Русские Блоги
Сколько строк в исходном коде Win 10? Какой язык программирования использовался?
(дайте Те вещи о программистах Помечено )
Оригинальная отделка: те штучки о программистах (id: iProgrammer)
В октябре 2013 года мы разместили на Weibo картинку (@ programmer’s things) инфограмма " Сравнение кодовых баз известных программных систем.
В инфографике упоминается, что объем кода для операционных систем Windows XP и Windows 7 составляет около 40 миллионов строк.
( инфограмма Несколько скриншотов, полная версия здесь: http: //t.cn/EXMs07e )
Windows Объем исходного кода Vista составляет около 50 миллионов строк.

Следовательно, объем исходного кода Windows 10 составляет не менее 50 миллионов строк.
Какой язык программирования использовался при разработке операционной системы Windows?
Windows операционная система Кому-то должно быть интересно, какой язык программирования используется для такой масштабной кодовой базы.
Это правда? Кто-то написал на Quora с вопросом: «Разработка W ind ows 10 Какой язык программирования используется? 》
В марте 2019 года инженер ядра Microsoft Аксель Ритчин ответил на этот пост на Quora.

«Вот что о программистах»:
Axel Говорят, что Windows 10 и Windows 8.x, 7, Vista, XP, 2000 и NT имеют одинаковую кодовую базу. Каждое поколение операционных систем претерпело серьезный рефакторинг, добавив большое количество новых функций, улучшив производительность и поддержку оборудования. И безопасность при сохранении очень высокой обратной совместимости.
Ядро (ntoskrnl.exe) Большинство из них написано на языке Си . Вы можете найти просочившуюся версию Windows Research Kernel на Github.

Детскую обувь, кому интересно, могут посмотреть: github.com/markjandrews/wrk-v1.2
Axel Сказал, что, хотя код WRK устарел и в основном неполный, он должен дать вам некоторое представление.
Например: каталог wrk-v1.2 / base / ntos / config — это исходный код известного реестра (Registry) .Этот компонент ядра является диспетчером конфигурации (CM).
Большинство программ, работающих в режиме ядра, также написаны на языке C. (Большинство файловых систем, сетей, большинство драйверов . ) и немного C ++.
Что касается языка программирования, на котором написано Window 10, Аксель считает, что это C и C ++, причем C составляет большинство.
.NET BCL И другие управляемые библиотеки и фреймворки обычно используют C # Написано, Из разных отделов ( Отдел разработчиков) И не принадлежит Windows Исходное дерево 。 По сравнению с океаном кода C, разбросанным по островам C ++, код, написанный на C #, — просто капля в море. 。
Windows действительно правда В самом деле В самом деле В самом деле Очень большой
Axel Я напоминаю всем, что большинство людей не осознают огромных размеров системы Windows, огромного проекта с эпическим масштабом.
Размер полного дерева исходного кода Windows (включая все коды, тестовые коды и т. Д.) Превышает 0,5 ТБ, что включает Более 56 миллионов папок, 400 Более десяти тысяч файлов 。

Вы можете потратить год, копаясь в дереве исходных текстов и копаясь в этих файлах. Они включают в себя все компоненты рабочей станции и серверных продуктов ОС, а также все их версии, инструменты и соответствующие комплекты разработки.
Затем вы снова читаете имя файла, чтобы увидеть, что в нем и для чего они используются. Хочу закончить эти дела , Персона (Или два человека ) Боюсь закончить жизнь 。
один раз Axel Покинув ветку Git на несколько недель, он вернулся и обнаружил, что за ним почти 60 000 коммитов. Axel Я думаю, кто-то сказал бы, что никто не может читать весь код, добавленный в Windows каждый день, не говоря уже о том, чтобы читать код, написанный за последние 30 лет!
Рекомендуемая литература
(Щелкните заголовок, чтобы перейти к прочтению)
Обратите внимание на звезду "вещи программиста" и не пропустите кружок.
Количество строк кода в разных приложениях, системах
А вы задумывались из чего состоят системы которыми вы пользуетесь? Ответ на этот вопрос с вашей стороны меня не волнует (извините за возможную грубость). Сегодня, именно сегодня, я в любом случае расскажу вам о количестве строчек кода в разных проектах.
Начинаем с разных «операционок» — без них никуда.
1. Windows NT 3.1 — появилась на свет в далеком 1993, уже тогда содержала в себе больше 4 млн. строчек на С и С++.
2. Windows NT 3.5 — родилась на год позже своего брата на С++ о котором мы говорили ранее.
Количество строк кода достигало 8 млн. Умный читатель может вычесть из этого количества 4 млн. — получить число на которое выросло число строчек кода за год.
3. А теперь вышедшая в 1996 году Windows NT 4.0, содержащая в себе 11-12 млн. строк.
4. Windows 2000. Просто молчу. целых 30 млн строк.
Стоит признать, это не предел, ведь дальше у нас Windows XP.
5. Windows XP — около 45 млн. строчек. Если я сказал, что предыдущие ОС содержали в себе много кода — прошу простить.
6. Windows 10 — более 60 млн. строк. По настоящему сложная сборка.
Что-то мы застряли на «Винде». Давайте перейдем к Linux.
1. Linux 0.1 — 10 239 строчек. Не стоит забывать, что выпуск этой версии состоялся в 1991 году.
2. Linux 1.0.0 вышедший спустя 3 года состоял из более чем 170к строк.
3. Linux 1.2.0 появившийся на свет в 1995 был создан при помощь 300к строчек.
4. Linux 2.0.0 — 777 956 строк.
5. Linux 2.2.0 — 1 800 847 строк.
6. 2001 год — рождается Linux 2.4.0 состоящий из 3 377 902 строк кода.
7. Linux 2.6.0 — 5 929 913 строк.
8. Linux 2.6.32 — 12 606 910 строк.
9. 2017 год на дворе — выходит Linux 4.11.7 основанный на 18 млн. строчках.

Android? 12 млн. строк.

Переходим к браузерам.
1. Google Chrome — 7 млн. строчек кода на C++.

2. Firefox — 18 млн. строк. В создании Firefox замешаны C++, C, Javascript, Rust, HTML, CSS, XUL.

Переход к обсуждению приложений, программ, фреймворков.
1. Photoshop CS 6 — 10 млн. строк кода. Величайшее изобретение, ежедневно помогающее дизайнерам, верстальщикам, разработчикам, блогерам.
2. 1C — 3 млн. строк.
3. MySql — 12 млн. строчек кода.
4. Unreal Engine 3 — около 2 млн. строк на C++. Движок для создания игр.
5. Bootstrap — популярный фреймворк для создания сайтов и веб-приложений. Состоит из 70к строчек.

6. React — популярный фреймворк от Facebook. Чуть меньше 160к строк.

7. Vue.js — популярный фреймворк для создания пользовательских интерфейсов.

Надеюсь вам понравилось!
На счет линукса — некорректно.
Когда вы приводилиипримеры винды, вы брали операционную систему. А линукс — это не операционная система — это ядро операционной системы. А операционная система с ядром линукс будет, например: linux mint, ubuntu, cent os, debian, fedora и много других. Поэтому количество строк в линукс-дистрибубутивах будет больше. Например в линукс минте браузером по умолчанию является фаерфокс, а это значит, что там в ядре линукса 18млн. строк + в фаерфоксе тоже 18млн. строк и еще много всякой хрени.
Для unreal engine взяли скриншот окна cinema 4d. Автор «потрудился» над статьёй как надо.
Игра «Посадка на Луну» на калькуляторе МК60: 1 (одна) строка кода.
Полный бред полного чайника.
Почти все сравнения некорректны типа кода в ЯДРЕ LINUX коим явлется Linux и ПОЛНОЙ СИСТЕМЕ где в 10 раз больше в GNU окружении даже уровня IceWM, а в полноценном DE ещё процентов 20 накинет как в ядре. А винда это полная система, ядро у неё к слову, достаточно простое и рядом с NET не стояло, так же начиная с 2000/xp винды не особо росло.

Знакомо?

Топ 10 ресурсов на русском языке, которые могут помочь в изучении Python
Вот список из 10 ресурсов на русском языке, которые могут помочь в изучении Python:
1. Python.org на русском языке – официальный сайт языка Python, который содержит множество документации, руководств, обучающих материалов и примеров.
2. ‘A Byte of Python’ на русском языке – это онлайн-учебник, который предназначен для начинающих программистов и помогает освоить основы языка Python.
3. Pythontutor.ru – это онлайн-платформа с интерактивными задачами и упражнениями, которые помогают закрепить теоретические знания.
4. Rus-linux.net – это портал, который содержит множество статей и обучающих материалов по Python.
5. Learnpython.ru – это онлайн-курс, который предоставляет пошаговый и практический подход к изучению языка Python.
6. Pythonworld.ru – это онлайн-учебник по Python, который содержит подробные описания синтаксиса языка, примеры и задачи для решения.
7. Pythonicway.com – это сайт, который содержит множество статей, видеоуроков и других материалов, которые помогают в изучении Python.
8. Coursera.org – на этой платформе можно найти большое количество курсов по Python от ведущих университетов и экспертов в области программирования.
9. Geekbrains.ru – это онлайн-платформа, которая содержит множество курсов по Python и другим языкам программирования.
10. Tproger.ru – это портал о технологиях и программировании, где можно найти множество материалов о Python и других языках программирования.

А никто не говорил, что будет легко
Настоящий программист никогда не ставит комментариев. То, что писалось с трудом, должно пониматься с трудом.

SSD технологии древних: DiskOnChip
Автор: dlinyj
Оригинальный материал
Дополнительные фото, ссылки, а также информация по DiskOnChip в источнике материала. Всё попросту не влезло 🙁

В середине 1990-х, FLASH-накопители были очень дорогими, поэтому появление твердотельных накопителей сильно задерживалось. Стоимость 1 МБ FLASH-памяти была несоизмеримо дорога в сравнении со стоимостью 1 МБ памяти на физическом жёстком диске, с блинами.
Но, несмотря на это, в 1995 году — израильская компания M-Systems представила первый полупроводниковый накопитель. Это был настоящий жёсткий «диск», который выглядел как обычная 32-х контактная DIP-микросхема. Более того, он устанавливался вместо микросхемы расширения BIOS, при этом имел на борту ёмкость в десятки, а то и сотни мегабайт. В те годы — это было просто космические технологии, и в последствии они встречались и использовались достаточно часто, но уже в промышленном секторе.
Это система DiskOnChip – фактически полноценный жёсткий диск на одной маленькой микросхеме, с минимальной обвязкой, которая для своей работы потребует всего два чипа логики.
Ну что же, попробуем собрать свою необычную систему с этим жёстким «диском», проверю, может ли она работать с обычной ROM-памятью, запущу наконец свой BIOS на 386 машине с ISA-картой, чего не удалось в прошлый раз.
❯ Что же такое DiskOnChip®?
DiskOnChip (далее – DOC) – это фактически продолжение идеи расширения BIOS, о котором я достаточно подробно писал в статье «Пишем свой ROM BIOS».
DOC представляет собой обычную DIP-микросхему и вставляется в ту же панельку, что EEPROM, как на сетевой карте, живёт по тем же адресам и даже в начале содержит код BIOS инициализации. И микросхема pin-to-pin совместима с некоторыми микросхемами ПЗУ! Однако далее, в старших адресах этой микросхемы, содержатся регистры управления, которые переключают окна FLASH-памяти.
Для сравнения можно посмотреть расположение выводов DiskOnChip 2000 и микросхемы EEPROM SST 29EE512 (64К x 8). Отличие только в количестве адресных линий, потому что DOC работает через окно в 8К х 8 (как восьмикилобайтная EEPROM).
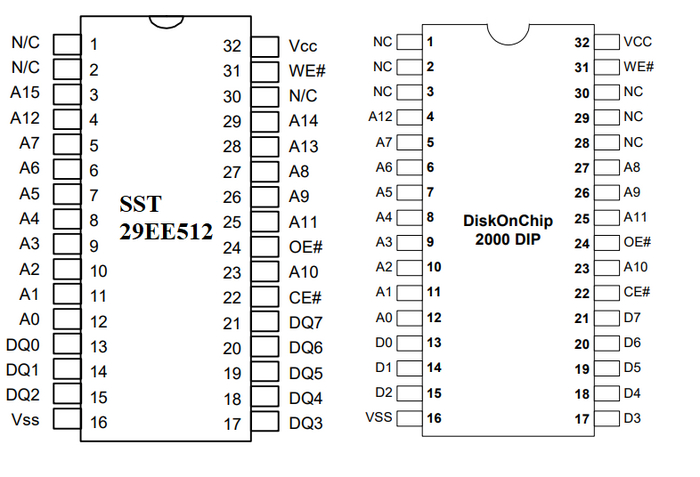
Сравнение распиновки EEPROM и DOC
Фактически электрический интерфейс работы с DiskOnChip ничем не отличается от интерфейса работы с обычной EEPROM. Сигнальные линии называются также, и она совместима с ними по ногам.

Структурная схема DOC
DiskOnChip занимает 8 КБ памяти. При этом — во время старта, она выглядит как обычная ROM BIOS, и инициализирует код для работы в реальном режиме, добавляя в прерывание BIOS 13h ПО для работы по этому интерфейсу.
При работе в реальном режиме, когда передаётся код управления BIOS в его внутреннюю EEPROM, он подменяет прерывание 13h по работе с диском. Таким образом, он начинает мапить в старшие адреса по очереди страницы флэш-памяти, с помощью регистров управления.

Карта памяти DiskOnChip 2000
Если рассмотреть карту памяти, которая доступна системе в пространстве 8 КБ, то мы увидим что оно состоит из четырёх разделов по 2 КБ.
Секция 0: Загрузочный блок. Этот раздел содержит данные, которые выполняются при загрузке BIOS.
Секция 1: Загрузочный блок 2. Содержит вторую часть загрузочной области.
Секция 2: Регистры управления. Используется для управления поведением DiskOnChip 2000 и флэш-носителя.
Секция 3: Окно доступа к FLASH-накопителю. Окно, чрез которую видно область FLASH для записи или чтения данных.
Как можно понять, вся доступная память, в моём случае 8 МБ, доступна через маленькое окно в 2 КБ и переключается с помощью регистров управления.
В более сложных системах, которые работают уже в защищённом режиме, таких как Windows CE, Windows 2000, QNX, Linux и т. д., где недоступен код инициализации и прерывание 13h, для работы требуются специализированные драйвера файловой системы DOC, называемой TrueFFS.
Подводя итог, можно сказать, что DiskOnChip – это примитивный SSD того времени, который успешно применялся во многих встраиваемых системах. Чаще всего его можно было встретить в одноплатных компьютерах, в кассах, тонких клиентах и другом аналогичном оборудовании. Вот, например, недавно через мои руки прошёл моноблок для ресторанов Micros WS4. Как я понял, он использовался официантами для приёма заказа.

Внешний вид моноблока
И после вскрытия внутри можно обнаружить микросхему DiskOnChip, несмотря на то, что он работает под управлением операционной системы Windows CE.

Микросхема DiskOnChip
Самое приятное, что из-за простоты устройства DOC для его подключения к компьютеру не требуется использовать каких-либо контроллеров жёстких дисков, от них можно вообще отказаться! Схема подключения содержит всего две микросхемы логики.

Кстати, если вас пугают импортные микросхемы 74-й серии, то, во-первых, их можно взять с другими буквенными индексами, а во-вторых, вполне можно заменить на отечественные аналоги, например:
74-серияаналог74139155ид1474138155ид7
А ещё их можно заменить на микросхемы серии к155, к555, кр1564 и всё будет прекрасно работать.
Схема простая, значит можно попробовать запустить его на любом старом железе!
❯ Ваяю плату расширения
Много лет хочу сделать плату расширения для шины ISA. Ещё со студенческой скамьи вынашивал идеи, прикидывал дешифраторы адреса для создания своей платы расширения. Даже как-то пытался паять параллельный порт на микросхеме КР580ВВ55. Но всё это было не торт, и толком не работало.
Здесь другое дело, схема простая, всего три микросхемы, как работает – понятно. Осталось дело за малым – это всё реализовать. Мне было лениво заниматься разводкой печатной платы, поэтому решил делать всё на макетке. В качестве основы платы взял проект IBM PC XT8-bit ISA Prototype PCB Card XL.
В Китае заказал изготовления платы, микросхему DOC на 8 МБ и уже здесь нашёл подходящие микросхемы логики: 74HC138AP и 74HC139AP (обратите внимание, что буквенные индексы иные). Самое тяжёлое – это было томительное ожидание, когда изготовят платы и их отправят. Спустя несколько месяцев у меня всё было на руках.

Всё готово к сборке
После того как я всё получил, распечатал схему и даташиты на микросхемы с распиновкой. Для удобства сразу нарисовал, что и куда должно идти. Что удобно, на макетке подписаны все сигналы, и ошибиться просто невозможно.
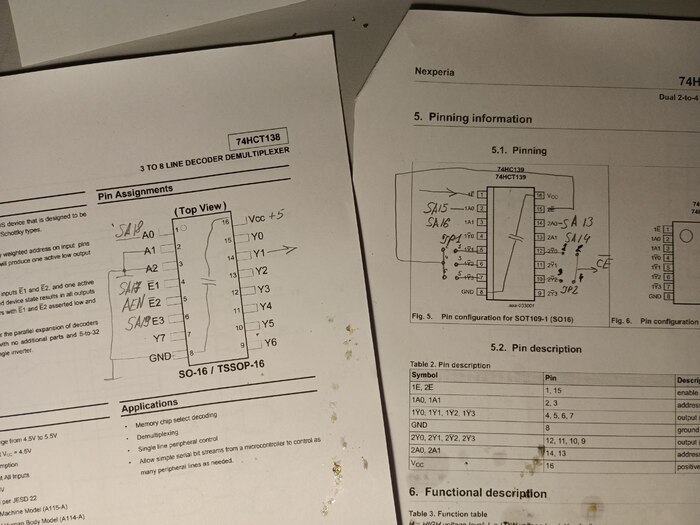
Набросок схемы
Далее предстоит кружок кройки и шитья, и покуда я собирал всё это хозяйство, десять раз пожалел, что не развёл плату сразу. Потому что убил просто громадное количество времени на все эти проводочки.

Кружок кройки и шитья
Спустя неделю вечеров пайки получил-таки готовый результат.

Вид спереди

Далее предстоит самое интересное – тестирование!
❯ Проверка работоспособности DiskOnChip
Проверку проводил на материнских платах с процессорами 386SX и Pentium 1. Как обычно бывает, где-то был неконтакт или непропай. После исправления мелких недочётов система сразу подхватила BIOS из DOC, и я увидел при загрузке ключевое сообщение, о том, что TrueFFS-BIOS запустился.
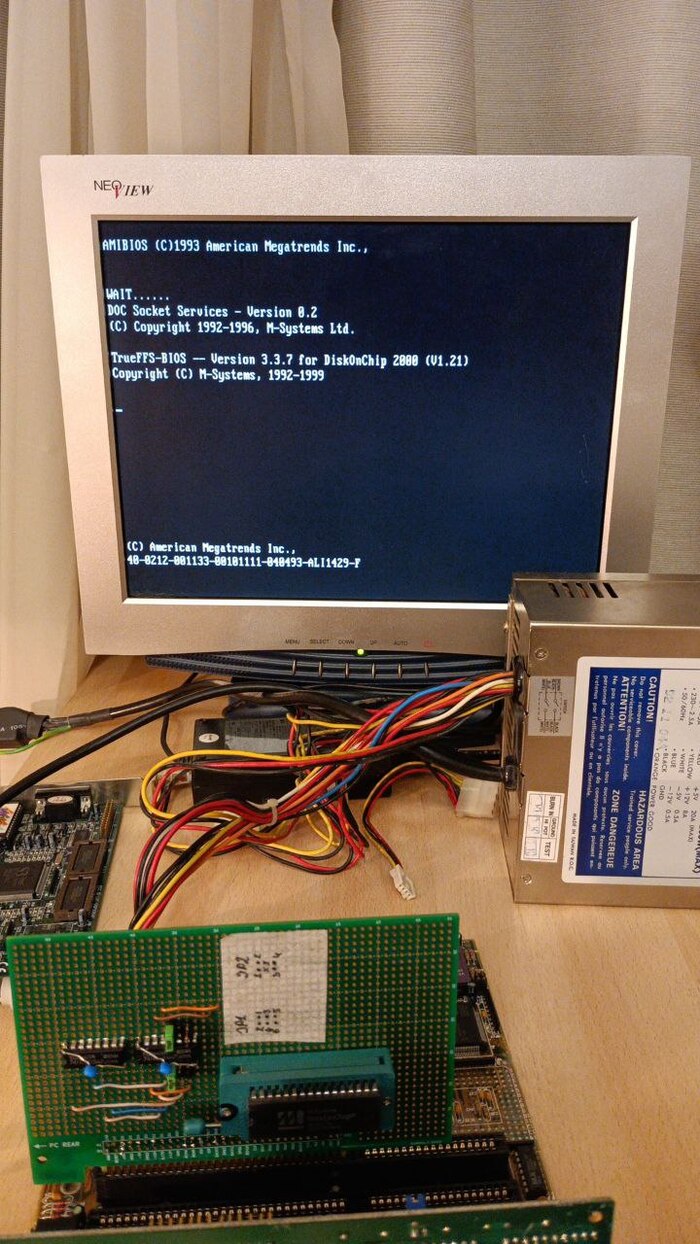
Если загрузиться вместе с жёстким диском, то можно увидеть второй диск D:, который можно отформатировать в системный раздел и перенести на него файлы, что я и сделал. Забегая вперёд, скажу, что форматировать стандартным format d: /s нельзя! То есть если очень хочется, то можно, но результат непредсказуем.

Намного более правильно работать с этим «диском» с помощью его родных утилит, которые корректно работают с TrueFFS. После того как я отформатировал диск родными утилитами, можно было перенести систему, отсоединить плату контроллера дисков и оставить только видеокарту и мою самодельную платку.
Удивительно, но это работает!

Ничего лишнего: только материнская плата, видеокарта и DOC
Самое забавное, что при загрузке BIOS не видит никаких подключённых носителей: ни флоппи, ни жёстких дисков. Но несмотря на это, всё равно идёт загрузка DOS. Лучше всего посмотреть на видео.
❯ Не всё так гладко с этим DOC…
На самом деле, не всё так гладко. То ли мне не повезло с микросхемой, то ли какая-то другая проблема, но DOC глючил. Он не всегда успешно загружался на моей плате, так и на железе, которое умеет работать с DOC из коробки (имеет аппаратную и программную поддержку в системном BIOS). То есть выглядело так, BIOS TrueFFS стартует, но диска при загрузке не видит. После перезагрузки стартует нормально, потом снова не видит. С чем связано – непонятно.
В какой-то момент при загрузке начались артефакты с запуском программ, а при переходе в папку увидел такое:
Так выглядит смерть жёсткого диска
И после этого загружаться он отказался. Спасло только форматирование его штатными утилитами. Что это было – я не знаю. Сетую на то, что у меня одна из первых версий микросхем, возможно, она немного сырая.
❯ Замена DiskOnChip на EEPROM
Hо перед нами прогресс открывал все пути,
И, бросив старых друзей ради новых ХТ,
Мы выжимали, что можно, из DOS и из архитектуры,
Меняли коды команд, трассировали INT’ы
Дизассемблировали BIOS и писали в порты
То, что я б не позволил печатать на месте цензуры.
Мне всё же хотелось продемонстрировать, что вместо DOC можно поставить обычную ROM микросхему, и это решение будет работать. В результате это вылилось в столь громадный квест, что потянет на ещё одну статью, а то и не одну. Там пришлось дизассемблировать основной BIOS, была попытка запустить его в qemu и много других забавных экспериментов. Но всё же, оставлю это всё самое интересное за кадром, и расскажу суть.
В качестве микросхемы ПЗУ взял EEPROM SST 29EE512 просто потому, что она у меня была под рукой, и была pin-to-pin совместима с DOC. Внимательный читатель заметит (хотя уверен, что таких нет), что это та же самая микросхема, которую я использовал в статье «Пишем свой ROM BIOS». Для корректной работы 64КБ ROM в области памяти 8 КБ, нужно посадить неиспользуемые старшие адреса на землю. То есть, фактически мы превращаем микросхему в 8 килобайтную EEPROM.
В процессе экспериментом выяснилось, что БИОС на материнской плате пытается писать в EEPROM, и, таким образом, портит её содержимое. Для того чтобы этого не происходило, доработал переходник, удалив контакт с сигналом разрешения записи WE.


Больше переходников, богу переходников!
Изначально планировал попробовать точно также запустить BASIC-ROM, но как я не бился, так и не смог его стартануть. То есть, видно, что происходит успешная инициализация, системный BIOS «зависает» без ошибок, значит переход на код ПЗУ состоялся, о чём также свидетельствовали POST-коды. Но ничего больше не происходило. В отчаянной попытке я начал искать JTAG-отладчики для 386 архитектуры, пытался запустить BIOS материнской платы в qemu, но всё тщетно. Идей, как отлаживать подобные BIOS у меня пока нет. Хотя задача, крайне интересная, как же заниматься отладкой различных расширений BIOS.
Обращаю внимание, что в qemu c SeaBIOS и на другой материнской плате, с EPROM на PCI-карте всё прекрасно работало.

Установленная микросхема ПЗУ, вместо DOC
В конце концов, я не нашёл выхода из этой ситуации, поэтому решил идти по более простому пути и запустить ROM HELLO. К слову сказать, в том коде я тоже обнаружил ошибку.
Как оказалось, после того как я посчитал контрольную сумму, оставшиеся байты надо было сделать равными нулю. Чтобы в результате общая сумма давала нуль. И мне сильно повезло, что на PCI тогда этот код завёлся. Вообще, то что на PCI плате это работало – чудо, потому что потом я внимательно прочитал стандарты, он не должен был работать никак. Исправление этой ошибки запуску BASIC не поспособствовали.
В результате всех мытарств, которые по времени заняли больший и наиболее сложный промежуток, чем эксперименты с DOC, мне удалось на этой же плате стартануть мой самописный BIOS.

Успешный запуск на материнской плате Pentium
Это, конечно, очень интересное колхозничество, но что насчёт промышленных железок, будет ли оно работать и там?
❯ Тест на железе с панелькой под DOC
Всё это забавно и хорошо, хочется попробовать запустить реальное железо, которое имеет поддержку DiskOnChip прямо из коробки. Специально для этого прикупил себе старинный тонкий клиент Light System LG8101, внутри которого есть панелька для DOC.

Внешний вид тонкого клиента
Если вскрыть эту штуку, то внутри можно обнаружить CF, с которой идёт загрузка, и панельку под DiskOnChip. В неё можно и проинсталлировать нашу замечательную микросхему.

Эта железка имеет поддержку DOC на уровне BIOS, так что запуск TrueFFS-BIOS не требуется. Обратная сторона этой поддержки в том, что сюда не получится вставить свою ROM-память, эта панелька предназначена только для микросхемы DiskOnChip (да, я попробовал вставить туда свою ROM, но ничего не произошло).
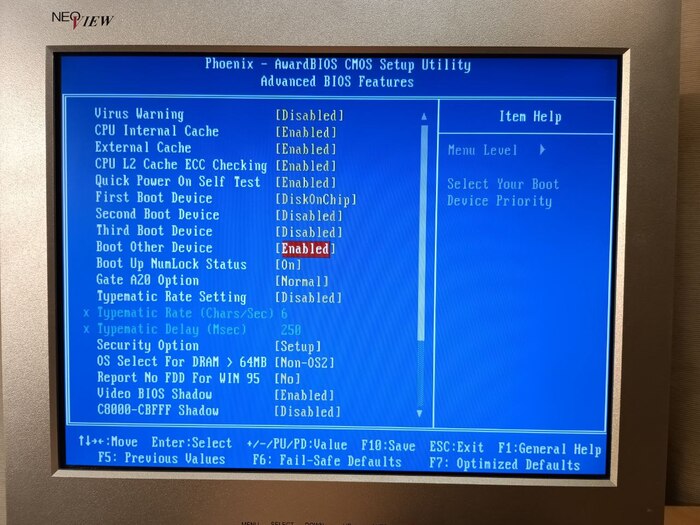
Выбираем в BIOS загрузку с DOC
После всех манипуляций система будет успешно загружена с этой микросхемы, будто бы там установлен обычный жёсткий диск.
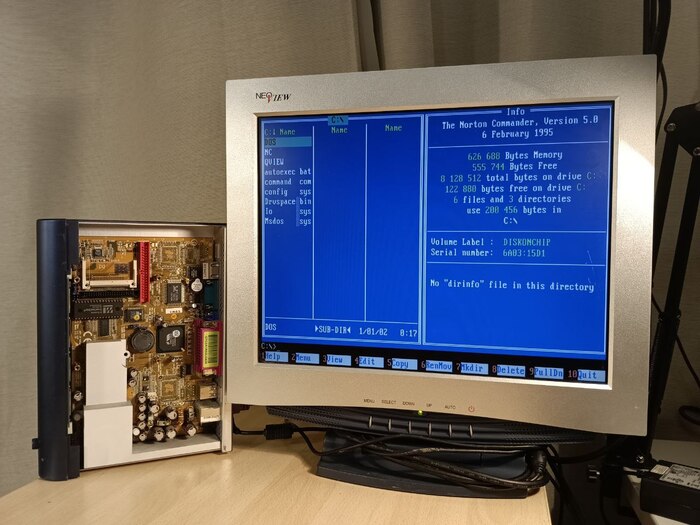
Успешная загрузка тонкого клиента с установленной микросхемы DiskOnChip
❯ Заключение
Удивительно, но многие из вас не знают, что первые SSD-накопители появились аж в 1995 году, и даже вполне себе успешно применялись и использовались. Их высокая стоимость и малая ёмкость привели к тому, что рядовые пользователи не могли встретить их в своих ПК. Однако нашли широкое применение во встраиваемых системах, либо там, где не требуется частая запись на диск, как, например, тонкий клиент. Их могли использовать также в игровых автоматах или станках.

Условный игровой автомат на DiskOnChip
Тем не менее широкого распространения они так и не получили. Впоследствии дешевизна и расширение рынка CompactFlash свели на нет эту перспективную разработку. К её недостаткам также следует отнести, что она довольно медленная, так как работа идёт через маленькое окно в 2 КБ.
❯ Полезные ссылки:
❯ Благодарности:
Выражаю большую благодарность MaFrance351 в поддержке с этим проектом. Он раньше меня разобрался с DOC, и помогал потом мне советами и ссылками. Как минимум половину ссылок в этой статье получил от него.
P.S. Поскольку в рамках одной статьи невозможно рассказать обо всех тонкостях, то некоторые заметки на полях буду публиковать у себя в телеграмме.
Подпишись на наш блог, чтобы не пропустить новые интересные посты!

Ребята в недосягаемости
Первая встреча с ужасных кодом

Идеально

Типичный IT-проект
Когда код заработал
Что за больной на голову это писал?


Я пытался
Иногда обидно

А вы обижаетесь когда ваш код «разносят» на код-ревью?
Ответ на пост «Лайфхак для лентяев»
Работал я в одной компании, которая занимается внедрением некоего программного продукта от российского разработчика. И как-то приходит к нам новый релиз, который мы накатываем некоторым клиентам. Клиенты начинают приходить с одним странным багом. Мы баг изучили, варианты решения предложить не смогли, обратились к разработчику. Разработчик изучив баг пришёл к нам с следующим решением: «Пользователь слишком быстро нажимает на кнопки в системе. Пусть делает это медленнее, программа не успевает за пользователем». А пользователь там не супер быстрая женщина в возрасте.

Тег Юмор не ставлю потому что чёт не смешно.
Истинное удовольствие

И правда, почему?

Спасите — помогите!!
Ситуация такова: сегодня 1 октября с утра, как всегда, решил зайти на Пикабу и меня встретила вот такая картинка:
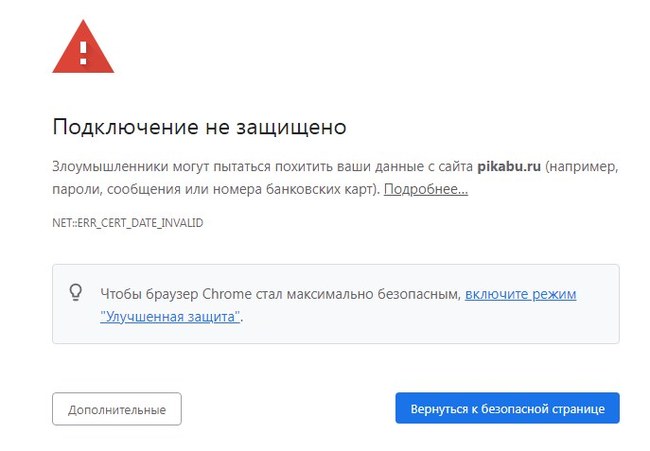
Так же при обращении к другим, некоторым сайтам появляется она.
Если захожу с другово (нового) компа или с телефона — всё нормально работает, понятно что дело именно в моей технике.
Поискал решение в интернете — опробовал практически всё что там описано (снижение уровня безопастности, отключение антивируса. там много чего понаписали) но ничего не помогло. Сейчас зашел на сайт (со старой техники) из под ТОР, но опять — таки не всегда пускает. смена цепочек неоднократная и не всегда помогает.
Браузер — Хром — на старой машине не пускает, на новой — без проблем.
Старый ноут (где проблема) — Вин7.
Другая, беспроблемная техника (чужая) — Вин10 и Андроид.
Вот теперь сижу, думаю — может это они там у себя что-то обновили в тихаря и это уже проблема «железа» на моем старом ноуте?
Пожалуйста, если кто знает — подскажите как это «починить».
Пс картинку поправил
Вон в чем дело, ахренеть. (((
Решение проблемы найдено. Большое спасибо Пикабушнику @Denis.NN — он «легким движением руки» помог мне разобраться с этой проблемой.))
Вот ветка с решением, таким «чайникам» как я может пригодится:

Linkin Park OS и 2000 год
Сегодня был на сайте Linkin Park и случайно забрёл в имитатор старой ОС под браузером. Вышло оригинально. Не ожидал от Linkin Park такого.

UPD. Кто сможет решить квест с паролем (Start -> Settings -> Password)?
Зато потом кайф, когда закрываешь их все разом


Моё расширение для круговых жестов мышью
Всем привет! Хочу рассказать о своем новом расширении для круговых жестов мышью.
Что мне никогда не нравилось в решениях вроде Gesturefy для Firefox или CrxMouse для хрома, так это необходимость запомнить и постоянно держать в уме множество комбинаций и направлений жестов, отчего со временем я неизбежно останавливался на 4-6 базовых и забивал на остальные.
И в то же время мне всегда импонировала концепция визуальных жестов, что-то вроде того как это было реализовано в старой-доброй Opera 12:
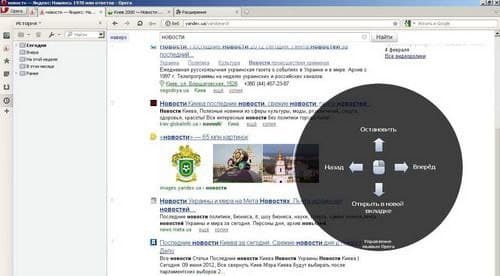
Так что я решил взять за основу концепцию кругового меню, немного её доработать и расширить функциональность. Получилось примерно вот так:
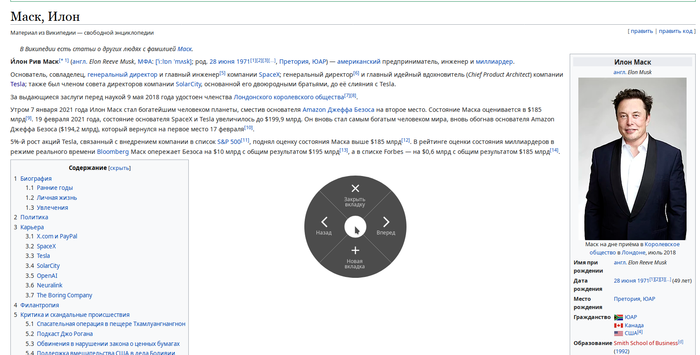
Есть возможность добавить 2-й, и даже 3-ий уровень действий:
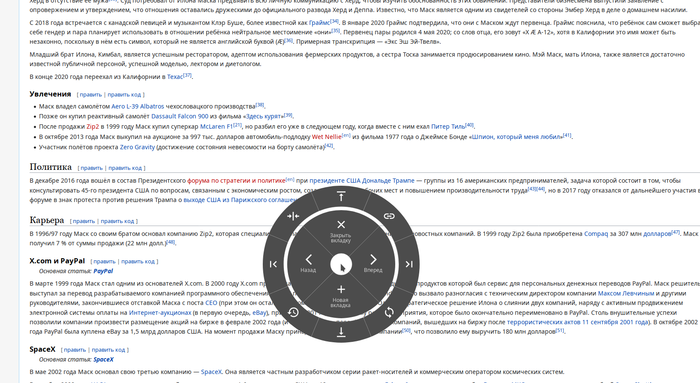
Расширение поддерживает отдельные меню и действия для картинок, ссылок и полей ввода.

Если при отпускании клавиши мыши ни одно действие не было выбрано, то будет вызвано стандартное контекстное меню браузера.
Также в расширении есть множество настроек, включая возможность установить отдельный цвет для каждого уровня и сегмента. Так что при желании можно упороться и замутить себе вот такое развеселое меню 🙂
Баги иногда встречаются, особенно на странице настроек — чиню их по мере наличия времени и возможности. Буду рад услышать ваши отзывы и предложения 🙂
Chrome и хромоподобные браузеры (Edge, Brave, Vivaldi, Яндекс.Браузер и тд):
Проект на GitHub:
Ответ на пост «А когда то и 32 Кбайта считалось роскошью)»
Прочитал пост и вспомнил вот такую историю про Фортран — и про времена, когда деревья были выше, трава зеленее, а программисты всерьёз заботились об оптимизациях.
Как-то раз в бородатом детстве в 1993-ом кажется году мы решили писать компьютерную игрушку и для этого решили сравнить производительность трёх языков, на которых умели писать. Borland C++ 4.0, Turbo Pascal 7.0 и Fortran 77. Тестировались две нужные нам задачи — Умножение вектора на матрицу и отрисовывание треугольника стандартными инструментами в режиме EGA.
Довольно быстро выяснилось, что рисование у C и Pascal шло с одинаковой скоростью, потому как использовало одну и ту же библиотеку egavga.bgi, Расчёты на С были примерно вдвое быстрее, за счёт разнообразных проверок на переполнение, которые в Паскале по умолчанию были включены, а в C по умолчанию выключены. Но это можно было исправить директивами компилятора. А вот с фортраном началось самое интересное:
Первый замер был про умножение на матрицу. Когда фортран показал результат в 10000 раз быстрее у нас закралось подозрение. Сначала мы пытались найти ошибку, но потом сдались. Дизасемблирование показало, что отимизатор смекнул, что результаты вычислений внутри цикла не используются и посчитал умножения и суммирования только один раз, для значения переменной цикла в последнем цикле.
Тогда вместо того чтобы внутри цикла делать просто умножения и сложения мы заставили его ещё и суммировать переменную цикла. Когда фортран показал результаты в 10000 раз быстрее, мы сразу полезли в дизасемблер и к величайшему нашему удивлению обнаружили, что фортран суммирование переменной цикла в цикле успешно заменил на формулу подсчёта арифметической прогрессии. Сказать, что мы были в шоке — ничего не сказать.
Следующие пол часа ушли на подбор такой формулы для замеров, в которой оптимизатор фортрана ничего не смог бы упростить. Задачка оказалось нетривиальной, потому что на глазах у удивлённых школьников фортран выносил общий множитель за скобку, заранее умножал друг на друга константы и делал ещё несколько не менее интеллектуальных операций потрясая наше воображение. Когда мы таки смогли его обмануть выяснилось, что по скорости он от C по скорости не отличается.
Когда мы заставили фортран нарисовать закрашенный треугольник 256 цветами, и он показал результаты ровно в 16 раз лучше egavga.bgi мы уже даже не удивились. В EGA было всего 16 цветов. Рисование цветом 17 было то же самое, что рисование цветом 1. Уж не знаю как Fortran77 дозрел до этой идеи, но он треугольник перерисовал только 16 раз разными цветами, и на этом покинул цикл. Пришлось каждый следующий треугольник рисовать сдвигая одну из вершин на 1 пиксель. Результаты оказались примерно такие же как у конкурентов.
В общем по результатам всей этой истории у меня осталось два выводы:
1) Нет большой разницы на каком из нормальных компиляторов писать, если не лениться.
сколько строчек кода в windows 10
Издание Wired обратило внимание на выступление сотрудницы Google Рейчел Потвин «The Motivation for a Monolithic Codebase», которое состоялось в рамках конференции в Кремниевой долине. В своём докладе она оценила число строк кода, который отвечает за работу всех интернет-сервисов Google: выяснилось, что число равно примерно 2 миллиардам. Если провести некорректное сравнение и учесть, что Windows содержит примерно 50 миллионов строк кода, то получается, что с 1998 года в Google успели написать 40 операционных систем от Microsoft, которая разрабатывается с 1985 года. Мало того, весь этот «Google-код» находится в едином репозитории, которым ежедневно пользуются 25 000 сотрудников поискового гиганта.
Рейчел заметила, что такой принцип хранения исходников позволяет разработчикам Google «… чувствовать необычную свободу в использовании и комбинировании кода других проектов». Единственное существующее ограничение — это доступ к коду, реализующему алгоритмы ранжирования Google’s PageRank, которые являются основой бизнеса, критичного для поискового гиганта. К этим файлам имеют доступ только специально выделенные сотрудники. В целом для управления кодом в Google используется собственная VCS, которая называется Piper и которая в свою очередь опирается на серьёзную инфраструктуру, состоящую из 10 дата-центров.
Любопытна статистика, приведённая Рейчел. По её словам, Piper управляет 85 терабайтами данных «Google-кода», в который ежедневно 25 000 разработчиков делают примерно 40 000 коммитов. Таким образом за каждую неделю модифицируются 250 000 файлов и 15 миллионов строк кода. В сравнении с Linux, которая вся насчитывает примерно 40 000 файлов, работа программистов Google выглядит фантастической.Также Рейчел отметила, что сейчас Google и Facebook вместе работают над новой open source VCS, которую можно будет использовать на проектах любого масштаба, сравнимого даже с самой Google. Интересно, что основой будущей VCS является не модная среди разработчиков git, а Mercurial, которую пытаются масштабировать до уровня, с которым приходится иметь дело обоим интернет-гигантам.
5 причин, по которым я пропущу Windows 11 и еще несколько лет буду пользоваться Windows 10
Через несколько дней, 5 октября 2021 года, состоится релиз новой ОС Windows 11. Еще никогда новая Windows не появлялась так внезапно, 24 июня 2021 года Windows 11 была представлена на мероприятии Microsoft, а уже спустя три с небольшим месяца состоится ее релиз. Это довольно непривычно, ведь мы привыкли, что новые программные продукты приходится ждать довольно долгое время, а их ожидание сопровождается информационной накачкой и рекламой новшеств, которые нас ждут.
реклама
В этот раз все по-другому и на это есть причины, которые я озвучу ниже. Как компьютерный энтузиаст и блогер я всегда с нетерпением ждал выхода новых версий Windows, чтобы рассказать о них читателям, не забыв о критике всех слабых мест и проблем продукта, но к Windows 11 я отношусь скептически. Конечно, я попробую новую ОС и ради эксперимента установлю ее на свой ПК, но на ближайшие несколько лет моей главной ОС останется Windows 10 и на это есть несколько причин.
Вторичность. Windows 11 до последнего момента была лишь большим обновлением Windows 10 Sun Valley
Странные системные требования, сделавшие компьютер, купленный в 2020 году, несовместимым с Windows 11
реклама
В данный момент я пользуюсь компьютером на основе Ryzen 5 1600 AF, материнской платой MSI B450-A PRO MAX и 32 ГБ ОЗУ DDR4 3400 МГц. Покупая эту систему в начале 2021 года, я и подумать не мог, что процессор устареет к концу 2021 года и не будет поддерживать новую Windows. Странные системные требования Windows 11 отсекают от нее большую часть современных ПК и ноутбуков, оставляя пригодными только процессоры Coffee Lake, Zen+ и новее.
реклама
А вот Ryzen 5 2600, подходящий по системным требованиям для Windows 11, стоит заметно дороже.
В «пролете» по системным требованиям оказываются и такие популярные бюджетные процессоры, как Pentium Dual-Core G4560.
реклама
Или одни из самых недорогих процессоров с встроенной графикой, которые позволяют поиграть во многие игры без видеокарты, например, Ryzen 3 2200G.
Неудобство пользовательского интерфейса и вырезание части важных функций
Видимо, Microsoft очень хочет опять попробовать завоевать мобильный рынок, поэтому осуществляет непонятное упрощение пользовательского интерфейса Windows 11, имеющее смысл только для сенсорных экранов, но крайне неудобное для пользователей обычных десктопов, составляющих подавляющее большинство потребителей Windows.
Большинство из нас пользуется сейчас Windows 10, которая прошла долгий путь развития за 6 лет и набрала за этот срок огромное количество новых функций и улучшений, делающих ее удобнее предшественниц. Вместе с этим изменения произошедшие с Windows 10 не столь радикальны и она остается похожей по интерфейсу и части функций на Windows 7 и Windows 8. Пользователь этих старых ОС на Windows 10 может быстро создать привычную среду работы и даже вернуть старое меню Пуск с помощью сторонних утилит.
Отлично показывает себя Windows 10 и в играх, обгоняя Windows 7 в новых проектах и давая более стабильное время кадра во многих старых. Все отлично в Windows 10 и со старыми играми. Я, как и многие из вас, люблю старые игры и большинство из них прекрасно идут на Windows 10, а те которые не запускаются, начинают работать после нескольких тонких настроек или фанатских патчей, как, например, отличная стратегия Majesty 2: The Fantasy Kingdom Sim, не запускающаяся на Windows 8.
Windows 10 для многих из нас стала привычной и удобной средой и чтобы менять ее на что-то новое, нужно что-то большее, чем закругленные углы и меню Пуск, расположенное по центру экрана. В данный момент я пользуюсь Windows 10 October 2020 Update или версией 20H2 и совершенно не вижу причин обновляться даже на May 2021 Update (версия 21H1), не говоря уже о Windows 11. Да, у Windows 10 есть проблемы и я немало критиковал ее в блогах, но с большинством из них пользователи уже научились справляться.
Проблемы новых ОС Windows на старте
Каждый запуск новой Windows сопровождается не только восторженными статьями и новостями, призывающими вас попробовать новинку, но и более сдержанными сообщениями о новых проблемах, иногда серьезных. Это естественно при запуске нового продукта и пользователи, успевшие попробовать предварительные версии Windows 11 уже пишут о падении производительности, проседании кадровой частоты системных анимаций и их задержке и многих других проблемах.
Среди пользователей Windows раньше ходила поговорка, что переходить на новую ОС стоит только после выхода второго Service Pack. С тех пор много изменилось, исчезли сами Service Pack, превратившись в бесконечную череду обновлений, заметно больше стало багов в обновлениях, но в целом поговорка не утратила смысла и не стоит бросаться на новое, становясь бета-тестером.
Итоги
Вот мои пять причин, по которым я остаюсь на старой доброй Windows 10 еще несколько лет, пока не закончится ее поддержка. А что думаете по поводу Windows 11 вы? Пишите в комментарии, подходит ли ваш ПК для нее по системным требованиям и будете ли вы переходить на нее?
Система STEPS: двадцать тысяч строк кода, которые изменят программирование, операционные системы и интернет
У программистов есть заветная мечта: взять и переделать заново всё — операционную систему, языки программирования, библиотеки и приложения. Упразднить ненужное дублирование функций и написать всё красиво и по-новому — словом, сделать всё как надо, а не как получилось в результате многих лет нагромождения разных стилей и технологий. При этом все обычно понимают, что мечтам никогда не сбыться и что никому не под силу заново проделать такой объём работы. Над смельчаками принято посмеиваться, а их попытки — обзывать переизобретением колеса. Но когда за работу берётся человек, который уже однажды изобрёл немалую часть технологий, которые мы ассоциируем с персональными компьютерами, все шутки становятся неуместными.
Алан Кей — живая легенда компьютерной индустрии. В середине шестидесятых он работал с Айвеном Сазерлендом, создавшим первый графический редактор и систему автоматизированного проектирования, а в 1970 году присоединился к исследовательской лаборатории Xerox PARC, где придумал объектно-ориентированное программирование, создав язык Smalltalk, и первый компьютер с оконным графическим интерфейсом. Позднее его работа вдохновит Стива Джобса и команду, сделавшую Macintosh, а прототип Macintosh убедит Билла Гейтса в том, что MS-DOS срочно нуждается в графической оболочке с оконным интерфейсом, известной нам как Windows.
После PARC Кей работал в самых разных исследовательских центрах: Atari, Apple, Disney и HP, а также в Калифорнийском университете в Лос-Анджелесе и Киотском университете. Видимым результатом его исследований стали Squeak — более современная и дружественная версия Smalltalk, а также Etoys — вариант Squeak для детей (на его основе был создан более известный сегодня Scratch). В 2005 году Кей основал исследовательский институт Viewpoints, финансируемый Национальным научным фондом США, а также рядом крупных компаний: Intel, Motorola, HP и Nokia. То, чем Кей и десяток сотрудников Viewpoints заняты сейчас, может ещё перевернуть наш взгляд на программирование.
Двадцати тысяч строк хватит на всё
Изначальное предложение Кея, представленное Национальному научному фонду США, звучало не просто смело, а почти фантастически. Кей пообещал создать среду (мы не будем называть её операционной системой, так как Кей настаивает на том, что это не ОС в привычном понимании), которая позволит функционировать современному компьютеру и будет включать в себя графический пользовательский интерфейс и набор прикладных программ. Главное отличие этой среды от всех уже существующих решений: длина кода этой системы не будет превышать двадцати тысяч строк.
Сказать, что двадцать тысяч строк — это немного, значит не сказать ничего. Если верить «Википедии», то исходные коды Windows NT 3.1 занимали 4-5 миллионов строк кода, ядро Linux 2.6.0 − 5,2 миллиона, а современные ОС с набором стандартных приложений могут содержать сотни миллионов строк кода.
Объём сопоставим с Эмпайр стейт билдинг и равен примерно 17,5 тысячам книг. «Кто из вас прочёл семнадцать тысяч книг? — вопрошает Кей собравшихся на лекции. — А кто из вас прочёл хотя бы одну?» Объёма одной книги, то есть примерно двадцати тысяч строк, по его мнению достаточно для того, чтобы создать систему, напоминающую по функциям те ОС и приложения, с которыми мы сейчас работаем. Просто строить нужно умело.
Современный софт Кей сравнивает с египетскими пирамидами. Их строители ещё ничего толком не знали об архитектуре и сооружали конструкции, которые почти полностью состояли из материала и практически не имели свободного пространства внутри. С изобретением колонн и арок стало возможно возводить куда более изящные и практичные сооружения. Нельзя ли изобрести аналог арок для написания программ?
Сейчас программист при всём желании не способен свободно ориентироваться в миллионах строк кода. Зато если уместить всю систему в объём книги и разделить на логические части по 100-1000 строк, это даст возможность легко понимать логику её строения и вносить изменения. Проблемы вроде багов, которые на протяжении многих лет преследуют крупные проекты, просто уйдут в прошлое.
You may say I’m a dreamer
Главный вопрос: возможно ли такое в принципе? За пять лет работы команда Кея доказала, что ответ на этот вопрос может быть положительным. Систему методов, которые позволят это сделать, авторы называют STEPS. Это рекурсивный акроним, расшифровывающийся как STEPS Toward Expressive Programming Systems — «Шаги к выразительным системам программирования».
Руководствуясь принципами STEPS, в институте Кея создали прототип системы. Он называется Frank, а если полностью — «Франкенштейн». Такое имя выбрано не зря: система составлена из кусочков, каждый из которых ещё может быть заменён или переписан заново.
Что может делать пользователь Frank? Всё то же, что мы обычно делаем за компьютером: создаём и редактируем текстовые документы, графику, видео, презентации и электронные таблицы, а также обмениваемся ими через сеть. Вся разница в том, что исследователи попытались полностью избавились от дублирования функций разными программами и максимально сократить исходный код.
Frank — это не операционная система, в которой работают приложения, а скорее, подобие Smalltalk или Squeak — большое приложение, которое можно расширять и дополнять, пока оно не станет делать всё, что нам нужно. Вместо приложений, в которых реализованы собственный интерфейс и функции, здесь присутствуют компоненты, имеющие сложные взаимосвязи.
Во Frank есть единое понятие «документ», в который могут быть включены и на месте изменены любые объекты, будь то изображения, таблицы или созданные пользователем скрипты. Презентация, например, — это документ, включающий в себя сценарий перехода вперёд и назад по страницам (или, если угодно, кадрам), а не файл, для открытия которого требуется специальная программа. Такая программа просто не нужна, потому что интерфейс для работы с изображениями и текстом идентичен тому, что используется для подготовки других документов.
То же и с электронной почтой: письмом во Frank считается любой документ, который был передан по Сети. Список писем — это результат поиска документов, полученных от других пользователей.
Ещё одно ценное качество системы Кея — универсальная отмена. Здесь может быть отменено действительно любое действие, а не как в сегодняшних программах — лишь некоторые, да и то не всегда. Для этого используется механизм «миров»: каждый раз, когда мы что-то меняем, система может запомнить, чем нынешний «мир» отличается от предыдущего, и в случае надобности вернуть всё, как было.
Интереснее всего то, как Кей предлагает переделать веб. Во Frank нет браузера, зато есть поддержка протокола TCP/IP (его код занимает 160 строк, и это, по словам Кея, не предел краткости). Вместо веб-страниц предлагается использовать те же самые документы, добавив в них объект нового типа — гиперссылку.
Поскольку код, содержащийся в документах, по сути, работает в виртуальной машине, это делает их загрузку извне не менее безопасной, чем исполнение JavaScript браузером. Получается, что объекты-страницы просто подгружаются через Сеть по мере необходимости. Кстати, делать такие «сайты» намного проще, чем обычные: можно пользоваться уже имеющимися в системе средствами — теми же самыми, при помощи которых редактируются текстовые документы, презентации и всё остальное.
Сила мысли и никакого мошенничества
Внешняя сторона Frank интересна уже хотя бы в качестве примера унифицированной среды, в которой нет ни разделения на приложения, ни традиционной файловой системы. Но настоящая чёрная программисткая магия скрыта внутри.
Сколько занимают разные части STEPS?
| TCP/IP | 160 строк |
| Алгоритм сглаживания на Nile | 45 строк |
| Весь код Gezira на Nile | 457 строк |
| Парсер Nile на OMeta | 130 строк |
| Транслятор Nile AST в Си на OMeta | 1110 строк |
Как Frank уместился в двадцать тысяч строк кода? Ответ кроется за двумя терминами: метапрограммирование и предметно-ориентированные языки (DSL). Главная идея заключается в том, чтобы создавать языки под конкретные задачи и, хитроумно комбинируя их, писать элегантные и короткие программы. Эта идея не нова: на ней основан язык Forth, и она используется в написании программ на языке Lisp, которым Кей в своё время вдохновлялся при создании Smalltalk. Более современный пример — фреймворк Ruby on Rails, применяемый в качестве DSL для разработки бэкэндов веб-приложений. Но STEPS — это нечто куда большее, чем один язык, — это набор методов и языков, при помощи которых можно создавать сложные системы, используя минимум кода.
Один из самых интересных компонентов STEPS — это объектно-ориентированный язык OMeta (pdf). Он предназначен для описания синтаксиса других языков. К примеру, на OMeta можно в несколько строк описать синтаксис калькулятора, а потом при помощи наследования расширить его и сделать научный калькулятор. Синтаксис OMeta при этом описан на самом OMeta.
Второй важный язык — это Nile (названный в честь реки Нил). Авторы STEPS называют его «языком исполняемой математики». Nile позволяет компактно описывать математические выражения и сделан таким образом, чтобы максимально облегчить параллельные вычисления. На нём написана графическая подсистема Frank, называемая Gezira. Gezira умещается в несколько сотен строк на Nile и умеет выводить растровую и векторную графику, поддерживает сглаживание и различные фильтры.
Самый низкий уровень во всей этой сложной системе — язык Nothing (переводится с английского как «Ничто»), «высокоуровневый язык с низкоуровневой семантикой». Nothing — это промежуточное звено между всеми языками в STEPS и машинными кодами. На Nothing не предполагается писать вручную, и нужен он лишь для возможности смотреть, что получается на выходе. Nothing, по словам исследователей, вдохновлён BCPL, использовавшимся в шестидесятые годы и вдохновившим авторов Си. На данный момент код на Nothing можно транслировать в Си для дальнейшего перевода в машинные коды или в JavaScript — чтобы система исполнялась в браузере. Предполагается, что в будущем из Nothing можно будет получать машинные коды напрямую.
В качестве промежуточного слоя, на котором написан пользовательский интерфейс, одно время использовался NotSqueak — упрощённый диалект Squeak. Но в последнем отчёте упоминаний о NotSqueak уже нет, зато появился новый объектно-ориентированный язык — Maru. Как и OMeta, он написан сам на себе и может использоваться как для описания высокоуровневого представления, так и для связи с низкоуровневыми функциями. На Maru может быть реализован парсер грамматики, и в 2011 году команда Кея была занята переносом Nile на Maru.
Бесконечный эксперимент
К сожалению, отчёты Кея и его команды (pdf) — это не пособие для программистов-суперменов и не справочник. Оно и понятно — STEPS пока что не готов, и каждый год во Viewpoints ставят разнообразные эксперименты, цель которых — не столько в создании законченной системы, сколько в том, чтобы отточить методы. «Франкенштейн» как цельная система здесь нужен лишь в качестве подопытного тела.
Если посмотреть отчёты Viewpoints за разные годы, то заметно, что здесь снова и снова изобретают языки программирования, делают их всё более самодостаточными (пока что кое-где ещё остаётся код на Си, но от него постепенно избавляются) и ставят смелые эксперименты.
Время от времени команда Кея пробует пробрасывать мостики в реальный мир, создавая, к примеру, виртуальную машину Squeak для Google Native Client или делая метаязык Tamacola на основе Tamarin VM, входящей во Flash. Эти методы могут позволить всей системе не просто работать в браузере, но исполняться быстрее, чем при трансляции в JavaScript.
Скорость, впрочем, не является целью Кея: по его оценке, в нынешнем виде Frank работает примерно на 30 процентов медленнее, чем если бы был написан традиционными методами. Оптимизацией исследователи занимаются лишь тогда, когда это не вредит компактности кода.
Понятно, что Frank не станет конкурентом современных ОС и вряд ли вообще будет доделан до необходимого для этого уровня. Тем не менее те методы, которые разрабатывает Алан Кей, могут повлиять на подход к программированию не меньше, чем в своё время повлиял Smalltalk.
Кто из вас сколько строк кода пишет в день?
Вот давайте обсудим эту тему. Вот мне интересно сколько именно кода в день программисты пишут. Интересуют все и любители и профи и те кто этим деньги зарабатывает.
Интересует сам объем дневной работы.
Свое количество я напишу позже.
Только я надеюсь вы не считаете строчки вручную;)
Производительность программиста НЕ измеряется количеством написанного кода в день.
Ну разве что у Индусов только.
Я спрашивал не про производительность программиста. А просто про среднее число полезных строк. То есть среднее комфортное число строк которые программист может набить в день не стремясь выполнить План или успеть к сроку, который прошел вчера.
Вот я в день в среднем набиваю от 50 строк чистого кода, иногда при особом вдохновении (у правильном проектировании, если лень не победит) до 100 строк. Я никуда не спешу. И я не работаю программистом. Думаю у профи всеже больше результат. Но на мои проекты этого достаточно. А вот всего пять месяцев назад мне хватало от силы на 30-40 строк, да и то с копипастой (благодаря конкурсу стратегий я научился набивать много полезного кода)
Это вопрос из разряда:
Товарищи водители, кто из вас сколько раз нажимает на газ в день?
Чем больше кода пишет программист, тем более он говняный.
warchief
количество строк не очень характеристика имхо
все ведь зависит от
1) качество кода, говнокодить можно и по 100500 строк в день
2) возможностей среды, с использованием таких средств как Resharper и тп можно и 100500 строк качественного кода бить
3) синтаксиса языка, без комментариев )
4) можно ведь и считать по разному,
программист в очень редких случаях выдает прям без ошибочно большие блоки кода (имхо),
можно ведь вбить блок и весь день его править/дебажить/рефакторить набирая и стирая при этом очень много кода )
за вторую неделю не написал ни одной строки, так как сейчас идет стадия сетапа
к стати в идеальном случае использования шаблонов со всякими стратегиями в конце проекта пишут чаще не код а typedef’ы
warchief
Не подходящий вопрос для пятницы ��
Придется ждать понедельника, чтобы добраться до проекта, и поделить строки на дни.
Но вообще вопрос был не сколько максимально кода вы набиваете, а ваш средний показатель, сглаженный теоретическими измышлениями, правками, поисками вредного бага, лазанью по форумам и просто пуляниями бумажных самолетиков:)
Оценка проделанной работы за день у программиста, как оценить?
Норма выработки по информации коммита(new files, changed, insertions, deletions). Так я на данный момент оцениваю проделанную работу.
В день входит в коммит примерно:
Файлов конечно меньше обычно, сегодня день такой был.
Мне интересно на сколько это много? Какая норма у других? У вас? Какая должна быть? Когда много, мало, и нормально? Цифры? Есть возможно статистика? И какие есть еще варианты оценить обьем проделанной работы за день? Бывает пишешь фичу, кода много, а фичи еще нет.


я занимался реструктуризацией сегодня

Сколько тасков закрыто, из тех что были запланированы с утра
Сколько тасков до конца спринта / недели из того что выставил ПМ
Проведены ли все согласования, которые нужны для тасков на завтра
Учёт строк должен проводиться по распечатанному «git diff» или специально написанными для этого утилитами.
При описанной мной системе программист будет мотивирован:
1) больше писать рабочего кода, меньше плодить абстракции и витать в облаках
2) стараться проводить больше времени в офисе
3) брать «горячие» задания и выполнять их как можно быстрее
4) не бояться остаться без денег (актуально для новичков).
Все цифры приведены примерно и должны подбираться экспериментально конкретно для вашей ситуации.
Сколько строк кода в windows 10
В октябре 2013 года мы разместили на Weibo картинку (@ programmer’s things) инфограмма " Сравнение кодовых баз известных программных систем.
В инфографике упоминается, что объем кода для операционных систем Windows XP и Windows 7 составляет около 40 миллионов строк.

( инфограмма Несколько скриншотов, полная версия здесь: http: //t.cn/EXMs07e )
Windows Объем исходного кода Vista составляет около 50 миллионов строк.
Следовательно, объем исходного кода Windows 10 составляет не менее 50 миллионов строк.
Какой язык программирования использовался при разработке операционной системы Windows?
Windows операционная система Кому-то должно быть интересно, какой язык программирования используется для такой масштабной кодовой базы.
Это правда? Кто-то написал на Quora с вопросом: «Разработка W ind ows 10 Какой язык программирования используется? 》
В марте 2019 года инженер ядра Microsoft Аксель Ритчин ответил на этот пост на Quora.
«Вот что о программистах»:
Axel Говорят, что Windows 10 и Windows 8.x, 7, Vista, XP, 2000 и NT имеют одинаковую кодовую базу. Каждое поколение операционных систем претерпело серьезный рефакторинг, добавив большое количество новых функций, улучшив производительность и поддержку оборудования. И безопасность при сохранении очень высокой обратной совместимости.
Ядро (ntoskrnl.exe) Большинство из них написано на языке Си . Вы можете найти просочившуюся версию Windows Research Kernel на Github.
Детскую обувь, кому интересно, могут посмотреть: github.com/markjandrews/wrk-v1.2
Axel Сказал, что, хотя код WRK устарел и в основном неполный, он должен дать вам некоторое представление.
Например: каталог wrk-v1.2 / base / ntos / config — это исходный код известного реестра (Registry) .Этот компонент ядра является диспетчером конфигурации (CM).
Большинство программ, работающих в режиме ядра, также написаны на языке C. (Большинство файловых систем, сетей, большинство драйверов . ) и немного C ++.
Что касается языка программирования, на котором написано Window 10, Аксель считает, что это C и C ++, причем C составляет большинство.
.NET BCL И другие управляемые библиотеки и фреймворки обычно используют C # Написано, Из разных отделов ( Отдел разработчиков) И не принадлежит Windows Исходное дерево 。 По сравнению с океаном кода C, разбросанным по островам C ++, код, написанный на C #, — просто капля в море. 。
Windows действительно правда В самом деле В самом деле В самом деле Очень большой
Axel Я напоминаю всем, что большинство людей не осознают огромных размеров системы Windows, огромного проекта с эпическим масштабом.
Размер полного дерева исходного кода Windows (включая все коды, тестовые коды и т. Д.) Превышает 0,5 ТБ, что включает Более 56 миллионов папок, 400 Более десяти тысяч файлов 。
Вы можете потратить год, копаясь в дереве исходных текстов и копаясь в этих файлах. Они включают в себя все компоненты рабочей станции и серверных продуктов ОС, а также все их версии, инструменты и соответствующие комплекты разработки.
Затем вы снова читаете имя файла, чтобы увидеть, что в нем и для чего они используются. Хочу закончить эти дела , Персона (Или два человека ) Боюсь закончить жизнь 。
один раз Axel Покинув ветку Git на несколько недель, он вернулся и обнаружил, что за ним почти 60 000 коммитов. Axel Я думаю, кто-то сказал бы, что никто не может читать весь код, добавленный в Windows каждый день, не говоря уже о том, чтобы читать код, написанный за последние 30 лет!
Рекомендуемая литература
(Щелкните заголовок, чтобы перейти к прочтению)
Обратите внимание на звезду "вещи программиста" и не пропустите кружок.
Строки исходного кода — Source lines of code
Строки исходного кода (SLOC ), также известные как строки код (LOC ) — это метрика программного обеспечения, используемая для измерения размера компьютерной программы путем подсчета количества строк в тексте исходный код программы . SLOC обычно используется для прогнозирования объема усилий, которые потребуются для разработки программы, а также для оценки продуктивности программирования или ремонтопригодности после создания программного обеспечения.
Содержание
- 1 Методы измерения
- 2 Истоки
- 3 Использование показателей SLOC
- 3.1 Пример
- 4.1 Преимущества
- 4.2 Недостатки
Методы измерения
Многие полезные сравнения включают только порядок величины строк кода в проекте. Использование строк кода для сравнения проекта из 10 000 строк и проекта из 100 000 строк намного полезнее, чем при сравнении проекта из 20 000 строк и проекта из 21 000 строк. Хотя вопрос о том, как именно измерять строки кода, является спорным, расхождения порядка величины могут быть четкими индикаторами сложности программного обеспечения или человеко-часов.
Существует два основных типа показателей SLOC: физический SLOC (LOC) и логический SLOC (LLOC). Конкретные определения этих двух показателей различаются, но наиболее распространенное определение физического SLOC — это количество строк в тексте исходного кода программы, исключая строки комментариев.
Логический SLOC пытается измерить количество исполняемых «операторов» «, но их конкретные определения привязаны к конкретным компьютерным языкам (одна простая логическая мера SLOC для C -подобных языков программирования — это количество точек с запятой в конце оператора). Намного проще создавать инструменты для измерения физического SLOC, а определения физических SLOC легче объяснить. Однако физические показатели SLOC чувствительны к логически несущественным соглашениям о форматировании и стилях, в то время как логический SLOC менее чувствителен к соглашениям о форматировании и стилях. Однако меры SLOC часто указываются без их определения, и логический SLOC часто может значительно отличаться от физического SLOC.
Рассмотрим этот фрагмент кода C как пример неоднозначности, возникающей при определении SLOC:
В этом примере мы имеем:
- 1 физическая строка кода (LOC),
- 2 логические строки кода (LLOC) (для оператора и printf statement),
- 1 строка комментария.
В зависимости от программиста и стандартов кодирования, указанная выше «строка кода» может быть записана на многих отдельных строках:
В этом примере мы имеем:
- 4 физических строки кода (LOC): нужно ли расставить фигурные скобки для оценки работы?
- 2 логических строки кода (LLOC): как насчет всей работы, написанной без инструкций строки?
- 1 строка комментария: инструменты должны учитывать весь код и комментарии, независимо от их размещения.
Даже «логические» и «физические» значения SLOC могут иметь большое количество различных определений. Роберт Э. Парк (находясь в Институте программной инженерии ) и другие разработали фреймворк для определения значений SLOC, чтобы люди могли подробно объяснить и определить меру SLOC, используемую в проекте. Например, большинство программных систем повторно используют код, и определение того, какой (если есть) повторно используемый код включить, важно при составлении отчета о показателе.
Происхождение
В то время, когда люди начали использовать SLOC в качестве метрики, наиболее часто используемые языки, такие как FORTRAN и язык ассемблера, были строчно-ориентированными языками. Эти языки были разработаны в то время, когда перфокарты были основной формой ввода данных для программирования. Одна перфокарта обычно представляет собой одну строку кода. Это был один дискретный объект, который легко пересчитать. Это был видимый результат работы программиста, поэтому менеджерам было разумно считать строки кода мерой производительности программиста, даже имея в виду такие, как «изображения карточек ». Сегодня наиболее часто используемые компьютерные языки предоставляют гораздо больше возможностей для форматирования. Текстовые строки больше не ограничены 80 или 96 столбцами, и одна строка текста больше не обязательно соответствует одной строке кода.
Использование мер SLOC
Меры SLOC несколько спорны, особенно в том смысле, что они иногда используются не по назначению. Эксперименты неоднократно подтверждали, что усилия сильно коррелируют с SLOC, то есть программы с более высокими значениями SLOC требуют больше времени для разработки. Таким образом, SLOC может быть эффективным при оценке усилий. Однако функциональность хуже коррелирует с SLOC: опытные разработчики могут разработать ту же функциональность с гораздо меньшим количеством кода, поэтому одна программа с меньшим количеством SLOC может демонстрировать больше функциональности, чем другая аналогичная программа. Подсчет SLOC как показателя производительности имеет свои недостатки, поскольку разработчик может разработать только несколько строк и при этом быть гораздо более продуктивным с точки зрения функциональности, чем разработчик, который в конечном итоге создает больше строк (и обычно затрачивает больше усилий). Хорошие разработчики могут объединить несколько модулей кода в один модуль, улучшая систему, но при этом снижая производительность, поскольку они удаляют код. Кроме того, неопытные разработчики часто прибегают к дублированию кода, что крайне не рекомендуется, поскольку оно более подвержено ошибкам и требует больших затрат на обслуживание, но приводит к более высокому SLOC.
Подсчет SLOC вызывает дополнительные проблемы с точностью при сравнении программ, написанных на разных языках, если не применяются поправочные коэффициенты для нормализации языков. Различные компьютерные языки по-разному уравновешивают краткость и ясность; В качестве крайнего примера, большинству языков ассемблера потребовались бы сотни строк кода для выполнения той же задачи, что и несколько символов в APL. В следующем примере показано сравнение программы «hello world», написанной на C, и той же программы, написанной на COBOL — языке, который известен своей особенно многословностью..
C COBOL Строки кода: 4. (без пробелов) Строки кода: 6. (без пробелов) Другой все более распространенной проблемой при сравнении показателей SLOC является разница между автоматическими сгенерированный и рукописный код. Современные программные инструменты часто имеют возможность автоматически генерировать огромные объемы кода с помощью нескольких щелчков мыши. Например, построители графического интерфейса пользователя автоматически генерируют весь исходный код для графических элементов управления, просто перетаскивая значок в рабочее пространство. Работа, связанная с созданием этого кода, не может разумно сравниваться с работой, необходимой, например, для написания драйвера устройства. Точно так же созданный вручную пользовательский класс GUI может быть более требовательным, чем простой драйвер устройства; отсюда и недостаток этой метрики.
Существует несколько моделей оценки затрат, расписания и трудозатрат, которые используют SLOC в качестве входного параметра, включая широко используемую серию моделей Конструктивной модели затрат (COCOMO ) от Барри Боэма. и др., PRICE Systems и SEER-SEM Галората. Несмотря на то, что эти модели продемонстрировали хорошую предсказательную силу, они хороши ровно настолько, насколько хороши оценки (в частности, оценки SLOC), предоставленные им. Многие выступали за использование функциональных точек вместо SLOC в качестве меры функциональности, но, поскольку функциональные точки сильно коррелированы с SLOC (и не могут быть измерены автоматически), это не универсальная точка зрения.
Пример
По словам Винсента Мараиа, значения SLOC для различных операционных систем в линейке продуктов Microsoft Windows NT следующие:
Год Операционная система SLOC (млн) 1993 Windows NT 3.1 4–5 1994 Windows NT 3.5 7–8 1996 Windows NT 4.0 11–12 2000 Windows 2000 более 29 2001 Windows XP 45 2003 Windows Server 2003 50 Дэвид А. Уилер изучил Red Hat дистрибутив операционной системы Linux и сообщил, что Red Hat Linux версии 7.1 (выпущенной в апреле 2001 г.) содержит более 30 миллионов физических SLOC. Он также экстраполировал, что, если бы он был разработан обычными собственными средствами, он потребовал бы около 8000 человеко-лет усилий и стоил бы более 1 миллиарда долларов (в долларах США 2000 года).
Позднее аналогичное исследование было проведено для Debian GNU / Linux версии 2.2 (также известного как «Potato»); эта операционная система была первоначально выпущена в августе 2000 года. Это исследование показало, что Debian GNU / Linux 2.2 включает более 55 миллионов SLOC, и, если бы разработка производилась обычным закрытым способом, потребовалось бы 14 005 человеко-лет и 1,9 миллиарда долларов США на разработку. Более поздние прогоны использованных инструментов сообщают, что в следующем выпуске Debian было 104 миллиона SLOC, а по состоянию на 2005 год последний выпуск будет включать более 213 миллионов SLOC.
Год Операционная система SLOC (млн) 2000 Debian 2.2 55–59 2002 Debian 3.0 104 2005 Debian 3.1 215 2007 Debian 4.0 283 2009 Debian 5.0 324 2012 Debian 7.0 419 2009 OpenSolaris 9.7 FreeBSD 8.8 2005 Mac OS X 10.4 86 1991 ядро Linux 0,01 0,010239 2001 Linux ядро 2.4.2 2.4 2003 ядро Linux 2.6.0 5.2 2009 ядро Linux 2.6. 29 11.0 2009 ядро Linux 2.6.32 12.6 2010 ядро Linux 2.6.35 13,5 2012 Ядро Linux 3,6 15,9 2015-06-30 Ядро Linux до 4.2 20,2 Утилита
Преимущества
- Возможности для автоматизации подсчета: поскольку строка кода является физическим объектом, ручные подсчеты можно легко исключить, автоматизируя процесс подсчета. Для подсчета LOC в программе могут быть разработаны небольшие утилиты. Однако утилита подсчета логического кода, разработанная для конкретного языка, не может использоваться для других языков из-за синтаксических и структурных различий между языками. Однако были созданы физические счетчики LOC, которые учитывают десятки языков.
- Интуитивная метрика: строка кода служит интуитивной метрикой для измерения размера программного обеспечения, потому что ее можно увидеть, и эффект от нее можно визуализировать. Функциональные точки считаются более объективной метрикой, которую нельзя представить как физическую сущность, она существует только в логическом пространстве. Таким образом, LOC пригодится программистам с низким уровнем опыта, чтобы выразить размер программного обеспечения.
- Повсеместная мера: Меры LOC используются с первых дней появления программного обеспечения. Таким образом, можно утверждать, что доступно больше данных LOC, чем любой другой показатель размера.
Недостатки
- Отсутствие подотчетности: измерение строк кода страдает некоторыми фундаментальными проблемами. Некоторые думают, что бесполезно измерять продуктивность проекта, используя только результаты этапа кодирования, на который обычно приходится от 30% до 35% общих усилий.
- Отсутствие согласованности с функциональностью: хотя эксперименты неоднократно подтверждали, что, хотя усилия сильно коррелируют с LOC, функциональность хуже коррелирует с LOC. То есть опытные разработчики могут разработать ту же функциональность с гораздо меньшим количеством кода, поэтому одна программа с меньшим LOC может демонстрировать большую функциональность, чем другая аналогичная программа. В частности, LOC является плохим показателем производительности отдельных людей, потому что разработчик, который разрабатывает только несколько строк, может быть более продуктивным, чем разработчик, создающий больше строк кода — даже больше: некоторый хороший рефакторинг, такой как «метод извлечения», чтобы избавиться от избыточный код и поддержание его в чистоте в основном уменьшит количество строк кода.
- Неблагоприятное влияние на оценку: из-за факта, представленного в пункте 1, оценки, основанные на строках кода, могут отрицательно сказаться на неверно, по всей вероятности.
- Опыт разработчика: реализация конкретной логики зависит от уровня опыта разработчика. Следовательно, количество строк кода отличается от человека к человеку. Опытный разработчик может реализовать определенные функции в меньшем количестве строк кода, чем другой разработчик с относительно меньшим опытом, хотя они используют тот же язык.
- Разница в языках: рассмотрим два приложения, которые предоставляют одинаковые функции (экраны, отчеты, базы данных). Одно из приложений написано на C ++, а другое — на таком языке, как COBOL. Количество функциональных точек будет точно таким же, но аспекты приложения будут другими. Строки кода, необходимые для разработки приложения, определенно не будут такими же. Как следствие, количество усилий, необходимых для разработки приложения, будет другим (часов на функциональную точку). В отличие от строк кода, количество функциональных точек останется постоянным.
- Появление инструментов GUI : с появлением языков программирования и инструментов на основе GUI, таких как Visual Basic, программисты могут писать относительно небольшой код и достигать высоких уровней функциональности. Например, вместо написания программы для создания окна и рисования кнопки пользователь с графическим интерфейсом пользователя может использовать перетаскивание и другие операции с мышью для размещения компонентов в рабочей области. Код, который автоматически генерируется инструментом GUI, обычно не учитывается при использовании методов измерения LOC. Это приводит к различиям между языками; та же задача, которая может быть выполнена в одной строке кода (или вообще без кода) на одном языке, может потребовать нескольких строк кода на другом.
- Проблемы с несколькими языками: в сегодняшнем сценарии программного обеспечения программное обеспечение часто разрабатывается более чем на одном языке. Очень часто используется несколько языков в зависимости от сложности и требований. Отслеживание и отчетность о производительности и количестве дефектов представляет собой серьезную проблему в этом случае, поскольку дефекты не могут быть отнесены к конкретному языку после интеграции системы. Функциональная точка оказывается лучшим средством измерения размера в этом случае.
- Отсутствие стандартов подсчета: нет стандартного определения того, что такое строка кода. Учитываются ли комментарии? Включены ли декларации данных? Что произойдет, если оператор занимает несколько строк? — Это вопросы, которые часто возникают. Хотя такие организации, как SEI и IEEE, опубликовали некоторые руководящие принципы в попытке стандартизировать подсчет, их трудно применить на практике, особенно в связи с тем, что каждый год появляются все новые и новые языки.
- Психология: программист, чей производительность измеряется в строках кода, будет стимул писать излишне подробный код. Чем больше руководство сосредотачивается на строках кода, тем больше у программиста стимула расширять свой код ненужной сложностью. Это нежелательно, поскольку повышенная сложность может привести к увеличению затрат на обслуживание и увеличению усилий, необходимых для исправления ошибок.
В документальном фильме PBS Triumph of the Nerds руководитель Microsoft Стив Баллмер раскритиковал использование подсчета строк кода:
В IBM есть религия в программном обеспечении, которая гласит, что нужно считать K-LOC, а K-LOC — это тысяча строк кода. Насколько велик проект? О, это своего рода проект 10K-LOC. Это 20K-LOCer. А это 50K-LOC. И IBM хотела стать религией в отношении того, как нам платят. Сколько денег мы заработали на OS / 2, сколько они сделали. Сколько K-LOC вы сделали? И мы продолжали убеждать их — эй, если у нас есть — у разработчика есть хорошая идея, и он может что-то сделать в 4K-LOC вместо 20K-LOC, должны ли мы зарабатывать меньше денег? Потому что он сделал что-то меньшее и быстрое, без K-LOC. K-LOCs, K-LOCs, это методология. Ух! В любом случае, от этой мысли у меня всегда морщится спина.
Когда, если когда-либо, "количество строк кода" является полезной метрикой?
ps: Обратите внимание, что когда такие утверждения сделаны, тон «больше лучше».
ОТВЕТЫ
Ответ 1
Я бы сказал, когда вы удаляете код, чтобы проект работал лучше.
Говорить, что вы удалили «X количество строк», впечатляет. И гораздо более полезно, чем вы добавили строки кода.
Ответ 2
Я удивлен, что никто не упомянул знаменитую цитату Дейкстры, поэтому здесь идет:
Сегодня моя точка зрения заключается в том, что, если мы хотим подсчитать строки кода, мы не должны рассматривать их как «линии, созданные», а как «потраченные строки»: существующая общепринятая мудрость настолько глупа, что книга рассчитана на неправильные стороне книги.
Ответ 3
Это ужасная метрика, но, как отметили другие люди, она дает вам (очень) грубую идею общей сложности системы. Если вы сравниваете два проекта: A и B и A — 10 000 строк кода, а B — 20 000, это не говорит вам о многом — проект B может быть чрезмерно подробным, или может быть суперсжато.
С другой стороны, если один проект составляет 10 000 строк кода, а другой — 1 000 000 строк, второй проект значительно более сложный.
Проблемы с этой метрикой возникают, когда они используются для оценки производительности или уровня вклада в какой-либо проект. Если программист «X» записывает 2x количество строк в качестве программиста «Y», он может или не может внести больше — возможно, «Y» работает над более сложной проблемой.
Ответ 4
Когда хвастается за друзей.
Ответ 5
Это полезно при загрузке линейного принтера, чтобы вы знали, сколько страниц будет печататься в списке кода, которое вы собираетесь распечатать.;)
Ответ 6
Есть один частный случай, когда я считаю его неоценимым. Когда вы находитесь в интервью, и они говорят вам, что часть вашей работы будет заключаться в том, чтобы поддерживать существующий С++/Perl/Java/etc. старый проект. Задавая интервьюеру, сколько KLOC (приблизительно) вовлечено в унаследованный проект, даст вам более полное представление о том, хотите ли вы их работу или нет.
Ответ 7
По крайней мере, не для прогресса:
«Измерение прогресса программирования по линиям кода подобно измерению прогресса самолета по массе». —Bill Gates
Ответ 8
как и большинство показателей, они означают очень мало без контекста. Итак, короткий ответ: никогда (за исключением линейного принтера, это смешно! Кто печатает программы в эти дни?)
Представьте, что вы тестируете единицы измерения и рефакторинг устаревшего кода. Он начинается с 50 000 строк кода (50 KLOC) и 1000 доказанных ошибок (неудачные модульные тесты). Соотношение 1K/50KLOC = 1 ошибка на 50 строк кода. Очевидно, это ужасный код!
Теперь, несколько итераций позже, вы уменьшили известные ошибки на половину (и неизвестные ошибки более чем на то, что наиболее вероятно) и базу кода в пять раз с помощью образцового рефакторинга. Теперь отношение составляет 500/10000 = 1 баг на 20 строк кода. Это, по-видимому, еще хуже!
В зависимости от того, какое впечатление вы хотите сделать, это может быть представлено как одно или несколько из следующих:
- На 50% меньше ошибок
- в пять раз меньше кода
- На 80% меньше кода
- 60% ухудшение отношения ошибок к коду
все они верны (предполагая, что я не испортил математику), и все они сосать, чтобы обобщить огромное улучшение, которое должно было выполнить такие усилия рефакторинга.
Ответ 9
Ответ: когда вы можете говорить о отрицательных строках кода. Как и в: «Сегодня я удалил 40 посторонних строк кода, и программа все еще функционирует так же, как и раньше».
Ответ 10
Существует много разных Software Metrics. Строки кода наиболее часто используются и легче всего понять.
Я удивляюсь, как часто строки кодовой метрики коррелируют с другими метриками. Вместо покупки инструмента, который может вычислять циклическую сложность для обнаружения запахов кода, я просто ищу методы со многими строками, и они также имеют высокую сложность.
Хорошим примером использования строк кода является метрика: Ошибки на строки кода. Это может дать вам понять, сколько ошибок вы должны найти в своем проекте. В моей организации обычно около 20 ошибок на 1000 строк кода. Это означает, что если мы готовы отправить продукт с 100 000 строк кода, а наша база данных ошибок показывает, что мы обнаружили 50 ошибок, то нам, вероятно, следует провести еще несколько тестов. Если у нас есть 20 ошибок на 1000 строк кода, мы, вероятно, приближаемся к качеству, в котором мы обычно находимся.
Плохой пример использования — это измерение производительности разработчика. Если вы измеряете производительность разработчика по линиям кода, тогда люди склонны использовать больше строк для доставки меньше.
Ответ 11
Напоминает мне об этом:
Настоящее письмо очень длинное, просто потому, что у меня не было досуга, чтобы сделать его короче.
—Blaise Pascal.Ответ 12
Я согласен с тем, что общее число строк кода в проекте является одним из способов измерения сложности.
Это, конечно, не единственная мера сложности. Например, отладка 100 строк, запутанных Perl script, сильно отличается от отладки проекта на 5000 строк Java с шаблонами комментариев.
Но, не глядя на источник, вы, как правило, думаете, что более сложные строки кода сложнее, так же, как вы думаете, что исходный архив размером 10 МБ сложнее, чем исходный tarball на 15 КБ.
Ответ 13
Это полезно во многих отношениях.
Я не помню точного #, но у Microsoft была веб-трансляция, о которой говорилось для каждых X строк кода, в среднем есть количество ошибок. Вы можете принять это утверждение и использовать его, чтобы дать базовый уровень для нескольких вещей.
- Насколько хорошо работает рецензент кода.
- оценивая уровень мастерства 2 сотрудников, сравнивая их соотношение ошибок по нескольким проектам.
Еще одна вещь, на которую мы смотрим, — почему так много строк? Часто, когда новый программист помещается в пробку, они просто копируют и вставляют куски кода вместо создания функций и инкапсуляции.
Я думаю, что я написал x строк кода за день, это ужасная мера. Он не учитывает трудности проблемы, язык, на котором вы пишете, и т.д.
Ответ 14
Мне кажется, что существует конечный предел того, сколько строк кода я могу отнести к верхней части головы из любого данного проекта. Предел, вероятно, очень похож на среднего программиста. Поэтому, если вы знаете, что ваш проект имеет 2 миллиона строк кода, и ваши программисты могут быть уверены, что смогут понять, связана ли ошибка с 5K строками кода, которые они хорошо знают, тогда вы знаете, что вам нужно нанять 400 программисты для вашей базы кода хорошо защищены от памяти кого-то.
Это также заставит вас дважды подумать о том, как быстро увеличить свою базу кода, и может заставить вас подумать об их рефакторинге, чтобы сделать его более понятным.
Примечание. Я составил эти числа.
Ответ 15
Перефразируя цитату, которую я прочитал около 25 лет назад,
«Проблема с использованием строк кода как метрики заключается в том, что он измеряет сложность решения, а не сложность проблемы».
Я считаю, что цитата из Дэвида Парнаса в статье в Журнале ACM.
Ответ 16
Это показатель производительности, а также сложность. Как и все показатели, его нужно оценивать с осторожностью. Единственного показателя обычно недостаточно для полного ответа.
IE, 500-линейная программа не так сложна, как линия 5000. Теперь вам нужно задать другие вопросы, чтобы лучше просмотреть программу. но теперь у вас есть метрика.
Ответ 17
Это отличный показатель для пугающих/впечатляющих людей. Об этом, и определенно о контексте, который я вижу во всех трех этих примерах.
Ответ 18
Строки кода полезны для понимания, когда вам интересно, слишком ли большой файл кода. Hmmm. Этот файл теперь 5000 строк кода. Может быть, мне следует реорганизовать это.
Ответ 19
Когда вам нужно запланировать количество перфокарт, вам нужно заказать.
Ответ 20
Я написал 2 сообщения в блоге, посвященные про и минусам подсчета строк кода (LoC):
Как вы рассчитываете количество строк кода (LOC)?: Идея состоит в том, чтобы объяснить, что вам нужно подсчитать логическое число строк кода вместо физического счета. Для этого вы можете использовать такие инструменты, как NDepend.
Почему полезно подсчитывать количество строк кода (LOC)?: Идея заключается в том, что LoC никогда не следует использовать для измерения производительности, но еще больше для оценки охвата тестированием и оценки срока действия программного обеспечения.
Ответ 21
Институт программной инженерии Процесс зрелости Профиль сообщества программного обеспечения: 1998 год End Update (к сожалению, я не мог найти ссылку, к сожалению) обсуждает опрос около 800 разработчиков программного обеспечения (или, возможно, это были магазины). Средняя плотность дефектов составляла 12 дефектов на 1000 LOC.
Если у вас есть приложение с 0 дефектами (оно не существует на самом деле, но пусть предположим) и написал 1000 LOC, в среднем вы можете предположить, что вы только что ввели 12 дефектов в систему. Если QA обнаруживает 1 или 2 дефекта и что это, тогда им нужно сделать больше тестов, так как есть, вероятно, еще 10 дефектов.
Ответ 22
Когда вы рефакторинг базы кода и можете показать, что вы удалили строки кода, и все регрессионные тесты все еще прошли.
Ответ 23
Линии кода не так полезны на самом деле, и если они используются в качестве метрики по управлению, это приводит к тому, что программисты делают много рефакторинга, чтобы повысить свои баллы. Кроме того, бедные алгоритмы не заменяются аккуратными короткими алгоритмами, потому что это приводит к отрицательному счету LOC, который рассчитывается против вас. Честно говоря, просто не работайте в компании, которая использует LOC/d в качестве показателя производительности, потому что руководство явно не имеет никакого представления о разработке программного обеспечения, и поэтому вы всегда будете на обратной стороне с первого дня.
Ответ 24
Когда указывается, почему изменения будут длиться так долго.
«Windows — 7 миллионов строк кода, и для проверки всех зависимостей требуется некоторое время. «
Ответ 25
Ответ 26
Когда кодер не знает, что вы подсчитываете строки кода, и поэтому не имеет смысла преднамеренно добавлять избыточный код в игру в систему. И когда у каждого в команде одинаковый стиль кодирования (поэтому в строке есть известное среднее значение). И только если у вас нет лучшей меры.
Ответ 27
SLOC = ‘исходные строки кода’
На эти показатели, в которых я работаю, на самом деле довольно много времени. Существуют также различные способы подсчета SLOC.
Из статьи в википедии:
Существует два основных типа SLOC меры: физический SLOC и логический SLOC.
Ответ 28
Как уже отмечалось большинством людей, это может быть неоднозначная метрика, особенно если вы сравниваете кодирование людей на разных языках.
5000 строк Lisp!= 5000 строк C
Ответ 29
Это очень полезная идея, когда она связана с количеством дефектов. «Дефекты» дают вам качество кода. Наименее «дефекты» — лучшее программное обеспечение; Почти невозможно удалить все дефекты. Во многих случаях один дефект может быть вредным и смертельным.
Однако, похоже, что существует небезопасное программное обеспечение.
Ответ 30
При определении уровня усилия (LOE). Если вы соберете предложение, и у вас будут примерно одинаковые инженеры, работающие над новым проектом, тогда вы сможете определить, сколько инженеров потребуется в течение долгого времени.