Многомерные хранилища данных. Модели кубов данных.
В многомерных хранилищах данных содержатся агрегатные данные различной степени подробности, например, объемы продаж по дням, месяцам, годам, по категориям товаров и т.п. Цель хранения агрегатных данных — сократить время выполнения запросов, поскольку в большинстве случаев для анализа и прогнозов интересны не детальные, а суммарные данные. Поэтому при создании многомерной базы данных всегда вычисляются и сохраняются некоторые агрегатные данные.
Отметим, что сохранение всех агрегатных данных не всегда оправданно. Дело в том, что при добавлении новых измерений объем данных, составляющих куб, растет экспоненциально (иногда говорят о <взрывном росте> объема данных). Если говорить более точно, степень роста объема агрегатных данных зависит от количества измерений куба и членов измерений на различных уровнях иерархий этих измерений. Для решения проблемы <взрывного роста> применяются разнообразные схемы, позволяющие при вычислении далеко не всех возможных агрегатных данных достичь приемлемой скорости выполнения запросов.
Как исходные, так и агрегатные данные могут храниться либо в реляционных, либо в многомерных структурах. Поэтому в настоящее время применяются три способа хранения данных:
MOLAP (Multidimensional OLAP) — исходные и агрегатные данные хранятся в многомерной базе данных. Хранение данных в многомерных структурах позволяет манипулировать данными как многомерным массивом, благодаря чему скорость вычисления агрегатных значений одинакова для любого из измерений. Однако в этом случае многомерная база данных оказывается избыточной, так как многомерные данные полностью содержат исходные реляционные данные.
ROLAP (Relational OLAP) — исходные данные остаются в той же реляционной базе данных, где они изначально и находились. Агрегатные же данные помещают в специально созданные для их хранения служебные таблицы в той же базе данных.
HOLAP (Hybrid OLAP) — исходные данные остаются в той же реляционной базе данных, где они изначально находились, а агрегатные данные хранятся в многомерной базе данных.
Некоторые OLAP-средства поддерживают хранение данных только в реляционных структурах, некоторые — только в многомерных. Однако большинство современных серверных OLAP-средств поддерживают все три способа хранения данных. Выбор способа хранения зависит от объема и структуры исходных данных, требований к скорости выполнения запросов и частоты обновления OLAP-кубов.
Отметим также, что подавляющее большинство современных OLAP-средств не хранит <пустых> значений (примером <пустого> значения может быть отсутствие продаж сезонного товара вне сезона).
Витрины данных. Методы организации витрин данных.
Витрина данных— срез хранилища данных, представляющий собой массив тематической, узконаправленной информации, ориентированный, например, на пользователей одной рабочей группы или департамента.
Витрины данных по определению намного дешевле и проще в построении, чем хранилища данных, их внедрение не требует больших временных затрат и приносит быстрый и ощутимый эффект. В то же время необходимо понимать, что при таком подходе независимые витрины данных не будут создавать единой информационной системы компании, не будет единой системы извлечения информации, консолидации, управления и обслуживания.
Если компания небольшая, она может смело идти на создание автономных витрин данных. Если же компания крупная, то создание автономных витрин данных должно координироваться из единого центра с тем, чтобы в итоге придти к созданию единого хранилища данных компании.
Создание витрины данных
Создание витрины данных это создание соответствующей базы данных и системы ее загрузки. Если создание базы данных вопрос чисто технический, создание системы загрузки представляет основную сложность. Эта система содержит три этапа:
извлечение данных из исходных систем; преобразование их в требуемую форму; загрузка подготовленных данных в витрину.
1. Извлечение данных требует точного знания структуры исходных систем. Структуры и взаимосвязи таблиц, структуры информации в исходной системе. Необходимо четко знать из каких таблиц и полей необходимо извлекать данные и какова структура этих данных.
2. Исходная система изначально никак не ориентирована на работу с витриной данных и данные, извлекаемые из нее, не предназначены для непосредственного использования и должны пройти ряд преобразований. Процесс этих преобразований зависит и от структуры исходных систем, и от требований к самой витрине данных, он может заключать в себе множество функций:
Создание агрегатных данных
Изменение форматов данных.
Проверку достоверности и целостности данных.
Удаление избыточных данных И т.д.
Все эти преобразования осуществляются только на этапе ввода данных в витрину, что обеспечивает высокую скорость извлечения данных из витрины и наилучшее представление этих данных с точки зрения пользователя. В конечном итоге это приводит к лучшему информационному обеспечению пользователя, и способствуют быстрому принятию им правильных управленческих решений.
3. Данные в витрине должны соответствовать данным исходных систем, которые, естественно, изменяются со временем. Поэтому инструменты, осуществляющие преобразования и загрузку данных в витрину должны запускаться периодически при определенных изменениях данных исходных систем и/или автоматически по определенному расписанию.
Из изложенного вытекает довольно важный вывод. Нельзя купить готовую витрину данных для своей компании. Витрина данных это эксклюзивный заказной продукт, который должен создаваться непосредственно под конкретную компанию, под всю ее специфику.
Русские Блоги
Витрина данных — это простая форма хранилища данных, которая обычно создается и контролируется бизнес-отделами организации. Витрина данных работает в одной предметной области, такой как продажи, финансы, маркетинг и т. Д. Источником данных витрины данных может быть операционная система (независимая витрина данных) или хранилище данных уровня предприятия (подчиненная витрина данных).
Разница между витриной данных и хранилищем данных
В отличие от витрин данных, хранилища данных имеют дело с несколькими предметными областями внутри всей организации и обычно создаются основными подразделениями внутри организации, такими как ИТ-отделы, поэтому их часто называют центральными хранилищами данных или корпоративными хранилищами данных. Хранилища данных должны интегрировать данные из многих операционных систем. Поскольку сложность витрины данных и обрабатываемых данных меньше, чем у хранилища данных, ее проще создавать и поддерживать. В таблице 2-19 приведены основные различия между хранилищами данных и витринами данных.

Дизайн витрины данных
Витрины данных в основном используются для аналитических приложений на уровне отделов. Большая часть данных суммируется и агрегируется с высокой степенью детализации. В витрине данных обычно используется метод проектирования размерной модели, а в структуре данных используется схема «звезда» или схема «снежинка». Как упоминалось ранее, для разработки размерной модели сначала определите таблицу измерений, таблицу фактов и уровень детализации данных.Следующим шагом является использование первичных и внешних ключей для определения взаимосвязи между таблицей фактов и таблицей измерений. В качестве первичного ключа в витрине данных лучше всего использовать саморазрастающийся числовой суррогатный ключ из одного столбца, созданный системой. После того, как модель создана, этап ETL предназначен для извлечения данных операционной исходной системы, и после очистки и преобразования данных он, наконец, загружается в таблицу измерений и таблицу фактов на витрине данных.
Справка
[Книга] Практика построения хранилищ данных Hadoop, Глава 2 Раздел 4 — Витрина данных
Разница между хранилищем данных и представлением данных
 Хранилище данных и витрина данных используются в качестве хранилища данных и служат для той же цели. Они могут быть дифференцированы по количеству данных или информации, которую они хранят. Жизненно важное различие между хранилищем данных и витриной данных заключается в том, что хранилище данных — это база данных, в которой хранится информация, ориентированная на удовлетворение запросов на принятие решений, тогда как витрина данных представляет собой полные логические подмножества всего хранилища данных.
Хранилище данных и витрина данных используются в качестве хранилища данных и служат для той же цели. Они могут быть дифференцированы по количеству данных или информации, которую они хранят. Жизненно важное различие между хранилищем данных и витриной данных заключается в том, что хранилище данных — это база данных, в которой хранится информация, ориентированная на удовлетворение запросов на принятие решений, тогда как витрина данных представляет собой полные логические подмножества всего хранилища данных.
Проще говоря, витрина данных — это хранилище данных, ограниченное по объему, данные которого можно получить путем суммирования и выбора данных из хранилища данных или с помощью различных процессов извлечения, преобразования и загрузки из системы исходных данных.
Сравнительная таблица
| Основа для сравнения | Хранилище данных | Data Mart |
|---|---|---|
| основной | Хранилище данных не зависит от приложений. | Данные витрины специфичны для приложения системы поддержки принятия решений. |
| Тип системы | централизованные | децентрализованная |
| Форма данных | детализированный | Обобщенная |
| Использование денормализации | Данные немного денормализованы. | Данные сильно денормализованы. |
| Модель данных | Низходящий | Вверх дном |
| Природа | Гибкий, ориентированный на данные и долгий срок службы. | Ограничительная, ориентированная на проект и короткая жизнь. |
| Тип используемой схемы | Факт Созвездие | Звезда и снежинка |
| Легкость строительства | Трудно построить | Прост в сборке |
Определение хранилища данных
Термин « хранилище данных» означает временную, предметно-ориентированную, энергонезависимую и интегрированную группу данных, которые помогают в процессе принятия решений руководством. В качестве альтернативы, это хранилище информации, собранной из нескольких источников, хранящейся в единой схеме, на единственном сайте, который позволяет интегрировать различные прикладные системы. Как только эти данные собраны, они хранятся в течение длительного времени, следовательно, имеют длительный срок службы и позволяют получить доступ к исторической информации.
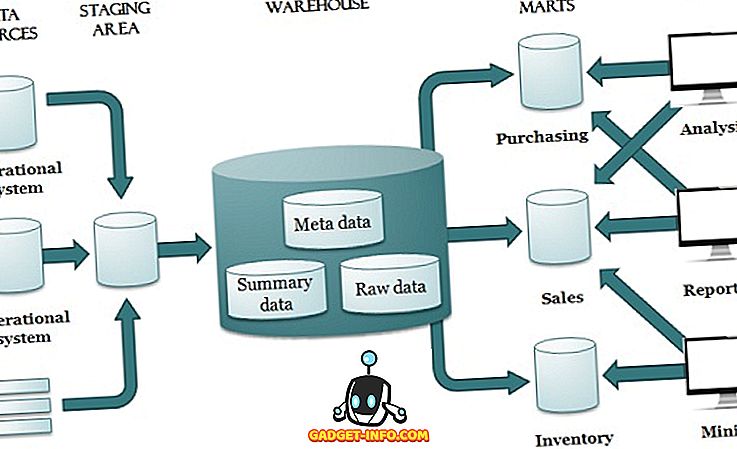
Следовательно, хранилище данных предоставляет пользователю единый интегрированный интерфейс с данными, через который пользователь может легко писать запросы поддержки принятия решений. Хранилище данных помогает превратить данные в информацию. Проектирование хранилища данных включает нисходящий подход.
Он собирает информацию о субъектах, охватывающих всю организацию, таких как клиенты, продажи, активы, товары, и, следовательно, его диапазон охватывает все предприятие. Обычно в нем используется схема констелляции фактов, которая охватывает широкий круг вопросов. Хранилище данных не является статичной структурой и постоянно развивается .
Определение Data Mart
Витрина данных может быть вызвана как подмножество хранилища данных или подгруппа общекорпоративных данных, соответствующих определенному набору пользователей. Хранилище данных включает в себя несколько ведомственных и логических витрин данных, которые должны быть постоянными в их иллюстрации данных, чтобы обеспечить надежность хранилища данных. Витрина данных — это набор таблиц, которые концентрируются на одной задаче, разработанной с использованием подхода «снизу вверх».
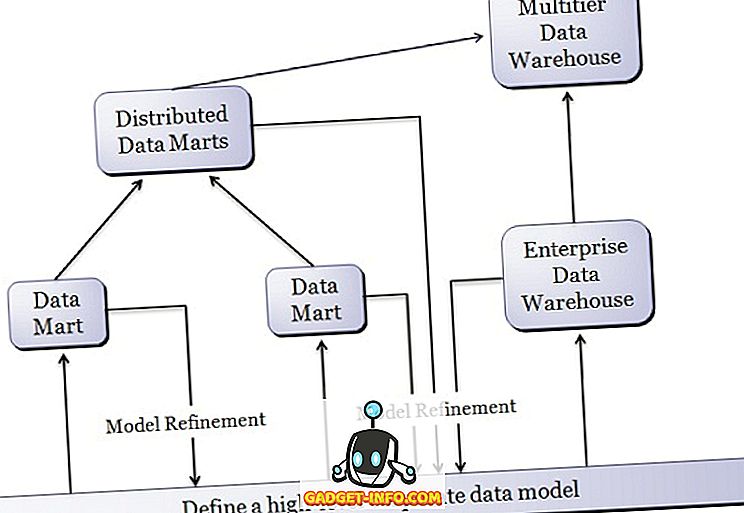 Объем витрины данных ограничен каким-то конкретным выбранным предметом, поэтому он распространяется на весь отдел. Они обычно реализуются на недорогих ведомственных серверах. Цикл реализации витрин данных отслеживается в неделях, а не в месяце и году.
Объем витрины данных ограничен каким-то конкретным выбранным предметом, поэтому он распространяется на весь отдел. Они обычно реализуются на недорогих ведомственных серверах. Цикл реализации витрин данных отслеживается в неделях, а не в месяце и году.
Поскольку схема « звезда» и « снежинка» ориентирована на моделирование одного объекта, именно поэтому они обычно используются в витрине данных. Хотя схема «звезда» более популярна, чем схема «снежинка». В зависимости от источника данных витрины данных могут быть классифицированы на два типа: зависимые и независимые витрины данных.
Ключевые различия между хранилищем данных и представлением данных
- Хранилище данных не зависит от приложения, в то время как витрина данных является специфической для приложения системы поддержки принятия решений.
- Данные хранятся в одном централизованном хранилище в хранилище данных. В отличие от этого, витрина данных хранит данные децентрализованно в пользовательской области.
- Хранилище данных содержит подробную форму данных. Напротив, витрина данных содержит обобщенные и выбранные данные.
- Данные в хранилище данных слегка денормализованы, тогда как в случае витрины данных они сильно денормализованы.
- Построение хранилища данных предполагает нисходящий подход. И наоборот, при построении витрины данных используется восходящий подход.
- Хранилище данных является гибким, ориентированным на информацию и давно существующим характером. Напротив, витрина данных ограничена, ориентирована на проект и имеет более короткое существование.
- Схема констелляции фактов обычно используется для моделирования хранилища данных, тогда как в витрине данных схема «звезда» более популярна.
Заключение
Хранилище данных обеспечивает представление предприятия, единую и централизованную систему хранения, собственную архитектуру и независимость приложений, в то время как витрина данных является подмножеством хранилища данных, которое обеспечивает представление отдела, децентрализованное хранилище. Поскольку хранилище данных очень большое и интегрированное, оно имеет высокий риск отказа и сложностей при его создании. С другой стороны, витрину данных легко построить, и связанный с этим риск отказов также меньше, но витрина данных может подвергаться фрагментации.
Что такое витрина данных?
Витрина данных — это простая форма хранилища данных, ориентированная на одно направление деятельности или тему. С витриной данных сотрудники могут быстрее получать доступ к данным и статистическим показателям, потому что не нужно тратить время на поиск по более сложному хранилищу данных или вручную собирать данные из разных источников.
Зачем создавать витрину данных?
Витрина данных обеспечивает более простой доступ к данным, необходимым для определенного отдела или производственного направления внутри организации. Например, если ваш отдел маркетинга ищет данные, которые помогут ему повысить эффективность рекламной кампании в период праздников, просматривать и выбирать нужные данные из нескольких разрозненных систем довольно затратно и с точки зрения времени, и с точки зрения денег, причем невозможно обеспечить точность.
Сотрудники подразделений, которые вынуждены искать данные в разных источниках, как правило, пользуются таблицами для обмена информацией и сотрудничества. Это часто приводит к человеческим ошибкам, путанице, сложным согласованиям и появлению нескольких источников достоверных данных — так называемому «табличному кошмару». Витрины данных стали довольно популярны как централизованные хранилища, в которых собираются и упорядочиваются нужные данные, после чего могут создаваться отчеты, информационные панели и визуализации.
Различия между витриной данных, озером данных и хранилищем данных
Витрины данных, озера данных и хранилища данных используются в разных ситуациях и для разных целей.
Хранилище данных — это система управления данными, которая поддерживает анализ бизнес-данных и выполнение аналитики для всей организации. Хранилища данных часто содержат большие объемы данных, в том числе исторических. Обычно данные поступают в хранилище из многочисленных источников, таких как журналы приложений и транзакционные приложения. В хранилище данных хранятся структурированные данные с определенными целями.
Озеро данных позволяет организациям хранить большие объемы структурированных и неструктурированных данных (например, из социальных сетей или данных о посещениях) и мгновенно предоставлять к ним доступ для выполнения в реальном времени аналитики, углубленной аналитики данных и построения сценариев использования машинного обучения. Данные поступают в озеро данных в своей исходной форме, без изменений.
Основное различие между озером данных и хранилищем данных состоит в том, что в озере хранятся большие объемы необработанных данных без заранее определенной структуры. Организациям не нужно определять заранее, как будут использоваться эти данные.
Витрина данных — это простая форма хранилища данных, которое ориентировано на определенную тему или направление деятельности, например на продажи, финансы или маркетинг. С учетом этой узкой специализации получается, что витрины данных собирают данные из меньшего количества источников, чем хранилища данных. Источниками для витрины данных могут служить внутренние операционные системы, центральное хранилище данных и внешние данные.
Преимущества витрины данных
Витрина данных, созданная для определенного отдела или направления деятельности, дает ряд преимуществ:
- Единый источник достоверных данных. Централизованный характер витрины данных гарантирует, что все в отделе или организации принимают решения, опираясь на одни и те же данные. Это важное преимущество, потому что данным и основанным на них прогнозам можно доверять, так что заинтересованные лица могут сосредоточиться на принятии решений и выполнении действий, а не на обсуждении данных.
- Более быстрый доступ к данным. Конкретные бизнес-отделы или пользователи могут быстро получать доступ к нужному им подмножеству данных из корпоративного хранилища данных, и объединять эту информацию с данными из других источников. Когда связи с источниками нужных данных будут установлены, сотрудники смогут получать оперативные данные из витрины данных по мере необходимости, а не обращаться в отдел ИТ, чтобы запросить периодически собираемую информацию. В результате повышается производительность как бизнес-отделов, так и ИТ.
- Быстрое получение статистических данных ускоряет принятие решений. Хранилище данных помогает принимать решения на уровне предприятия, а витрина данных предоставляет аналитику данных на уровне отделов и подразделений. Аналитики могут сосредоточиться на определенных проблемах и возможностях в таких сферах, как финансы и HR, и быстрее переходить от просмотра данных к статистическим показателям, которые позволяют быстрее принимать более взвешенные решения.
- Более простое и быстрое применение. Настройка корпоративного хранилища данных для обслуживания всей компанией может потребовать немало времени и усилий. А витрине данных, настроенной на обслуживание потребностей определенного отдела, достаточно доступа к гораздо меньшему количеству множеств данных. Поэтому витрину данных проще создавать и быстрее можно начать использовать.
- Создание гибкого и масштабируемого решения для управления данными. Витрины данных предлагают гибкие системы по управлению данными, которые работают с учетом потребностей компании, в том числе могут использовать информацию, собранную при выполнении прошлых проектов, чтобы способствовать решению текущих задач. Отделы и подразделения могут обновлять и изменять свои витрины данных, опираясь на новые и недавно запущенные проекты по аналитике.
- Анализ переходных процессов. Некоторые проекты по аналитике данных выполняются в сжатые сроки. Например, нужно провести анализ онлайн-продаж по результатам двухнедельной рекламной акции, чтобы представить его на совещании отдела. И отдел может быстро настроить витрину данных для выполнения такого проекта.
Перенос витрин данных в облако
Рабочие группы и отделы стараются действовать более гибко и опираться на данные при внедрении общей стратегии и принятии повседневных решений. Но, как правило, бывает непросто превратить постоянно растущий объем данных в статистические показатели. Финансовые директора проводят в среднем по 2,24 часа в день, анализируя таблицы данных. Рабочие группы обычно обращаются за помощью в отдел ИТ, и ИТ-специалистам приходится тратить немало сил, чтобы соответствовать запросам пользователей и предоставлять данные из разнообразных источников в больших объемах, а также быстрее реагировать на запросы.
Создание витрин данных также может осложнить задачи и без того загруженному работой отделу ИТ, потому что им нужно будет постоянно контролировать эти витрины данных и обеспечивать их безопасность. Перенос витрин данных в облако может решить многие проблемы как рабочих групп, так и отделов ИТ, потому что администрированием и обеспечением безопасности в облаке будет заниматься поставщик облачных решений. Таким образом значительно сокращается число задач, которые нужно выполнять вручную, и снижаются операционные расходы.
Как Oracle Autonomous Database обеспечивает работу облачных витрин данных
Oracle предлагает готовое комплексное решение самообслуживания, которое позволяет рабочим группам и отделам пользоваться надежными статистическими показателями, полученными в результате глубокого анализа данных. Эти показатели помогут им быстрее принимать решения.
Сотрудники и отделы могут быстро объединять все нужные данные из разных источников и в разных форматах, включая пространственные объекты и графы, в единую базу данных, которая способствует налаживанию сотрудничества в защищенном режиме благодаря тому, что витрины данных предоставляют единственный источник достоверных данных. Аналитики могут с легкостью использовать инструменты самообслуживания для работы с данными и возможности машинного обучения (не занимаясь самостоятельно написанием программного кода), чтобы ускорить загрузку данных, их преобразование и подготовку, автоматически выявлять шаблоны и тенденции, делать прогнозы и получать статистические показатели на основе данных известного проиcхождения.
Контролируемые и безопасные решения Oracle позволяют снизить нагрузку на отделы ИТ. Отделы ИТ могут полагаться на простые, надежные и воспроизводимые методы при любых запросах на аналитику данных от различных подразделений организации, и таким образом значительно повышать производительность.
Oracle Autonomous Database для аналитики и хранилища данных автоматизирует инициализацию, настройку, обеспечение безопасности, отладку, масштабирование, внесение исправлений, создание резервных копий и ремонт. Он практически полностью устраняет потребность в ручном выполнении сложных задач, которые могут вести к человеческим ошибкам. Встроенные инструменты для работы с данными позволяют в режиме самообслуживания с легкостью выполнять загрузку данных, их преобразование, бизнес-моделирование и автоматическое вычисление статистических показателей для витрин данных. Администраторы баз данных могут не тратить силы на решение рутинных задач, а вместо этого заняться проектированием новых приложений и помогать другим отделам в достижении поставленных целей. Специалисты из сферы финансов, HR и маркетинга получают безопасный доступ к данным и могут рассчитывать на неизменно быстрые и качественные ответы на запросы даже в периоды пиковых нагрузок независимо от того, сколько пользователей одновременно обращаются за информацией. Autonomous Database выполняет масштабирование автоматически в зависимости от рабочей нагрузки без простоев в работе.