what is precision?
I haven’t been able to find an answer on Wikipedia (or SO) or in the documentation for this very simple question.
How is the precision of a floating point number represented by an integer?
I am using the wrapper MPFRC++ over the arbitrary precision floating point library MPFR in C++ . There is the option to set default precision, and it takes an integer as an argument.
What does such an integer mean?
Also, I check the sizeof for various default precision, but they always seem to be the same? Why?
set_default_prec(128); sizeof(mpfr::mpreal); // 16
set_default_prec(4096); sizeof(mpfr::mpreal); // still 16.
2 Answers 2
set_default_prec undoubtedly changes the amount of storage (number of bits) allocated to store the data. It takes about 3.5 bits to store one decimal digit, so from there you just use simple math to figure out how many bytes are needed for a given number of digits.
As far as sizeof remaining constant, you undoubtedly have a struct (or class) that just contains a pointer to the actual data, something on this general order:
When you change the precision, it modifies the value stored in num_digits, and possibly the size of the block that data points at, but the size of the structure remains constant.
Everything you want can be found by Googling for «floating point» and «precision». For example:
http://en.wikipedia.org/wiki/Floating_point
Floating-point representation is similar in concept to scientific notation. Logically, a floating-point number consists of:
A signed digit string of a given length in a given base (or radix). This digit string is referred to as the significand, coefficient or, less often, the mantissa (see below). The length of the significand determines the precision to which numbers can be represented. The radix point position is assumed to always be somewhere within the significand—often just after or just before the most significant digit, or to the right of the rightmost (least significant) digit. This article will generally follow the convention that the radix point is just after the most significant (leftmost) digit.
A floating point number is an «approximation», not necessarily an exact value
The «precision» of a floating point number determines how accurate the approximation can be. More bits mean more precision (your number is «more exact»). Fewer bits mean less precision (the number is «more rounded»).
The amount of «precision» can and is represented as an integral number.
From the MPFR web site:
http://www.mpfr.org/mpfr-current/mpfr.html#MPFR-Basics
A floating-point number, or float for short, is an arbitrary precision significand (also called mantissa) with a limited precision exponent. .
The precision is the number of bits used to represent the significand of a floating-point number; the corresponding C data type is mpfr_prec_t. The precision can be any integer between MPFR_PREC_MIN and MPFR_PREC_MAX. In the current implementation, MPFR_PREC_MIN is equal to 2. .
«set_default_prec()», of course, is the mechanism for changing the precision (from «2»).
Урок №209. Функционал классов ostream и ios. Форматирование вывода
На этом уроке мы рассмотрим функционал классов ostream и ios в языке С++.
Примечание: Весь функционал объектов, которые работают с потоками ввода/вывода, находится в пространстве имен std. Это означает, что вам нужно либо добавлять префикс std:: ко всем объектам и функциям ввода/вывода, либо использовать в программе строку using namespace std; .
Форматирование вывода
Оператор вставки (вывода) << используется для помещения информации в выходной поток. А как мы уже знаем из урока о потоках, классы istream и ostream являются дочерними классу ios . Одной из задач ios (и ios_base ) является управление параметрами форматирования вывода.
Есть два способа управления параметрами форматирования вывода:
флаги — это логические переменные, которые можно включить/выключить;
манипуляторы — это объекты, которые помещаются в поток и влияют на способ ввода/вывода данных.
Для включения флага используйте функцию setf() с соответствующим флагом в качестве параметра. Например, по умолчанию C++ не выводит знак + перед положительными числами. Однако, используя флаг std::showpos, мы можем это изменить:
Также можно включить сразу несколько флагов, используя побитовый оператор ИЛИ ( | ):
Чтобы отключить флаг, используйте функцию unsetf():
Многие флаги принадлежат к определенным группам форматирования. Группа форматирования — это группа флагов, которые задают аналогичные (иногда взаимоисключающие) параметры форматирования вывода. Например, есть группа форматирования basefield.
Флаги группы форматирования basefield:
oct (от англ. «octal» = «восьмеричный») — восьмеричная система счисления;
dec (от англ. «decimal» = «десятичный») — десятичная система счисления;
hex (от англ. «hexadecimal» = «шестнадцатеричный») — шестнадцатеричная система счисления.
Эти флаги управляют выводом целочисленных значений. По умолчанию установлен флаг std::dec, т.е. значения выводятся в десятичной системе счисления. Попробуем сделать следующее:
Ничего не работает! Почему? Дело в том, что setf() только включает флаги, он не настолько умен, чтобы одновременно отключать другие (взаимоисключающие) флаги. Следовательно, когда мы включаем std::hex, std::dec также включен и у него приоритет выше. Есть два способа решения данной проблемы.
Во-первых, мы можем отключить std::dec, а затем включить std::hex:
Теперь уже результат тот, что нужно:
Второй способ — использовать вариацию функции setf(), которая принимает два параметра:
первый параметр — это флаг, который нужно включить/выключить;
второй параметр — группа форматирования, к которой принадлежит флаг.
При использовании этой вариации функции setf() все флаги, принадлежащие группе форматирования, отключаются, а включается только передаваемый флаг. Например:
Язык C++ также предоставляет еще один способ изменения параметров форматирования: манипуляторы. Фишка манипуляторов в том, что они достаточно умны, чтобы одновременно включать и выключать соответствующие флаги. Например:
В общем, использовать манипуляторы гораздо проще, нежели включать/выключать флаги. Многие параметры форматирования можно изменять как через флаги, так и через манипуляторы, но есть и такие параметры форматирования, которые изменить можно либо только через флаги, либо только через манипуляторы.
Полезные флаги, манипуляторы и методы
Ниже мы рассмотрим список наиболее полезных флагов, манипуляторов и методов. Флаги находятся в классе ios , манипуляторы — в пространстве имен std, а методы — в классе ostream .
Флаг:
boolalpha — если включен, то логические значения выводятся как true / false . Если выключен, то логические значения выводятся как 0 / 1 .
Манипуляторы:
boolalpha — логические значения выводятся как true / false .
noboolalpha — логические значения выводятся как 0 / 1 .
1 0
true false
1 0
true false
Флаг:
showpos — если включен, то перед положительными числами указывается знак + .
Манипуляторы:
showpos — перед положительными числами указывается знак + .
noshowpos — перед положительными числами не указывается знак + .
Флаг:
uppercase — если включен, то используются заглавные буквы.
Манипуляторы:
uppercase — используются заглавные буквы.
nouppercase — используются строчные буквы.
1.23457e+007
1.23457E+007
1.23457e+007
1.23457E+007
Флаги группы форматирования basefield:
dec — значения выводятся в десятичной системе счисления;
hex — значения выводятся в шестнадцатеричной системе счисления;
oct — значения выводятся в восьмеричной системе счисления.
Манипуляторы:
dec — значения выводятся в десятичной системе счисления;
hex — значения выводятся в шестнадцатеричной системе счисления;
oct — значения выводятся в восьмеричной системе счисления.
Теперь вы уже должны понимать связь между флагами и манипуляторами.
Точность, запись чисел и десятичная точка
Используя манипуляторы (или флаги), можно изменить точность и формат вывода значений типа с плавающей точкой.
Флаги группы форматирования floatfield:
fixed — используется десятичная запись чисел типа с плавающей точкой;
scientific — используется экспоненциальная запись чисел типа с плавающей точкой;
showpoint — всегда отображается десятичная точка и конечные нули для чисел типа с плавающей точкой.
Манипуляторы:
fixed — используется десятичная запись значений;
scientific — используется экспоненциальная запись значений;
showpoint — отображается десятичная точка и конечные нули чисел типа с плавающей точкой;
noshowpoint — не отображаются десятичная точка и конечные нули чисел типа с плавающей точкой;
setprecision(int) — задаем точность для чисел типа с плавающей точкой.
Методы:
precision() — возвращаем текущую точность для чисел типа с плавающей точкой;
precision(int) — задаем точность для чисел типа с плавающей точкой.
Если используется десятичная или экспоненциальная запись чисел, то точность определяет количество цифр после запятой/точки. Обратите внимание, если точность меньше количества значащих цифр, то число будет округлено. Например:
Setting Decimal Precision in C Language
This article will show you how to set decimal precision in C programming language. First, we will define precision, and then, we will look into multiple examples to show how to set decimal precision in C programming.
Decimal Precision in C
The integer type variable is normally used to hold the whole number and float type variable to hold the real numbers with fractional parts, for example, 2.449561 or -1.0587. Precision determines the accuracy of the real numbers and is denoted by the dot (.) symbol. The Exactness or Accuracy of real numbers is indicated by the number of digits after the decimal point. So, precision means the number of digits mentioned after the decimal point in the float number. For example, the number 2.449561 has precision six, and -1.058 has precision three.
As per IEEE-754 single-precision floating point representation, there are a total of 32 bits to store the real number. Of the 32 bits, the most significant bit is used as a sign bit, the following 8 bits are used as an exponent, and the following 23 bits are used as a fraction.
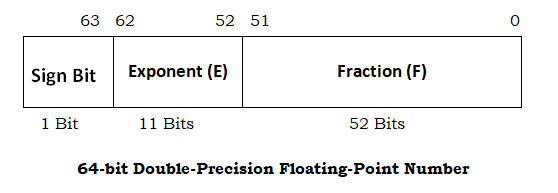
In the case of IEEE-754 double-precision floating point representation, there are a total of 64 bits to store the real number. Of the 64 bits, the most significant bit is used as a sign bit, the following 11 bits are used as an exponent, and the following 52 bits are used as a fraction.
However, when printing the real numbers, it is necessary to specify the precision (in other words, accuracy) of the real number. If the precision is not specified, the default precision will be considered, i.e., six decimal digits after the decimal point. In the following examples, we will show you how to specify precision when printing floating-point numbers in the C programming language.
Examples
Now that you have a basic understanding of precision, let us look at a couple of examples:
-
- Default precision for float
- Default precision for double
- Set precision for float
- Set precision for double
Example 1: Default Precision for Float
This example shows that the default precision is set to six digits after the decimal point. We have initialized a float variable with the value 2.7 and printed it without explicitly specifying the precision.
In this case, the default precision setting will ensure that six digits after the decimal point are printed.
printf ( " \n Value of f = %f \n " , f ) ;
printf ( "Size of float = %ld \n " , sizeof ( float ) ) ;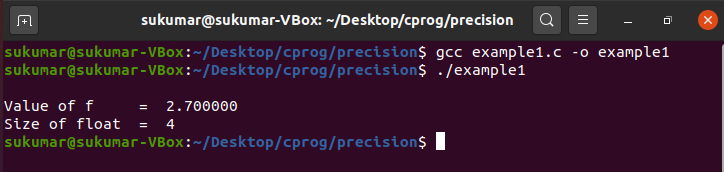
Example 2: Default Precision for Double
In this example, you will see that the default precision is set to six digits after the decimal point for double type variables. We have initialized a double variable, i.e., d, with the value 2.7 and printed it without specifying the precision. In this case, the default precision setting will ensure that six digits after the decimal point are printed.
printf ( " \n Value of d = %lf \n " , d ) ;
printf ( "Size of double = %ld \n " , sizeof ( double ) ) ;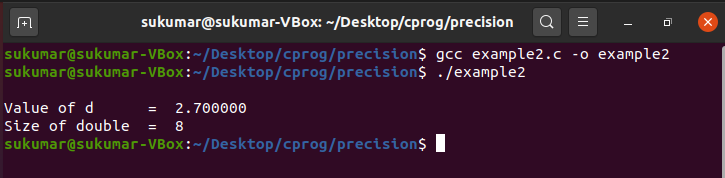
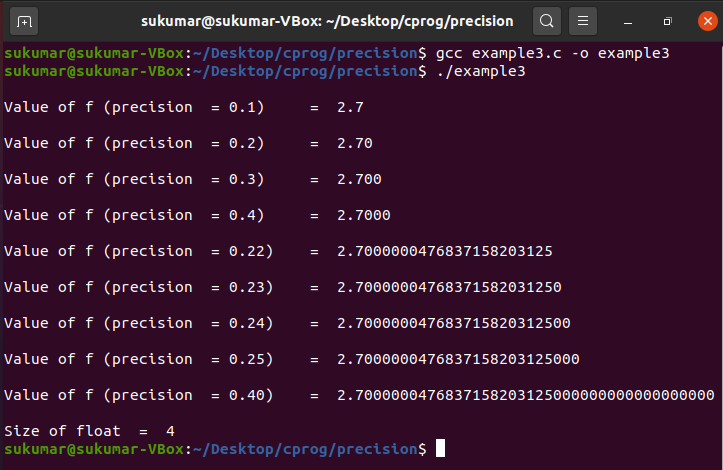
Example 3: Set Precision for Float
Now, we will show you how to set precision for float values. We have initialized a float variable, i.e., f, with the value 2.7, and printed it with various precision settings. When we mention “%0.4f” in the printf statement, this indicates that we are interested in printing four digits after the decimal point.
/* set precision for float variable */
printf ( " \n Value of f (precision = 0.1) = %0.1f \n " , f ) ;
printf ( " \n Value of f (precision = 0.2) = %0.2f \n " , f ) ;
printf ( " \n Value of f (precision = 0.3) = %0.3f \n " , f ) ;
printf ( " \n Value of f (precision = 0.4) = %0.4f \n " , f ) ;printf ( " \n Value of f (precision = 0.22) = %0.22f \n " , f ) ;
printf ( " \n Value of f (precision = 0.23) = %0.23f \n " , f ) ;
printf ( " \n Value of f (precision = 0.24) = %0.24f \n " , f ) ;
printf ( " \n Value of f (precision = 0.25) = %0.25f \n " , f ) ;
printf ( " \n Value of f (precision = 0.40) = %0.40f \n " , f ) ;printf ( "Size of float = %ld \n " , sizeof ( float ) ) ;
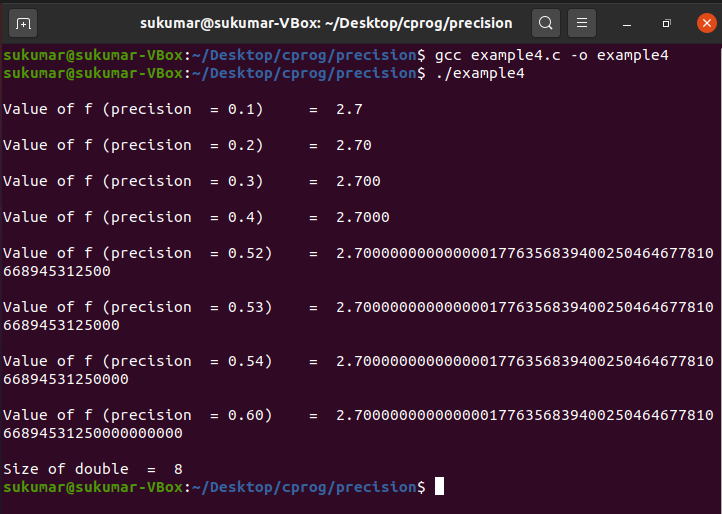
Example 4: Set Precision for Double
In this example, we will see how to set precision for double values. We have initialized a double variable, i.e., d, with the value 2.7 and printed it with various precision settings. When we mention “%0.52f” in the printf statement, this indicates that we are interested in printing 52 digits after the decimal point.
/* set precision for float variable */
printf ( " \n Value of f (precision = 0.1) = %0.1f \n " , f ) ;
printf ( " \n Value of f (precision = 0.2) = %0.2f \n " , f ) ;
printf ( " \n Value of f (precision = 0.3) = %0.3f \n " , f ) ;
printf ( " \n Value of f (precision = 0.4) = %0.4f \n " , f ) ;printf ( " \n Value of f (precision = 0.22) = %0.22f \n " , f ) ;
printf ( " \n Value of f (precision = 0.23) = %0.23f \n " , f ) ;
printf ( " \n Value of f (precision = 0.24) = %0.24f \n " , f ) ;
printf ( " \n Value of f (precision = 0.25) = %0.25f \n " , f ) ;
printf ( " \n Value of f (precision = 0.40) = %0.40f \n " , f ) ;printf ( "Size of float = %ld \n " , sizeof ( float ) ) ;
Conclusion
Precision is a very important factor for representing a real number with adequate accuracy. The c programming language provides the mechanism to control the accuracy or exactness of a real number. However, we cannot change the actual precision of the real number. For example, the fraction part of a 32-bit single-precision floating-point number is represented by 23 bits, and this is fixed; we cannot change this for a particular system. We can only decide how much accuracy we want by setting the desired precision of the real number. If we need more accuracy, we can always use the 64-bit double-precision floating-point number.
C Float
Summary: in this tutorial, you will learn about various C float types including float, double and long double.
Introduction to C float types
Floating-point numbers are numbers that have a decimal point. For example, 3.14 is a floating-point number. C has two floating-point types:
- float: single-precision floating-point numbers
- double: double-precision floating-point numbers.
The following example uses the float and double keyword to define floating-point number variables:
- First, define three floating-point numbers x, y, and z.
- Second, add three numbers up and display the result.
The sum of 0.1, 0.1, and 0.1 is not 0.3 but 0.30000001192092896000. This is is due to the precision of the floating-point numbers.
What is precision?
If you consider the fraction 5/3, this number can be represented in decimal as 1.666666666. with infinite 6.
Since computers use a fixed number of bits, it cannot store an infinite number. Instead, computers store these numbers with precisions.
The precision is expressed as a number of significant digits. In other words, precision is defined as how many digits that a number can represent without data loss.
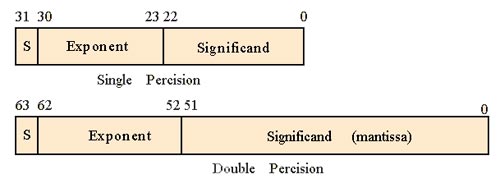
For example, the float type with 4 bytes = 4 x 8 bits = 32 bits, is for numbers with single precision. It means that a float gives 1 sign bit, 8 bits of exponent, and 23 bits of significand.
The double type is for a number with the double-precision that gives 1 sign bit, 11 bits of exponent, and 52 bits of significand. (8 bytes x 8 bits = 64 bits = 1 bits + 52 bits + 11 bits).
Short and long qualifiers
Like integers, you can apply the short and long qualifier to control the size of the floating-point type. The following table shows the floating-point types in C.
Type Size Ranges Smallest Positive Value Precision float 4 bytes ±3.4E+38 1.2E-38 6 digits double 8 bytes ±1.7E+308 2.3E-308 15 digits long double 10 bytes ±1.1E+4932 3.4E-4932 19 digits It is important to note that this is only the minimal requirement for storage size defined by C.
Float ranges and precision
To find the value ranges of the floating-point number, you can use the float.h header file. This header file defines macros such as FLT_MIN , FLT_MAX and FLT_DIG that store the float value ranges and precision of the float types.
The float.h also defines macros for double and long double with the prefixes DBL_ and LDBL_ .
The following program illustrates the storage size and precision of floating-point numbers in your system.