Как парсером авторизироваться на сайте?
В туториале человек через инструменты разработчика смотрит запрос при регестрации со статусом 302 и методом POST, в котором у него внизу отображается данные которые он отправил (пункт Form Data), в этом пункте и есть ссылка на которую надо скидывать данные для входа
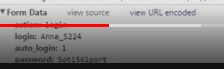

У меня же если ввести корректные данные запрос 302 с методом GET и к тому же не имеет пункта Form Data

(синие квадраты это основная ссылка по типу ):
И в низу никакого пункта Form Data нет
После этого я решил ввести неверные данные и посмотреть куда этот запрос введет, и введя их я получил запрос 301 метода POST где был пункт Form Data, в котором показывались данные которые требует сайт при авторизации
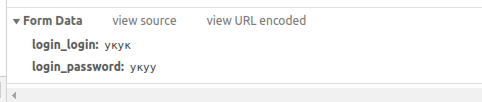
Тогда я и решил взять ссылку запроса от туда и отправлять туда эти данные, и в получил вот такое в IDE :
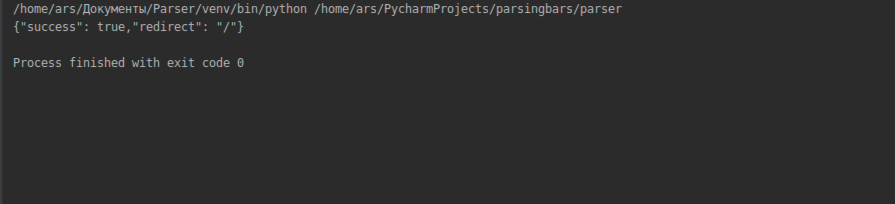
Как сделать так чтобы я вводил эти данные, авторизировался и получал уже html код самого сайта( с авторизацией)
Урок №5. Парсинг с авторизацией
В этом видео я покажу, как собирать данные, для получения которых необходимо авторизоваться на сайте. Мы настроим кампанию Datacol, которая соберет заголовки тем из закрытого для незалогиненных пользователей раздела форума. Для лучшего понимания вопроса, рекомендую предварительно посмотреть видео о настройке сбора анонсов блога.
Изучив данное видео вы сможете собирать информацию, которая доступна только авторизованным пользователям сайта. Теперь вы с легкостью соберете данные с закрытого раздела форума или с закрытого сайта вашего поставщика.
Напомним, что в Datacol Вы так-же найдете уже готовые парсера:
-
Для интернет магазинов:
Для сбора контента:
Для работы с соц. сетями:
Авторизацию мы будем реализовать с помощью встроенного браузера Datacol. Для этого воспользуемся продвинутым мастером создания новой кампании.
В данном случае нам понадобиться использовать Браузер для загрузки страницы.
Чтобы браузер автоматически авторизовался при загрузке страницы, мы создадим простой сценарий имитации действий пользователя.
Для создания сценария задействуем Datacol Picker.
Обратите внимание на панель Запись действий, расположенную в правой части окна. Эта панель позволяет создавать различные сценарии, которые имитируют такие действия пользователя как: клик мышкой, ввод текста, скрол и тому подобное. Сценарий состоит из блоков. Блок представляет собой набор действий.
Для создания сценария авторизации нам понадобится всего лишь один блок. Добавляем его.
При добавлении сразу укажем название блока, чтобы в будущем было проще ориентироваться в созданном сценарии.
Теперь добавим сами действия.
Сначала определимся какие действия выполняет пользователь для авторизации на сайте.Он вводит логин, пароль и кликает на кнопку «Вход».
Чтобы имитировать ввод логина, добавим действие SET_VALUE. Для этого воспользуемся контекстным меню. Оно вызывается при клике правой кнопкой мыши на вэбэлементе, для которого создаем действие.
Теперь пропишем текст для ввода. В нашем случае это логин.
Аналогично вводу логина создадим действие для ввода пароля.
Далее добавим действие-клик по кнопке Вход.
После этого добавим действие ожидания WAIT, чтобы однозначно дождаться момента, когда сайт авторизует пользователя. Длительность задержки по умолчанию составляет 1000 миллисекунд со случайным отклонение в 500 миллисекунд в большую или меньшую сторону. Другими словами — долго ждать не придется.
Также для перестраховки, добавляем действие NAVIGATE, которое повторно осуществляет загрузку текущей страницы.
Заметим, что действия WAIT и NAVIGATE необязательны, однако они гарантируют надежную работу сценария авторизации в большинстве случаев.
Вот и все! Сценарий записан. Осталось его протестировать. Запускаем тест всего сценария.
Видим, что он быстро и успешно отрабатывает.
Нажимаем кнопку Сохранить.
Дальнейшая настройка достаточно проста. Похожие примеры подробно описаны в других видео.
Настраиваем переход по ссылкам пагинации, чтобы собрать заголовки тем со всех страниц раздела форума, а не только с первой.
Настраиваем диапазоны для сбора данных.
Настраиваем сбор данных.
Остается нажать кнопку Сохранить.
Таким образом мы завершили настройку сбора данных. Теперь закрываем мастер и переходим к тестированию.
Нажимаем кнопку “Запуск”.
Через некоторое время мы видим как появляются браузеры-загрузчики. В них происходит загрузка страниц. При этом выполняется сценарий авторизации.
Вскоре начинают появляться результаты.
После завершении работы кампании все выгруженные данные будут сохранены в Excel файл. По умолчанию он генерируется в папке Мои документы.
Как парсить сайты с авторизацией?
Как парсить сайты с авторизацией?
Я пробую написать парсер.
Если я правильно понял теорию, то логика должна быть следующая:
— авторизация;
— получить куки;
Движение по страницам
— отправить куки;
— перейти на страницу_1;
— отправить куки;
— перейти на страницу_2;
Минимальный код
Вопросы.
1. Правильно ли я понимаю логику?
2. Как сделать код с минимальным набором основных методов для простых сайтов, чтобы было видно принцип логики?
Дополнение
Для примера использовать: rabota.by/login/
Дополнение
Логин — test9631@yandex.by
Пароль — Ym3LDp1FPs
Дополнение
![]()
Анализируем.
Первым делом надо проанализировать сайт и понять как он работает. Я лично буду использовать Fiddler для отлова запросов, вы это можете делать там, где вам удобно.
И так, заходим на страницу авторизации, включаем отлов запросов, авторизуемся и смотрим на запросы.
Обычно они выглядят довольно заметно и идут на страницу вида /login или что то в этом духе.
После авторизации на сайте я поймал такой запрос: 
Смотрим сам запрос:
- Первым делом нас тут интересует тип запроса, у нас это POST на адрес /login/ .
- Далее смотрим на тип передаваемых данных Content-Type: application/x-www-form-urlencoded .
- Также может пригодиться User-Agent и некоторые Cookie .
Так, как у нас запрос с данными веб формы, то также стоит посмотреть его тело:
Здесь все довольно понятно — наши логин, пароль, запоминать или нет, имя кнопки и неизвестный параметр с логина. Проверим этот неизвестный параметр, просто проделав авторизацию еще раз. Если он изменится, то стоит искать как он формируется, если нет, то можно использовать его. В моем случае он статичный.
Ну и еще стоит посмотреть сам ответ сервера, что он отдает и что он устанавливает:
Видно, что в ответ сервер отдает нам обычный html и устанавливает пару Cookie. Тело ответа смотреть пока бессмысленно.
Пробуем отправить запрос сами.
Для этих целей отлично подходит Postman. Устанавливаем, пропускаем авторизацию (или нет) и создаем новый запрос.
Парсинг сайтов: загрузка страниц и авторизация на сайте
В этой видеоинструкции я рассказываю, как при помощи надстройки «Парсер сайтов» авторизоваться на сайте, выполнять GET и POST запросы, работать с Cookies и с браузером Internet Explorer.
Поскольку видео достаточно длинное, привожу дополнительные ссылки на это видео с переходом на соответствующие метки времени:
Во вложении к статье, — файл Excel с инструкцией, показанной в этом видео.
Комментарии
Здравствуйте, Дмитрий.
Под эти 3 сайта настроить не получится (на этих сайтах достаточно серьезная защита от роботов)
А чтобы активации докупить — в меню программы нажмите О ПРОГРАММЕ, там есть ссылка на докупку активаций.
Здравствуйте! Подскажите пожалуйста по стоимости настройки парсера на снятия данных статистики с геосервиса (Яндекс Карты, личный кабинет которого находиться на сервисе Яндекс Бизнес) и вообще возможно ли настроить парсер с авторизацией на яндекс бизнес, гугл бизнес и 2гис? И еще один вопрос как добавить еще один ПК к моему пакету? (ранее покупал у вас подписку на пользования вашим парсингом)
Игорь, не могу подсказать, не зная что и как вы там настроили.
Можем настроить под заказ, если предоставите все данные для авторизации.
Сложный двухступенчетый логин
сначала user
затем оно делает редирект получает серийник на третьем сайте и опять редирект и я ввожу пароль.
использую IE
Когда залогинен получаю pagination ссылки и почему то оно закрывает IE
второй шаг не видет страницу ибо IE закрыт.
Как предотвратить закрытие IE и удержание сессии?
Да, Иван, через таблицу замен проще всего отфильтровать нужные
Спасибо огромное, Игорь! Очень помогли! Все получилось)
А то уже начал вручную нужные id брендов в POST запрос вставлять и по отдельности скачивать((
А если мне мне все бренды нужны а только 100 из 300 например, это через таблицу замен проще всего сделать?
Иван, немного не так подуровнями воспользовались, потому и не получилось.
На выходе первого подуровня нужен массив ID брендов (на следующий подуровень они будут передаваться по одному. в переменную ничего сохранять не надо)
На втором подуровне, первым действием сохраняете текущее значение в переменную ID (туда попадет очередной ID бренда), и далее делаете всё как сейчас.
Если сами не разберётесь, — могу настроить под заказ.
Добрый день, Игорь
Не могу разобраться с одной вещью, если не сложно, подскажите где-то разбирался этот вопрос или нет. Настраиваю для себя парсинг товаров с личного кабинета. C POST запросом авторизации разобрался, все работает.
В кабинете ссылки на бренды представлены на одной странице в виде раскрывающихся списков со ссылками вида a href=»#», нашел, что на странице они в виде id, получил массив ссылок и сохранил массив в переменную.
На следующем уровне создаю POST запрос для «раскрытия» списка товаров и в действии «Добавить передаваемое POST-значение» в поле значение указываю переменную с массивом id брендов.
Но парсер берет только первое значение из массива.
Пробовал добавлять действие «Увеличить значение счетчика», но оно только прогружает одни и те же товары из первого по списку бренда многократно, по количеству всех брендов.
Уже голову сломал как сделать чтобы все по очереди бренды открывались, 3 дня пытаюсь, но все никак. Надстройка естественно куплена, и не только эта.
Доброго времени суток!
Не получилось настроить с помощью видео «Парсинг сайтов: загрузка страниц и авторизация на сайте» парсинг телефона, который скрыт под кнопкой, с помощью POST запроса. Вместо +7 095 XXX XX XX, +7 082 XXX XX XX и т.д. теперь выдает номер в открытом виде, но всегда одинаковый, тот на который ,был настроен POST запрос. Подскажите пожалуйста где копать.
Использовал команды:
Открыть HTTP соединение
Добавить заголовок запроса (несколько)
Добавить передаваемое POST-значение
Отправить HTTP и получить ответ
Заранее спасибо.
Да, всё это можно.
По комментариям на моём сайте — пару раз слышал о проблеме такой, но пока не могу решить её (очень редко такое, и не знаю с чем связано). Попробуйте с другого браузера.
Здравствуйте! Везде искал, но не нашел. На сайте с которого нужно спарсить информацию, все страницы подгружаются с помощью java script, при этом url один и тот же. Загрузка страницы за счет выбора . Возможно ли вашей программой спарсить все данные, подгружая этот java script?
И еще. пока пытаюсь верно ввести капчу, чтобы оставить этот комментарий, проходит больше 10 минут.
Тем временем зашел в код страницы, удалил лишние br и смог понять что написано.
Переключение прокси будет в следующем обновлении программы (через несколько дней)
Многопоточность давно реализована.
Возможно ли изменение прокси при получения определенной страницы? (капчи). Появится ли и когда?
Планируется ли добавить многопоточность?
Спасибо
Это http basic authentication (она же http авторизация)
Там передаётся в каждом запросе заголовок запроса Authorization
со значением вида Basic aBcDeF123465==
Посмотрите, какое значение передаётся в заголовке Authorization в браузере после авторизации,
и добавьте в парсер (в набор действий Parser_Start) одно действие — Добавить заголовок запроса
(с параметром Применять для всех запросов = ДА)
Поработал с триал версии- так и не смог понять как выполнить вход на сайт если сайт закрыт простым методом ( паралем в .htacsses ) и когда появляется просто форма запроса логина и пароля . Скоро конец триала а так и не потестировал
Здравствуйте, Наталья
Да, можем настроить всё под заказ
(насчёт Word — вряд ли, а вот в Excel — запросто. Если надо все же в Ворд, это дополнительный макрос надо будет заказывать, потому что парсер выводит данные только в Excel)
Заказы на парсер (по каждому из сайтов) принимаются в таком виде
http://excelvba.ru/programmes/Parser/order
Добрый день! Не могу разобраться в программе, и не понимаю сможет ли она мне помочь (я в этом блондинка). Мне необходимо автоматически сгружать (собирать) конкретную информацию с нескольких сайтов (и желательно в Word, а не exel), например с сайта справочная информация с сайта росреестра об объекте недвижимости, с сайта реформа жкх данные о доме и пр. Если это возможно, то можно ли при покупке программы это чудо установить удаленно?
Меню Дополнительно — Общие настройки программы — вкладка Captcha
Там задаётся API ключ
ок. Понял.
1) Напишите хотя бы куда нужно записать API KEY (с сайта recaptcha.com)
2) и нужно ли делать что-то чтобы действие «решить Google Captcha v.2» видело этот API KEY?.
Где это место в программе «в общих настройках программы нужно задать API-ключ сервиса»?
Спасибо
Могу настроить под заказ
По действию «решить google captcha v.2» пока инструкции нет, а расписывать примеры её использования — времени много займет
Спасибо. Извиняюсь за схожее сообщение (предыдущее долго не появлялось)
Как использовать «решить google captcha v.2» в рамках предложенного в видео способа POST запросов? Т.е. как к тому что в этом видео рассказано добавить решение капчи.
Сейчас я использую «открыть страницу в Internet Explorer», при помощи чего авторизуюсь, но парсер работает очень медленно, плюс по непонятным причинам он пропускает порой страниц по 20 — 50 (при том что у меня всего 300 страниц, с которых надо собрать ссылки)
Здравствуйте. Нужно перед сбором данных с сайта http://www.archello.com на нем один раз авторизоваться, но во время авторизации каждый раз нужно вводить гугл капчу.
1) способом указаным в видео не получается выполнить авторизацию. Возможно ли при помощи POST запросов авторизоваться в нашем случае ?
2) если же нужно использовать действие «решить google captcha v.2», как его использовать в рамках предложенного в видео способа запросов?
Сейчас я использую «открыть страницу в Internet Explorer», при помощи чего авторизуюсь, но парсер работает очень медленно, плюс по непонятным причинам он пропускает порой страниц по 20 — 50 (при том что у меня всего 300 страниц, с которых надо собрать ссылки)
1) нет, без ввода капчи никак
2) нет (да и зачем? специально для этого же действие сделано)
3) без браузера и без ввода капчи — скорее всего, никак. по крайней мере, я не в курсе, как сделать
Здравствуйте. Что делать если при авторизации на сайте каждый раз нужно вводить гугловскую рекапчу. Авторизоваться нужно только один раз в начале.
1) Решить это способами указыными в этом видео не получится?
2) Возможно ли обойтись без действия «Решить Google Captcha v.2»?
3) Каким образом авторизоваться на сайте в этом случае (если не использовать действия «открыть страницу в Internet Explorer»?
Добрый день! Ответил Вам на почту.
Сколько стоит парсинг Я.Маркета. По категории смартфонов.
Определяем 10.000 топовых смартов и угоняем их цены, описание, фотки. Далее нужна будет актуализация цен на товары, которые парсер сграббил. Я так понимаю, что маркет, это не самая простая задача для парсинга, будет ли там все сделано под ключ, с обходом капч и и т.д