3. Массивы NumPy
Нужно немного знать Python. Причем «немного» означает действительно немного и вовсе не означает, что перед чтением данного руководства вам нужно досконально изучить этот язык. Открытой вкладки с официальным руководством окажется вполне достаточно.
Все примеры выполнены в консоли IDE Spyder дистрибутива Anaconda на Python версии 3.5. и NumPy версии 1.14.0. Приводимые примеры так же будут работать в любом другом дистрибутиве Python 3.х версии и последней версией пакета NumPy. Но если некоторые примеры все же не работают, то ознакомьтесь с официальной документацией вашего дистрибутива, возможно причина связана с его особенностями.
Например, если в своем дистрибутиве вы обнаружили последнюю версию IDE Spyder, то в ней нет Python консоли, к которой привыкают многие новички, учившиеся экспериментировать с кодом в IDLE. При этом новичкам может так же показаться, что и все примеры, представленные здесь, тоже лучше выполнять в Python консоли. Но нет, Python консоль использовалась автором лишь по техническим причинам, которые связаны с редактурой, версткой и дизайном кода. Консоль IPython имеет гораздо больше преимуществ.
3.2. Основы
Главный объект NumPy — это однородный многомерный массив. Чаще всего это одномерная последовательность или двумерная таблица, заполненные элементами одного типа, как правило числами, которые проиндексированы кортежем положительных целых чисел. В NumPy, элементы этого кортежа называются осями, а число осей рангом.
Что бы перейти к примерам, сначала выполним импорт пакета:
Импортирование numpy под псевдонимом np уже стало общепринятой, негласной, договоренностью, можно сказать, традицией.
Теперь мы може приступить к примерам. Способов создания массивов NumPy довольно много, но мы начнем с самого тривиального — создание массива из заполненного вручную списка Python:
Теперь у нас есть одномерный массив (словосочетание «ранг массива» вряд ли приживется в русском языке), т.е. у него всего одна ось вдоль которой происходит индексирование его элементов.

Получить доступ к числу 33 можно привычным способом:
В общем-то, можно подумать, что ничего интересного и нет в этих массивах, но на самом деле это только начало кроличьей норы. Оцените:
Вместо одного индекса, указан целый список индексов. А вот еще любопытный пример, теперь вместо индекса укажем логическое выражение:
Цель этих двух примеров — не устраивать головоломку, а продемонстрировать расширенные возможности индексирования массивов NumPy. С тем как устроена индексация мы разберемся в другой главе. Что еще интересного можно продемонстрировать? Векторизованные вычисления:
Векторизованные — означает, что все арифметические операции и математические функции выполняются сразу над всеми элементами массивов. А это в свою очередь означает, что нет никакой необходимости выполнять вычисления в цикле. В случае одномерного массива, можно подумать, что это не такой уж бонус, ведь есть генераторы. Но давайте перейдем к двумерным массивам:
Сейчас мы создали массив с помощью функции np.arange() , которая во многом аналогична функции range() языка Python. Затем, мы изменили форму массива с помощью метода reshape() , т.е. на самом деле создать этот массив мы могли бы и одной командой:
Визуально, данный массив выглядит следующим образом:

Глядя на картинку, становится понятно, что первая ось (и индекс соответственно) — это строки, вторая ось — это столбцы. Т.е. получить элемент 9 можно простой командой:
Снова можно подумать, что ничего нового — все как в Python. Да, так и есть, и, это круто! Еще круто, то что NumPy добавляет к удобному и привычному синтаксису Python, весьма удобные трюки, например — транслирование массивов:
В данном примере, без всяких циклов (и генераторов), мы умножили каждый столбец из массива a на соответствующий элемент из массива b . Т.е. мы как бы транслировали (в какой-то степени можно сказать — растянули) массив b по массиву a .
То же самое мы можем проделать с каждой строкой массива a :
В данном случае мы просто прибавили к массиву a массив-столбец c . И получили, то что хотели. Сейчас мы не будем подробно рассматривать механизм транслирования — это тема другой главы. Вместо этого я хочу отметить, что при работе с двумерными или трехмерными массивами, особенно с массивами большей размерности, становится очень важным удобство работы с элементами массива, которые расположены вдоль отдельных измерений — его осей.
Например, у нас есть двумерный массив и мы хотим узнать его минимальные элементы по строкам и столбцам. Для начала создадим массив из случайных чисел и пусть, для нашего удобства, эти числа будут целыми:
Минимальный элемент в данном массиве это:
А вот минимальные элементы по столбцам и строкам:
Такое поведение заложено практически во все функции и методы NumPy:
Чтож, мы рассмотрели одномерные и двумерные массивы, а так же некоторые трюки NumPy. Но данный пакет позиционируется прежде всего как научный инструмент. Что насчет вычислений, их скорости и занимаемой памяти?
Для примера, создадим трехмерный массив:
Почему именно трехмерный? На самом деле реальный мир вовсе не ограничивается таблицами, векторами и матрицами. Еще существуют тензоры, кватернионы, октавы. А некоторые данные, гораздо удобнее представлять именно в трехмерном и четырехмерном представлении, например, биржевые торги по всем инструментам, лучше всего представлять в трехмерном виде, а торги нескольких бирж в четырехмерном. Конечно, такими сложными вычислениями занимается очень небольшое количество людей, но надо отметить, что именно эти люди двигают науку и индустрию вперед. Да и слово «сложное» можно считать синонимом «интересное. Поэтому. что-то мы отвлеклись. вот наш трехмерный массив:

Визуализация (и хорошее воображение) позволяет сразу догадаться, как устроена индексация трехмерных массивов. Например, если нам нужно вытащить из данного массива число 31, то достаточно выполнить:
Но, что если мы хотим узнать побольше об этом массиве. В самом деле, у массивов есть целый ряд важных атрибутов. Например, количество осей массива (его размерность), которую при работе с очень большими массивами, не всегда легко увидеть:
Массив a действительно трехмерный. Но иногда становится интересно, а на сколько же большой массив перед нами. Например, какой он формы, т.е. сколько элементов расположено вдоль каждой оси? Ответить позволяет метод ndarray.shape :
Метод ndarray.size просто возвращает общее количество элементов массива:
Еще может встать такой вопрос — сколько памяти занимает наш массив? Иногда даже возникает такой вопрос — влезет ли результирующий массив после всех вычислений в оперативную память? Что бы на него ответить надо знать, сколько «весит» один элемент массива:
ndarray.itemsize возвращает размер элемента в байтах. Теперь мы можем узнать сколько «весит» наш массив:
Итого — 192 байта. На самом деле, размер занимаемой массивом памяти, зависит не только от количества элементов в нем, но и от испльзуемого типа данных:
dtype(‘int32’) — означает, что используется целочисленный тип данных, в котором для хранения одного числа выделяется 32 бита памяти. Но если мы выполним какие-нибудь вычисления с массивом, то тип данных может измениться:
Теперь у нас есть еще один массив — массив b и его тип данных ‘float64’ — вещественные числа (числа с плавающей точкой) длинной 64 бита. А его размер:
Тогда массив a — 192 байта, массив b — 384 байта. А в общем, получается, 576 байт — что очень мало для современных объемов оперативной памяти, но и реальные объемы данных, которые сейчас приходится обрабатывать совсем немаленькие.
Мы с вами собирались ответить на вопросы производительности вычислений в NumPy, но это тоже тема отдельной главы. Могу лишь сказать, что на самом деле скорость вычислений, очень сильно зависит от того кода, который вы пишите. Например, частое копирование и присваивание массивов, приводит к бесполезному потреблению памяти, а работа универсальных функций NumPy без дополнительных настроек, особенно в циклах, так же может выполняться несколько медленнее. В общем задача по использованию всего вычислительного потенциала программного обеспечения и железа, не такая уж и простая, но определенно решаемая задача.
3.3. Напоследок
Если вы новичок, то очень скоро поймете, что в использовании NumPy так же прост как и Python. Но, рано или поздно, дело дойдет до сложных задач и вот тогда начнется самое интересное: документации не хватает, ничего не гуглится, а бесчисленные «почти» подходящие советы приводят к необъяснимым сверхъестественным последствиям. Что делать в такой ситуации?
- гуглить упорнее и спускаться к самому дну поисковой выдачи;
- гуглить на английском языке, потому что, на английском информации на порядки больше чем на русском;
- если не помог пункт 2, то это означает, что вы просто маньяк какой-то, и что бы решить свою маниакальную задачу, вам придется гуглить на китайском языке, потому что на китайском информации на порядки больше чем на английском.
Это шутка и серьезная рекомендация одновременно. Но, если говорить абсолютно серьезно, то просто придерживайтесь здравого смысла. Где этот здравый смысл начинается, а где заканчивается в конкретной задаче сказать очень трудно. import this вам в помощь:
Если вы раньше пользовались R или matlab, то вас тоже ожидает много приятных сюрпризов, по крайней мере один — придется меньше стучать по клавиатуре.
Array creation#
You can use these methods to create ndarrays or Structured arrays . This document will cover general methods for ndarray creation.
1) Converting Python sequences to NumPy Arrays#
NumPy arrays can be defined using Python sequences such as lists and tuples. Lists and tuples are defined using [. ] and (. ) , respectively. Lists and tuples can define ndarray creation:
a list of numbers will create a 1D array,
a list of lists will create a 2D array,
further nested lists will create higher-dimensional arrays. In general, any array object is called an ndarray in NumPy.
When you use numpy.array to define a new array, you should consider the dtype of the elements in the array, which can be specified explicitly. This feature gives you more control over the underlying data structures and how the elements are handled in C/C++ functions. If you are not careful with dtype assignments, you can get unwanted overflow, as such
An 8-bit signed integer represents integers from -128 to 127. Assigning the int8 array to integers outside of this range results in overflow. This feature can often be misunderstood. If you perform calculations with mismatching dtypes , you can get unwanted results, for example:
Notice when you perform operations with two arrays of the same dtype : uint32 , the resulting array is the same type. When you perform operations with different dtype , NumPy will assign a new type that satisfies all of the array elements involved in the computation, here uint32 and int32 can both be represented in as int64 .
The default NumPy behavior is to create arrays in either 32 or 64-bit signed integers (platform dependent and matches C int size) or double precision floating point numbers, int32/int64 and float, respectively. If you expect your integer arrays to be a specific type, then you need to specify the dtype while you create the array.
2) Intrinsic NumPy array creation functions#
NumPy has over 40 built-in functions for creating arrays as laid out in the Array creation routines . These functions can be split into roughly three categories, based on the dimension of the array they create:
1 — 1D array creation functions#
The 1D array creation functions e.g. numpy.linspace and numpy.arange generally need at least two inputs, start and stop .
numpy.arange creates arrays with regularly incrementing values. Check the documentation for complete information and examples. A few examples are shown:
Note: best practice for numpy.arange is to use integer start, end, and step values. There are some subtleties regarding dtype . In the second example, the dtype is defined. In the third example, the array is dtype=float to accommodate the step size of 0.1 . Due to roundoff error, the stop value is sometimes included.
numpy.linspace will create arrays with a specified number of elements, and spaced equally between the specified beginning and end values. For example:
The advantage of this creation function is that you guarantee the number of elements and the starting and end point. The previous arange(start, stop, step) will not include the value stop .
2 — 2D array creation functions#
The 2D array creation functions e.g. numpy.eye , numpy.diag , and numpy.vander define properties of special matrices represented as 2D arrays.
np.eye(n, m) defines a 2D identity matrix. The elements where i=j (row index and column index are equal) are 1 and the rest are 0, as such:
numpy.diag can define either a square 2D array with given values along the diagonal or if given a 2D array returns a 1D array that is only the diagonal elements. The two array creation functions can be helpful while doing linear algebra, as such:
vander(x, n) defines a Vandermonde matrix as a 2D NumPy array. Each column of the Vandermonde matrix is a decreasing power of the input 1D array or list or tuple, x where the highest polynomial order is n-1 . This array creation routine is helpful in generating linear least squares models, as such:
3 — general ndarray creation functions#
The ndarray creation functions e.g. numpy.ones , numpy.zeros , and random define arrays based upon the desired shape. The ndarray creation functions can create arrays with any dimension by specifying how many dimensions and length along that dimension in a tuple or list.
numpy.zeros will create an array filled with 0 values with the specified shape. The default dtype is float64 :
numpy.ones will create an array filled with 1 values. It is identical to zeros in all other respects as such:
The random method of the result of default_rng will create an array filled with random values between 0 and 1. It is included with the numpy.random library. Below, two arrays are created with shapes (2,3) and (2,3,2), respectively. The seed is set to 42 so you can reproduce these pseudorandom numbers:
numpy.indices will create a set of arrays (stacked as a one-higher dimensioned array), one per dimension with each representing variation in that dimension:
This is particularly useful for evaluating functions of multiple dimensions on a regular grid.
3) Replicating, joining, or mutating existing arrays#
Once you have created arrays, you can replicate, join, or mutate those existing arrays to create new arrays. When you assign an array or its elements to a new variable, you have to explicitly numpy.copy the array, otherwise the variable is a view into the original array. Consider the following example:
In this example, you did not create a new array. You created a variable, b that viewed the first 2 elements of a . When you added 1 to b you would get the same result by adding 1 to a[:2] . If you want to create a new array, use the numpy.copy array creation routine as such:
For more information and examples look at Copies and Views .
There are a number of routines to join existing arrays e.g. numpy.vstack , numpy.hstack , and numpy.block . Here is an example of joining four 2-by-2 arrays into a 4-by-4 array using block :
Other routines use similar syntax to join ndarrays. Check the routine’s documentation for further examples and syntax.
4) Reading arrays from disk, either from standard or custom formats#
This is the most common case of large array creation. The details depend greatly on the format of data on disk. This section gives general pointers on how to handle various formats. For more detailed examples of IO look at How to Read and Write files .
Standard Binary Formats#
Various fields have standard formats for array data. The following lists the ones with known Python libraries to read them and return NumPy arrays (there may be others for which it is possible to read and convert to NumPy arrays so check the last section as well)
Examples of formats that cannot be read directly but for which it is not hard to convert are those formats supported by libraries like PIL (able to read and write many image formats such as jpg, png, etc).
Common ASCII Formats#
Delimited files such as comma separated value (csv) and tab separated value (tsv) files are used for programs like Excel and LabView. Python functions can read and parse these files line-by-line. NumPy has two standard routines for importing a file with delimited data numpy.loadtxt and numpy.genfromtxt . These functions have more involved use cases in Reading and writing files . A simple example given a simple.csv :
Importing simple.csv is accomplished using loadtxt :
More generic ASCII files can be read using scipy.io and Pandas.
5) Creating arrays from raw bytes through the use of strings or buffers#
There are a variety of approaches one can use. If the file has a relatively simple format then one can write a simple I/O library and use the NumPy fromfile() function and .tofile() method to read and write NumPy arrays directly (mind your byteorder though!) If a good C or C++ library exists that read the data, one can wrap that library with a variety of techniques though that certainly is much more work and requires significantly more advanced knowledge to interface with C or C++.
6) Use of special library functions (e.g., SciPy, Pandas, and OpenCV)#
NumPy is the fundamental library for array containers in the Python Scientific Computing stack. Many Python libraries, including SciPy, Pandas, and OpenCV, use NumPy ndarrays as the common format for data exchange, These libraries can create, operate on, and work with NumPy arrays.
NumPy quickstart#
You’ll need to know a bit of Python. For a refresher, see the Python tutorial.
To work the examples, you’ll need matplotlib installed in addition to NumPy.
Learner profile
This is a quick overview of arrays in NumPy. It demonstrates how n-dimensional ( \(n>=2\) ) arrays are represented and can be manipulated. In particular, if you don’t know how to apply common functions to n-dimensional arrays (without using for-loops), or if you want to understand axis and shape properties for n-dimensional arrays, this article might be of help.
Learning Objectives
After reading, you should be able to:
Understand the difference between one-, two- and n-dimensional arrays in NumPy;
Understand how to apply some linear algebra operations to n-dimensional arrays without using for-loops;
Understand axis and shape properties for n-dimensional arrays.
The Basics#
NumPy’s main object is the homogeneous multidimensional array. It is a table of elements (usually numbers), all of the same type, indexed by a tuple of non-negative integers. In NumPy dimensions are called axes.
For example, the array for the coordinates of a point in 3D space, [1, 2, 1] , has one axis. That axis has 3 elements in it, so we say it has a length of 3. In the example pictured below, the array has 2 axes. The first axis has a length of 2, the second axis has a length of 3.
NumPy’s array class is called ndarray . It is also known by the alias array . Note that numpy.array is not the same as the Standard Python Library class array.array , which only handles one-dimensional arrays and offers less functionality. The more important attributes of an ndarray object are:
the number of axes (dimensions) of the array.
the dimensions of the array. This is a tuple of integers indicating the size of the array in each dimension. For a matrix with n rows and m columns, shape will be (n,m) . The length of the shape tuple is therefore the number of axes, ndim .
the total number of elements of the array. This is equal to the product of the elements of shape .
an object describing the type of the elements in the array. One can create or specify dtype’s using standard Python types. Additionally NumPy provides types of its own. numpy.int32, numpy.int16, and numpy.float64 are some examples.
the size in bytes of each element of the array. For example, an array of elements of type float64 has itemsize 8 (=64/8), while one of type complex32 has itemsize 4 (=32/8). It is equivalent to ndarray.dtype.itemsize .
the buffer containing the actual elements of the array. Normally, we won’t need to use this attribute because we will access the elements in an array using indexing facilities.
An example#
Array Creation#
There are several ways to create arrays.
For example, you can create an array from a regular Python list or tuple using the array function. The type of the resulting array is deduced from the type of the elements in the sequences.
A frequent error consists in calling array with multiple arguments, rather than providing a single sequence as an argument.
array transforms sequences of sequences into two-dimensional arrays, sequences of sequences of sequences into three-dimensional arrays, and so on.
The type of the array can also be explicitly specified at creation time:
Often, the elements of an array are originally unknown, but its size is known. Hence, NumPy offers several functions to create arrays with initial placeholder content. These minimize the necessity of growing arrays, an expensive operation.
The function zeros creates an array full of zeros, the function ones creates an array full of ones, and the function empty creates an array whose initial content is random and depends on the state of the memory. By default, the dtype of the created array is float64 , but it can be specified via the key word argument dtype .
To create sequences of numbers, NumPy provides the arange function which is analogous to the Python built-in range , but returns an array.
When arange is used with floating point arguments, it is generally not possible to predict the number of elements obtained, due to the finite floating point precision. For this reason, it is usually better to use the function linspace that receives as an argument the number of elements that we want, instead of the step:
Printing Arrays#
When you print an array, NumPy displays it in a similar way to nested lists, but with the following layout:
the last axis is printed from left to right,
the second-to-last is printed from top to bottom,
the rest are also printed from top to bottom, with each slice separated from the next by an empty line.
One-dimensional arrays are then printed as rows, bidimensionals as matrices and tridimensionals as lists of matrices.
See below to get more details on reshape .
If an array is too large to be printed, NumPy automatically skips the central part of the array and only prints the corners:
To disable this behaviour and force NumPy to print the entire array, you can change the printing options using set_printoptions .
Basic Operations#
Arithmetic operators on arrays apply elementwise. A new array is created and filled with the result.
Unlike in many matrix languages, the product operator * operates elementwise in NumPy arrays. The matrix product can be performed using the @ operator (in python >=3.5) or the dot function or method:
Some operations, such as += and *= , act in place to modify an existing array rather than create a new one.
When operating with arrays of different types, the type of the resulting array corresponds to the more general or precise one (a behavior known as upcasting).
Many unary operations, such as computing the sum of all the elements in the array, are implemented as methods of the ndarray class.
By default, these operations apply to the array as though it were a list of numbers, regardless of its shape. However, by specifying the axis parameter you can apply an operation along the specified axis of an array:
Universal Functions#
NumPy provides familiar mathematical functions such as sin, cos, and exp. In NumPy, these are called “universal functions” ( ufunc ). Within NumPy, these functions operate elementwise on an array, producing an array as output.
Indexing, Slicing and Iterating#
One-dimensional arrays can be indexed, sliced and iterated over, much like lists and other Python sequences.
Multidimensional arrays can have one index per axis. These indices are given in a tuple separated by commas:
When fewer indices are provided than the number of axes, the missing indices are considered complete slices :
The expression within brackets in b[i] is treated as an i followed by as many instances of : as needed to represent the remaining axes. NumPy also allows you to write this using dots as b[i, . ] .
The dots ( . ) represent as many colons as needed to produce a complete indexing tuple. For example, if x is an array with 5 axes, then
x[1, 2, . ] is equivalent to x[1, 2, :, :, :] ,
x[. 3] to x[:, :, :, :, 3] and
x[4, . 5, :] to x[4, :, :, 5, :] .
Iterating over multidimensional arrays is done with respect to the first axis:
However, if one wants to perform an operation on each element in the array, one can use the flat attribute which is an iterator over all the elements of the array:
Shape Manipulation#
Changing the shape of an array#
An array has a shape given by the number of elements along each axis:
The shape of an array can be changed with various commands. Note that the following three commands all return a modified array, but do not change the original array:
The order of the elements in the array resulting from ravel is normally “C-style”, that is, the rightmost index “changes the fastest”, so the element after a[0, 0] is a[0, 1] . If the array is reshaped to some other shape, again the array is treated as “C-style”. NumPy normally creates arrays stored in this order, so ravel will usually not need to copy its argument, but if the array was made by taking slices of another array or created with unusual options, it may need to be copied. The functions ravel and reshape can also be instructed, using an optional argument, to use FORTRAN-style arrays, in which the leftmost index changes the fastest.
The reshape function returns its argument with a modified shape, whereas the ndarray.resize method modifies the array itself:
If a dimension is given as -1 in a reshaping operation, the other dimensions are automatically calculated:
Нескучный туториал по NumPy
Ровно с тех пор, как открыл для себя векторные операции в NumPy. Я хочу познакомить вас с функциями NumPy, которые чаще всего использую для обработки массивов данных и изображений. В конце статьи я покажу, как можно использовать инструментарий NumPy, чтобы выполнить свертку изображений без итераций (= очень быстро).
Не забываем про
Что такое NumPy?
Это библиотека с открытым исходным кодом, некогда отделившаяся от проекта SciPy. NumPy является наследником Numeric и NumArray. Основан NumPy на библиотеке LAPAC, которая написана на Fortran. Не-python альтернативой для NumPy является Matlab.
В силу того, что NumPy базируется на Fortran это быстрая библиотека. А в силу того, что поддерживает векторные операции с многомерными массивами — крайне удобная.
Кроме базового варианта (многомерные массивы в базовом варианте) NumPy включает в себя набор пакетов для решения специализированных задач, например:
- numpy.linalg — реализует операции линейной алгебры (простое умножение векторов и матриц есть в базовом варианте);
- numpy.random — реализует функции для работы со случайными величинами;
- numpy.fft — реализует прямое и обратное преобразование Фурье.
Создание массива
Создать массив можно несколькими способами:
-
преобразовать список в массив:
Либо взять размеры уже существующего массива:
По умолчанию from = 0, step = 1, поэтому возможен вариант с одним параметром, интерпретируемым как To:
Либо с двумя — как From и To:
Используя метод astype, можно привести массив к другому типу. В качестве параметра указывается желаемый тип:
Все доступные типы можно найти в словаре sctypes:
Доступ к элементам, срезы
Доступ к элементам массива осуществляется по целочисленным индексами, начинается отсчет с 0:
Если представить многомерный массив как систему вложенных одномерных массивов (линейный массив, элементы которого могут быть линейными массивами), становится очевидной возможность получать доступ к подмассивам с использованием неполного набора индексов:
С учетом этой парадигмы, можем переписать пример доступа к одному элементу:
При использовании неполного набора индексов, недостающие индексы неявно заменяются списком всех возможных индексов вдоль соответствующей оси. Сделать это явным образом можно, поставив «:». Предыдущий пример с одним индексом можно переписать в следующем виде:
«Пропустить» индекс можно вдоль любой оси или осей, если за «пропущенной» осью последуют оси с индексацией, то «:» обязательно:
Индексы могут принимать отрицательные целые значения. В этом случае отсчет ведется от конца массива:
Можно использовать не одиночные индексы, а списки индексов вдоль каждой оси:
Либо диапазоны индексов в виде «From:To:Step». Такая конструкция называется срезом. Выбираются все элементы по списку индексов начиная с индекса From включительно, до индекса To не включая с шагом Step:
Шаг индекса имеет значение по умолчанию 1 и может быть пропущен:
Значения From и To тоже имеют дефолтные значения: 0 и размер массива по оси индексации соответственно:
Если вы хотите использовать From и To по умолчанию (все индексы по данной оси) а шаг отличный от 1, то вам необходимо использовать две пары двоеточий, чтобы интерпретатор смог идентифицировать единственный параметр как Step. Следующий код «разворачивает» массив вдоль второй оси, а вдоль первой не меняет:
А теперь выполним
Как видите, через B мы изменили данные в A. Вот почему в реальных задачах важно использовать копии. Пример выше должен был бы выглядеть так:
В NumPy также реализована возможность доступа ко множеству элементов массива через булев индексный массив. Индексный массив должен совпадать по форме с индексируемым.
Как видите, такая конструкция возвращает плоский массив, состоящий из элементов индексируемого массива, соответствующих истинным индексам. Однако, если мы используем такой доступ к элементам массива для изменения их значений, то форма массива сохранится:
Над индексирующими булевыми массивами определены логические операции logical_and, logical_or и logical_not выполняющие логические операции И, ИЛИ и НЕ поэлементно:
logical_and и logical_or принимают 2 операнда, logical_not — один. Можно использовать операторы &, | и
для выполнения И, ИЛИ и НЕ соответственно с любым количеством операндов:
Что эквивалентно применению только I1.
Получить индексирующий логический массив, соответсвующий по форме массиву значений можно, записав логическое условие с именем массива в качестве операнда. Булево значение индекса будет рассчитано как истинность выражения для соответствующего элемента массива.
Найдем индексирующий массив I элементов, которые больше, чем 3, а элементы со значениями меньше чем 2 и больше 4 — обнулим:
Форма массива и ее изменение
Многомерный массив можно представить как одномерный массив максимальной длины, нарезанный на фрагменты по длине самой последней оси и уложенный слоями по осям, начиная с последних.
Для наглядности рассмотрим пример:
В этом примере мы из одномерного массива длиной 24 элемента сформировали 2 новых массива. Массив B, размером 4 на 6. Если посмотреть на порядок значений, то видно, что вдоль второго измерения идут цепочки последовательных значений.
В массиве C, размером 4 на 3 на 2, непрерывные значения идут вдоль последней оси. Вдоль второй оси идут последовательно блоки, объединение которых дало бы в результате строки вдоль второй оси массива B.
А учитывая, что мы не делали копии, становится понятно, что это разные формы преставления одного и того же массива данных. Поэтому можно легко и быстро менять форму массива, не изменяя самих данных.
Чтобы узнать размерность массива (количество осей), можно использовать поле ndim (число), а чтобы узнать размер вдоль каждой оси — shape (кортеж). Размерность можно также узнать и по длине shape. Чтобы узнать полное количество элементов в массиве можно воспользоваться значением size:
Обратите внимание, что ndim и shape — это атрибуты, а не методы!
Чтобы увидеть массив одномерным, можно воспользоваться функцией ravel:
Чтобы поменять размеры вдоль осей или размерность используется метод reshape:
Важно, чтобы количество элементов сохранилось. Иначе возникнет ошибка:
Учитывая, что количество элементов постоянно, размер вдоль одной любой оси при выполнении reshape может быть вычислен из значений длины вдоль других осей. Размер вдоль одной оси можно обозначить -1 и тогда он будет вычислен автоматически:
Можно reshape использовать вместо ravel:
Рассмотрим практическое применение некоторых возможностей для обработки изображений. В качестве объекта исследования будем использовать фотографию:

Попробуем ее загрузить и визуализировать средствами Python. Для этого нам понадобятся OpenCV и Matplotlib:
Результат будет такой:

Обратите внимание на строку загрузки:
OpenCV работает с изображениями в формате BGR, а нам привычен RGB. Мы меняем порядок байтов вдоль оси цвета без обращения к функциям OpenCV, используя конструкцию
«[:, :, ::-1]».
Уменьшим изображение в 2 раза по каждой оси. Наше изображение имеет четные размеры по осям, соответственно, может быть уменьшено без интерполяции:

Поменяв форму массива, мы получили 2 новые оси, по 2 значения в каждой, им соответствуют кадры, составленные из нечетных и четных строк и столбцов исходного изображения.
Низкое качество свзано с использованием Matplotlib, за то там видны размеры по осям. На самом деле, качество уменьшенного изображения такое:

Перестановка осей и траспонирование
В кроме изменения формы массива при неизменном порядке единиц данных, часто встречается необходимость изменить порядок следования осей, что естественным образом повлечет перестановки блоков данных.
Примером такого преобразования может быть транспонирование матрицы: взаимозамена строк и столбцов.
В этом примере для транспонирования матрицы A использовалась конструкция A.T. Оператор транспонирования инвертирует порядок осей. Рассмотрим еще один пример с тремя осями:
У этой короткой записи есть более длинный аналог: np.transpose(A). Это более универсальный инструмент для замены порядка осей. Вторым параметром можно задать кортеж номеров осей исходного массива, определяющий порядок их положения в результирующем массиве.
Для примера переставим первые две оси изображения. Картинка должна перевернуться, но цветовую ось оставим без изменения:

Для этого примера можно было применить другой инструмент swapaxes. Этот метод переставляет местами две оси, указанные в параметрах. Пример выше можно было реализовать так:
Объединение массивов
Объединяемые массивы должны иметь одинаковое количество осей. Объединять массивы можно с образованием новой оси, либо вдоль уже существующей.
Для объединения с образованием новой оси исходные массивы должны иметь одинаковые размеры вдоль всех осей:
Как видно из примера, массивы-операнды стали подмассивами нового объекта и выстроились вдоль новой оси, которая стоит самой первой по порядку.
Для объединения массивов вдоль существующей оси, они должны иметь одинаковый размер по всем осям, кроме выбранной для объединения, а по ней могут иметь произвольные размеры:
Для объединения по первой или второй оси можно использовать методы vstack и hstack соответсвенно. Покажем это на примере изображений. vstack объединяет изображения одинаковой ширины по высоте, а hsstack объединяет одинаковые по высоте картинки в одно широкое:


Обратите внимание на то, что во всех примерах этого раздела объединяемые массивы передаются одним параметром (кортежем). Количество операндов может быть любым, а не обязательно только 2.
Также обратите внимание на то, что происходит с памятью, при объединении массивов:
Так как создается новый объект, данные в него копируются из исходных массивов, поэтому изменения в новых данных не влияют на исходные.
Клонирование данных
Оператор np.repeat(A, n) вернет одномерный массив с элементами массива A, каждый из которых будет повторен n раз.
После этого преобразования, можно перестроить геометрию массива и собрать повторяющиеся данные в одну ось:
Этот вариант отличается от объединения массива с самим собой оператором stack только положением оси, вдоль которой стоят одинаковые данные. В примере выше это последняя ось, если использовать stack — первая:
Как бы ни было выполнено клонирование данных, следующим шагом можно переместить ось, вдоль которой стоят одинаковые значения, в любую позицию с системе осей:
Если же мы хотим «растянуть» какую либо ось, используя повторение элементов, то ось с одинаковыми значениями надо поставить после растягиваемой (используя transpose), а затем объединить эти две оси (используя reshape). Рассмотрим пример с растяжением изображения вдоль вертикальной оси за счет дублирования строк:

Математические операции над элементами массива
Если A и B массивы одинакового размера, то их можно складывать, умножать, вычитать, делить и возводить в степень. Эти операции выполняются поэлементно, результирующий массив будет совпадать по геометрии с исходными массивами, а каждый его элемент будет результатом выполнения соответствующей операции над парой элементов из исходных массивов:
Можно выполнить любую операцию из приведенных выше над массивом и числом. В этом случае операция также выполнится над каждым из элементов массива:
Учитывая, что многомерный массив можно рассматривать как плоский массив (первая ось), элементы которого — массивы (остальные оси), возможно выполнение рассматриваемых операций над массивами A и B в случае, когда геометрия B совпадает с геометрией подмассивов A при фиксированном значении по первой оси. Иными словами, при совпадающем количестве осей и размерах A[i] и B. Этом случае каждый из массивов A[i] и B будут операндами для операций, определенных над массивами.
В этом примере массив B подвергается операции с каждой строкой массива A. При необходимости умножения/деления/сложения/вычитания/возведения степень подмассивов вдоль другой оси, необходимо использовать транспонирование, чтобы поставить нужную ось на место первой, а затем вернуть ее на свое место. Рассмотри пример выше, но с умножением на вектор B столбцов массива A:
Для более сложных функций (например, для тригонометрических, экспоненты, логарифма, преобразования между градусами и радианами, модуля, корня квадратного и.д.) в NumPy есть реализация. Рассмотрим на примере экспоненты и логарифма:
С полным списком математических операций в NumPy можно ознакомиться тут.
Матричное умножение
Описанная выше операция произведения массивов выполняется поэлементно. А при необходимости выполнения операций по правилам линейной алгебры над массивами как над тензорами можно воспользоваться методом dot(A, B). В зависимости от вида операндов, функция выполнит:
- если аргументы скаляры (числа), то выполнится умножение;
- если аргументы вектор (одномерный массив) и скаляр, то выполнится умножение массива на число;
- если аргументы вектора, то выполнится скалярное умножение (сумма поэлементных произведений);
- если аргументы тензор (многомерный массив) и скаляр, то выполнится умножение вектора на число;
- если аргументы тензора, то выполнится произведение тензоров по последней оси первого аргумента и предпоследней — второго;
- если аргументы матрицы, то выполнится произведение матриц (это частный случай произведения тензоров);
- если аргументы матрица и вектор, то выполнится произведение матрицы и вектора (это тоже частный случай произведения тензоров).
Рассмотрим примеры со скалярами и векторами:
С тензорами посмотрим только на то, как меняется размер геометрия результирующего массива:
Для выполнения произведения тензоров с использованием других осей, вместо определенных для dot можно воспользоваться tensordot с явным указанием осей:
Мы явно указали, используем третью ось первого массива и вторую — второго (размеры по этим осям должны совпадать).
Агрегаторы
Агрегаторы — это методы NumPy позволяющие заменять данные интегральными характеристиками вдоль некоторых осей. Например, можно посчитать среднее значение, максимальное, минимальное, вариацию или еще какую-то характеристику вдоль какой-либо оси или осей и сформировать из этих данных новый массив. Форма нового массива будет содержать все оси исходного массива, кроме тех, вдоль которых подсчитывался агрегатор.
Для примера, сформируем массив со случайными значениями. Затем найдем минимальное, максимальное и среднее значение в его столбцах:
При таком использовании mean и average выглядят синонимами. Но эти функции обладают разным набором дополнительных параметров. У нах разные возможности по маскированию и взвешиванию усредняемых данных.
Можно подсчитать интегральные характеристики и по нескольким осям:
В этом примере рассмотрена еще одна интегральная характеристика sum — сумма.
Список агрегаторов выглядит примерно так:
- сумма: sum и nansum — вариант корректно обходящийся с nan;
- произведение: prod и nanprod;
- среднее и матожидание: average и mean (nanmean),
nanaverageнету; - медиана: median и nanmedian;
- перцентиль: percentile и nanpercentile;
- вариация: var и nanvar;
- стандартное отклонение (квадратный корень из вариации): std и nanstd;
- минимальное значение: min и nanmin;
- максимальное значение: max и nanmax;
- индекс элемента, имеющего минимальное значение: argmin и nanargmin;
- индекс элемента, имеющего максимальное значение: argmax и nanargmax.
Если не указать оси, то по умолчанию все рассматриваемые характеристики считаются по всему массиву. В этом случае argmin и argmax тоже корректно отработают и найдут индекс максимального или минимального элемента так, как буд-то все данные в массиве вытянуты вдоль одной оси командой ravel().
Еще следует отметить, агрегирующие методы определены не только как методы модуля NumPy, но и для самих массивов: запись np.aggregator(A, axes) эквивалентна записи A.aggregator(axes), где под aggregator подразумевается одна из рассмотренных выше функций, а под axes — индексы осей.
Вместо заключения — пример
Давайте построим алгоритм линейной низкочастотной фильтрации изображения.
Для начала загрузим зашумленное изображение.

Рассмотрим фрагмент изображения, чтобы увидеть шум:

Фильтровать изображение будем с использованием гауссова фильтра. Но вместо выполнения свертки непосредственно (с итерированием), применим взвешенное усреднение срезов изображения, сдвинутых относительно друг друга:
Применим эту функцию к нашему изображению единожды, дважды и трижды:
Получаем следующие результаты:


при однократном применении фильтра;




Видно, что с повышением количества проходов фильтра снижается уровень шума. Но при этом снижается и четкость изображения. Это известная проблема линейных фильтров. Но наш метод денойзинга изображения не претендует на оптимальность: это лишь демонстрация возможностей NumPy реализации свертки без итераций.
Теперь давайте посмотрим, сверткам с какими ядрами эквивалентна наша фильтрация. Для этого подвергнем аналогичным преобразованиям одиночный единичный импульс и визуализируем. На самом деле импульс будет не единичным, а равным по амплитуде 255, так как само смешивание оптимизировано под целочисленные данные. Но это не мешает оценить общий вид ядер:
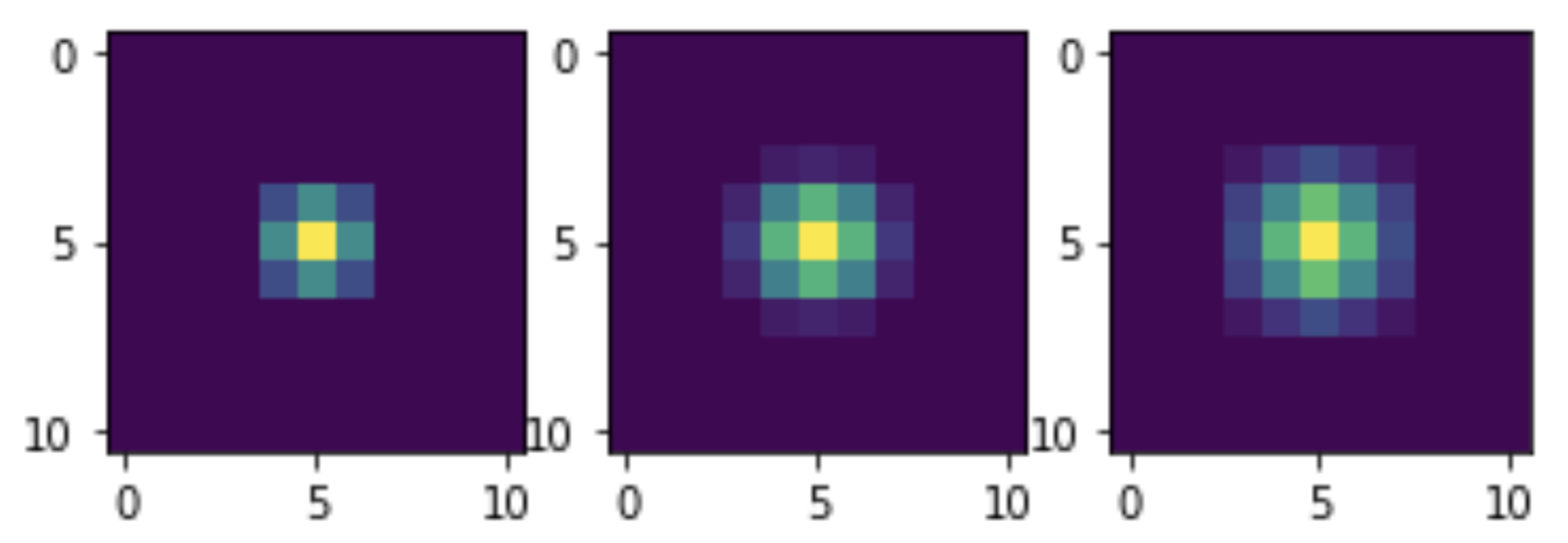
Мы рассмотрели далеко не полный набор возможностей NumPy, надеюсь, этого было достаточно для демонстрации всей мощи и красоты этого инструмента!