Шаги 3, 4, 5 и 6 пока не будет найдено совпадение или пока искомый элемент не будет сравнен с последним значением ключа в узле-листе.
Шаг 7: Если последнее значение ключа в узле-листе не совпало с искомым, вывести «Элемент не найден!» и завершить поиск.
Операция вставки в B-дерево
В В-дереве новый элемент может быть добавлен только в узел-лист. Это значит, что новая пара ключ-значение всегда добавляется только к узлу-листу. Вставка происходит следующим образом:
Шаг 1: Проверить пустое ли дерево.
Шаг 2: Если дерево пустое, создать новый узел с новым значением ключа и его принять за корневой узел.
Шаг 3: Если дерево не пустое, найти подходящий узел-лист, к которому будет добавлено новое значение, используя логику дерева двоичного поиска.
Шаг 4: Если в текущем узле-листе есть незанятая ячейка, добавить новый ключ-значение к текущему узлу-листу, следуя возрастающему порядку значений ключей внутри узла.
Шаг 5: Если текущий узел полон и не имеет свободных ячеек, разделите узел-лист, отправив среднее значение родительскому узлу. Повторяйте шаг, пока отправляемое значение не будет зафиксировано в узле.
Шаг 6: Если разделение происходит с корнем дерева, тогда среднее значение становится новым корнем дерева и высота дерева увеличивается на единицу.
Давайте создадим B-дерево порядка 3, добавляя в него числа от 1 до 10.
Insert(1):
Поскольку «1» — это первый элемент дерева – он вставляется в новый узел и этот узел становится корнем дерева.

Insert(2):
Элемент «2» добавляется к существующему узлу-листу. Сейчас у нас всего один узел, следовательно он является и корнем и листом одновременно. В этом листе имеется пустая ячейка. Тогда «2» встает в эту пустую ячейку.

Insert(3):
Элемент «3» добавляется к существующему узлу-листу. Сейчас у нас только один узел, который одновременно является и корнем и листом. У этого листа нет пустой ячейки. Поэтому мы разделяем этот узел, отправляя среднее значение (2) в родительский узел. Однако у текущего узла родительского узла нет. Поэтому среднее значение становится корневым узлом дерева.

Insert(4):
Элемент «4» больше корневого узла со значением «2», при этом корневой узел не является листом. Поэтому мы двигаемся по правому поддереву от «2». Мы приходим к узлу-листу со значением «3», у которого имеется пустая ячейка. Таким образом, мы можем вставить элемент «4» в эту пустую ячейку.
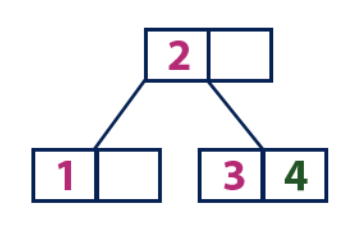
Insert(5):
Элемент «5» больше корневого узла со значением «2», при этом корневой узел не является листом. Поэтому мы двигаемся по правому поддереву от «2». Мы приходим к узлу-листу и обнаруживаем, что он уже полон и не имеет пустых ячеек. Тогда мы делим этот узел, отправляя среднее значение (4) в родительский узел (2). В родительском узле есть для него пустая ячейка, поэтому значение «4» добавляется к узлу, в котором уже есть значение «2», а новый элемент «5» добавляется в качестве нового листа.
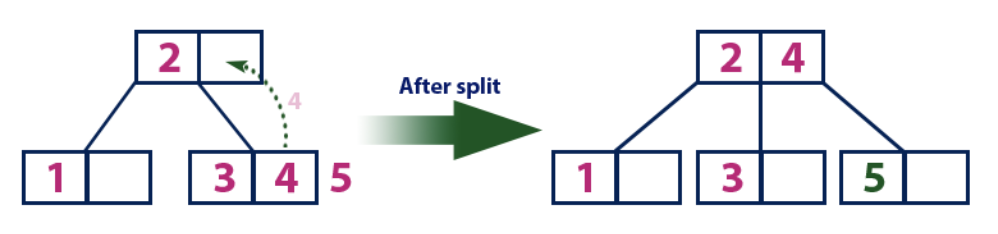
Insert(6):
Элемент «6» больше, чем элементы корня «2» и «4», который не является листом. Мы двигаемся по правому поддереву от элемента «4». Мы достигаем листа со значением «5», у которого есть пустая ячейка, поэтому элемент «6» помещаем как раз в нее.
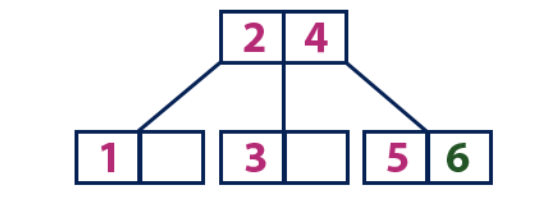
Insert(7):
Элемент «7» больше, чем элементы корня «2» и «4», который не является листом. Мы двигаемся по правому поддереву от элемента «4». Мы достигаем узла-листа и видим, что он полон. Мы делим этот узел, отправляя среднее значение «6» вверх к родительскому узлу с элементами «2» и «4». Однако родительский узел тоже полон, поэтому мы делим узел с элементами «2» и «4», отправляя значение «4» родительскому узлу. Только вот этого узла еще нет. В таком случае узел с элементом «4» становится новым корнем дерева.
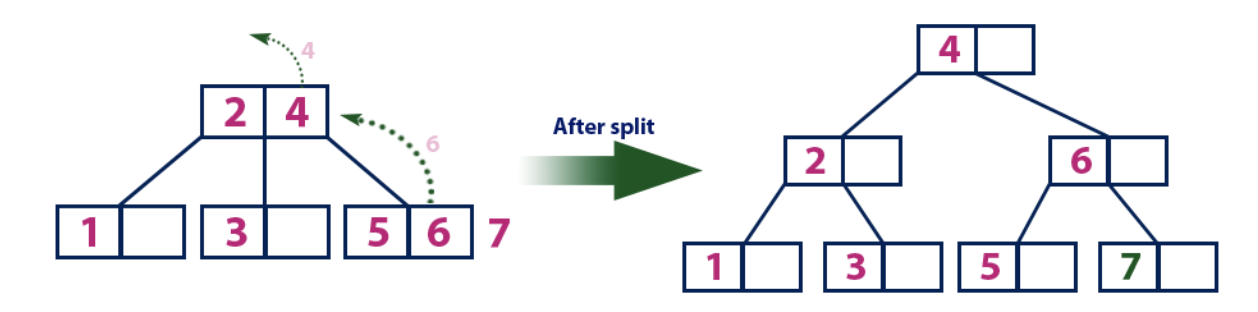
Insert(8):
Элемент «8» больше корневого узла со значением «4», при этом корневой узел не является листом. Мы двигаемся по правому поддереву от элемента «4» и приходим к узлу со значением «6». «8» больше «6» и узел с элементом «6» не является листом, поэтому двигаемся по правому поддереву от «6». Мы достигаем узла-листа с «7», у которого есть пустая ячейка, поэтому в нее мы помещаем «8».
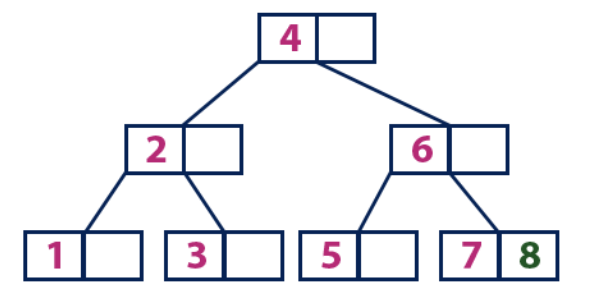
Insert(9):
Элемент «9» больше корневого узла со значением «4», при этом корневой узел не является листом. Мы двигаемся по правому поддереву от элемента «4» и приходим к узлу со значением «6». «9» больше «6» и узел с элементом «6» не является листом, поэтому двигаемся по правому поддереву от «6». Мы достигаем узла-листа со значениями «7» и «8». Он полон. Мы делим этот узел, отправляя среднее значение (8) родительскому узлу. Родительский узел «6» имеет пустую ячейку, поэтому мы помещаем «8» в нее. При этом новый элемент «9» добавляется в узел-лист.
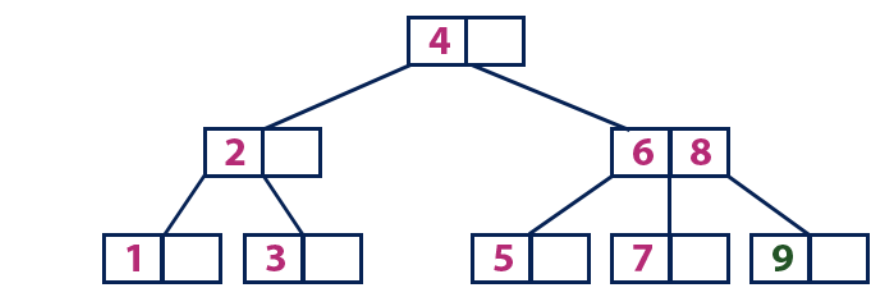
Insert(10):
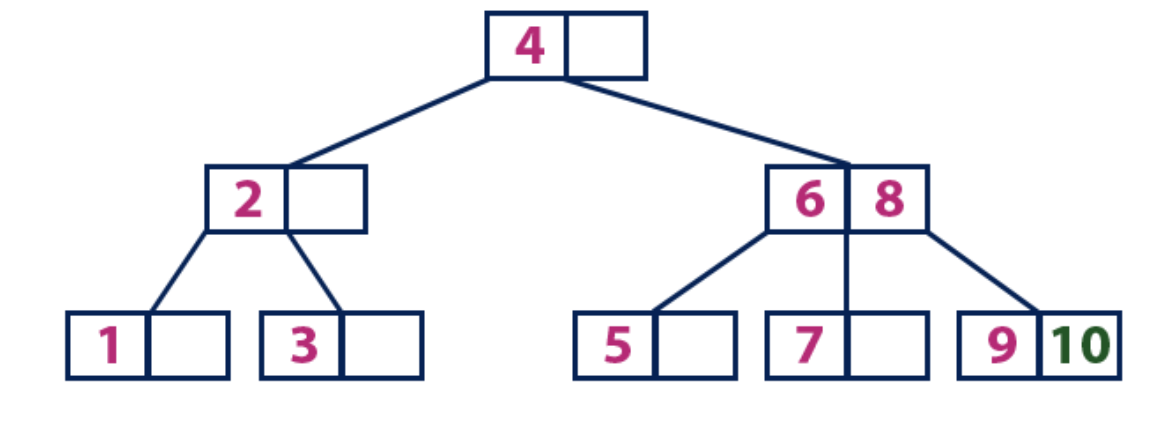
Элемент «10» больше корневого узла со значением «4», при этом корневой узел не является листом. Мы двигаемся по правому поддереву от элемента «4» и приходим к узлу со значениями «6» и «8». «10» больше «6» и «8» и узел с этими элементами не является листом, поэтому двигаемся по правому поддереву от «8». Мы достигаем узла-листа со значением «9». У него есть пустая ячейка, поэтому туда мы помещаем «10».
Предлагаем вам самостоятельно на практике понять, как устроены В-деревья, воспользовавшись этой визуализацией.
Ждем всех на бесплатном открытом уроке, который пройдет уже 12 июля. До встречи!
Дерево как структура данных

Какую выгоду можно извлечь из такой структуры данных, как дерево? В этой статье мы расскажем о данных в виде дерева, рассмотрим основные определения, которые следует знать, а также узнаем, как и зачем используется дерево в программировании. Спойлер: бинарные деревья часто применяют для поиска информации в базах данных, для сортировки данных, для проведения вычислений, для кодирования и в других случаях. Но давайте обо всем по порядку.
Основные термины
Дерево — это, по сути, один из частных случаев графа. Древовидная модель может быть весьма эффективна в случае представления динамических данных, особенно тогда, когда у разработчика стоит цель быстрого поиска информации, в тех же базах данных, к примеру. Еще древом называют структуру данных, которая представляет собой совокупность элементов, а также отношений между этими элементами, что вместе образует иерархическую древовидную структуру.
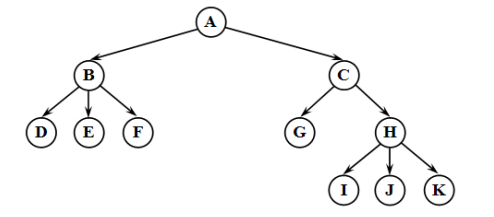
Каждый элемент — это вершина или узел дерева. Узлы, соединенные направленными дугами, называются ветвями. Начальный узел — это корень дерева (корневой узел). Листья — это узлы, в которые входит 1 ветвь, причем не выходит ни одной.
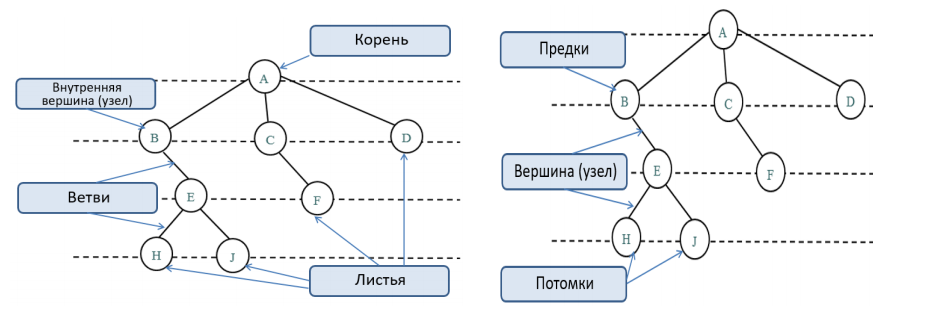
Общую терминологию можно посмотреть на левой и правой части картинки ниже:
Какие свойства есть у каждого древа:
— существует узел, в который не входит ни одна ветвь;
— в каждый узел, кроме корневого узла, входит 1 ветвь.
На практике деревья нередко применяют, изображая различные иерархии. Очень популярны, к примеру, генеалогические древа — они хорошо известны. Все узлы с ветвями, исходящими из единой общей вершины, являются потомками, а сама вершина называется предком (родительским узлом). Корневой узел не имеет предков, а листья не имеют потомков.
Также у дерева есть высота (глубина). Она определяется числом уровней, на которых располагаются узлы дерева. Глубина пустого древа равняется нулю, а если речь идет о дереве из одного корня, тогда единице. В данном случае на нулевом уровне может быть лишь одна вершина – корень, на 1-м – потомки корня, на 2-м – потомки потомков корня и т. д.
Ниже изображен графический вывод древа с 4-мя уровнями (дерево имеет глубину, равную четырем):
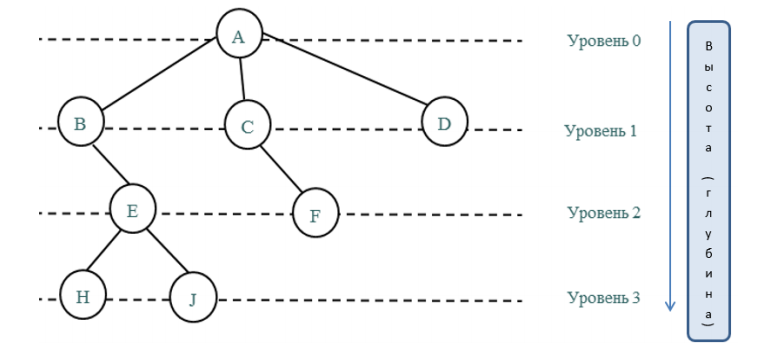
Следующий термин, который стоит рассмотреть, — это поддерево. Поддеревом называют часть древообразной структуры, которую можно представить в виде отдельного дерева.
Идем дальше. Древо может быть упорядоченным — в данном случае ветви, которые исходят из каждого узла, упорядочены по некоторому критерию.
Степень вершины в древе — это число ветвей (дуг), выходящих из этой вершины. Степень равняется максимальной степени вершины, которая входит в дерево. В этом случае листьями будут узлы, имеющие нулевую степень. По величине степени деревья бывают:
— двоичные (степень не больше двух);
— сильноветвящиеся (степень больше двух).
Деревья — это рекурсивные структуры, ведь каждое поддерево тоже является деревом. Каждый элемент такой рекурсивной структуры является или пустой структурой, или компонентом, с которым связано конечное количество поддеревьев.
Когда мы говорим о рекурсивных структурах, то действия с ними удобнее описывать посредством рекурсивных алгоритмов.
Обход древа
Чтобы выполнить конкретную операцию над всеми вершинами, надо все эти узлы просмотреть. Данную задачу называют обходом дерева. То есть обход представляет собой упорядоченную последовательность узлов, в которой каждый узел встречается лишь один раз.
В процессе обхода все узлы должны посещаться в некотором, заранее определенном порядке. Есть ряд способов обхода, вот три основные:
— прямой (префиксный, preorder);
— симметричный (инфиксный, inorder);
— обратный (постфиксный, postorder).
Существует много древовидных структур данных: двоичные (бинарные), красно-черные, В-деревья, матричные, смешанные и пр. Поговорим о бинарных.
Бинарные (двоичные) деревья
Бинарные имеют степень не более двух. То есть двоичным древом можно назвать динамическую структуру данных, где каждый узел имеет не большое 2-х потомков. В результате двоичное дерево состоит из элементов, где каждый из элементов содержит информационное поле, а также не больше 2-х ссылок на различные поддеревья. На каждый элемент древа есть только одна ссылка.
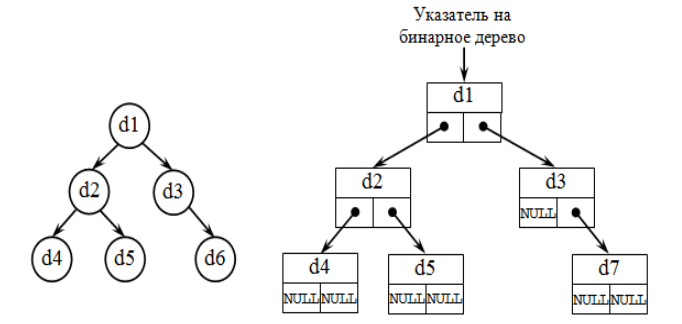
У бинарного древа каждый текущий узел — это структура, которая состоит из 4-х видов полей. Какие это поля:
— информационное (ключ вершины);
— служебное (включена вспомогательная информация, однако таких полей может быть несколько, а может и не быть вовсе);
— указатель на правое поддерево;
— указатель на левое поддерево.
Самый удобный вид бинарного древа — бинарное дерево поиска.
Что значит древо в контексте программирования?
Мы можем долго рассуждать о математическом определении древа, но это вряд ли поможет понять, какие именно выгоды можно извлечь из древовидной структуры данных. Тут важно отметить, что древо является способом организации данных в форме иерархической структуры.
В каких случаях древовидные структуры могут быть полезны при программировании: