Задание 3. Эмпирическая функция распределения.
Построить график эмпирической функции распределения с подогнанной ожидаемой функцией распределения.
Теоретические основы.
См. стр. 31-32 пособия [4].
Вычисления.
Если попытаться построить ЭФР средствами Excel, упорядочив сначала данные и сопоставив затем каждому упорядоченному значению x(k) значение 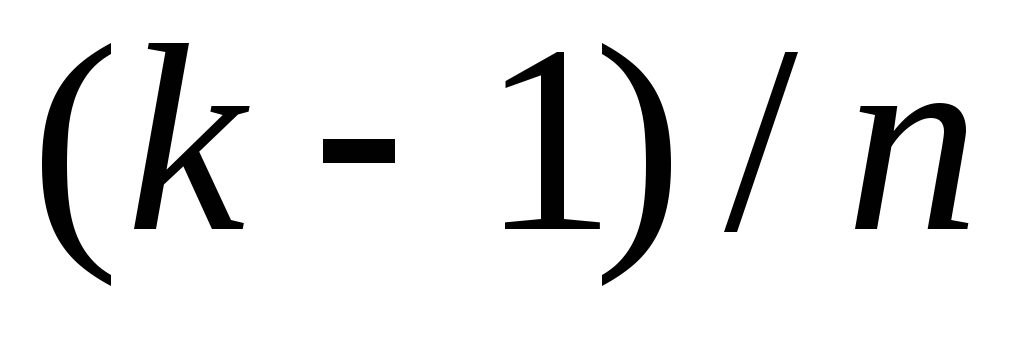 , то вместо горизонтальных получим наклонные ступеньки. Чтобы избежать этого недостатка, можно каждое значение вариационного ряда повторить дважды, при этом первому из этих значений сопоставить ЭФР
, то вместо горизонтальных получим наклонные ступеньки. Чтобы избежать этого недостатка, можно каждое значение вариационного ряда повторить дважды, при этом первому из этих значений сопоставить ЭФР , а второму
, а второму  .
.
Вычисление нормальной функции распределения описано ниже в главе “Встроенные функции Excel”. Здесь кратко только скажем, что для этого можно использовать функцииНОРМРАСПиНОРМСТРАСПиз категории “Статистические”.
Функция распределения экспоненциального закона вычисляется с помощью простой функции EXP.
Кроме того, предполагается, что уже вычислены среднее значение и дисперсия выборки (задание 1).
Пример.

Порядок вычислений.
Скопировать исходные данные в буфер обмена;
перейти на лист “ЭФР” и, установив курсор в ячейку A3, вставить данные из буфера обмена;
повторить процесс восстановления данных, начиная с ячейки A104
установить курсор в ячейку A104;
вставить данные из буфера обмена
– всего получится 202 значения с 3-й по 204-ю ячейки;
упорядочить значения в столбце A
кликнуть мышкой по кнопке  ;
;
ввести в ячейку B3 формулу
– функция «СТРОКА» возвращает номер строки указанного аргумента, то есть в данном случае в ячейке B3 получится значение (3-1)/202-1/101 = 0;
ввести в ячейку B4 формулу
– получится значение (3-1)/202 = 1/101;
выделить обе ячейки B3 и B4 и скопировать их параллельно всем данным до ячейки B204
– в последней ячейке должно получиться значение 1;
добавить в ячейку A2 значение, на единицу меньшее значения ячейки A3 и сопоставить ему значение 0 в ячейке B2;
добавить в ячейку A205 значение, на единицу большее значения ячейки A204 и сопоставить ему значение 1 в ячейке B205.
Ввести формулы вычисления нормального распределения:
в ячейки F4, F5 (те, которые скрыты графиком) скопировать среднее и стандартное отклонение, соответственно
в ячейку C2 ввести формулу нормального распределения
в ячейку D2 ввести формулу вычисления расхождения между ЭФР и ожидаемой функцией распределения
скопировать обе ячейки C2 и D2 вплоть до 205-й строки;
вычислить максимальное расхождение, например, в ячейке F6
Теперь уже можно рисовать графики:
выделить все значения в ячейках A2:C205;
вызвать “Мастера Диаграмм”;
выбрать «Точечную» диаграмму – без маркеров со сглаживающей линией (третья по порядку среди точечных диаграмм);
при выборе представления диаграммы, после двух нажатий кнопки  , удалить “Легенду” и добавить “Заголовок по оси Х”:
, удалить “Легенду” и добавить “Заголовок по оси Х”:
МАКСИМАЛЬНОЕ РАСХОЖДЕНИЕ D=…
(указав здесь полученное значение Δ из ячейки F6);
 ;
;
установить параметры диаграммы, как в примере.
Замечание. Если бы параметры нормальной модели не оценивались по выборочным данным, а были бы в точности равны этим оценкам, то при полученном здесь расхождении Δ=0,097 гипотезу нормальности следовало бы принять с критическим уровнем значимости > 0,20 (см. таблицу 6.2 сборника таблиц [1]). Это надо воспринимать как хороший знак и не более того. Если неизвестные значения параметров оцениваются по выборке, то критический уровень значимости становится зависящим от неизвестных параметров и трудно ожидать, что даже в предположениях гипотезы критерий будет иметь приемлемый размер.
Контрольные вопросы.
Сформулируйте статистическую задачу.
Что такое вариационный ряд?
Дайте определение эмпирической функции распределения?
Почему некоторые ступеньки ЭФР высокие, а некоторые низкие?
Почему одни ступеньки ЭФР длинные, а другие короткие?
Постройте ЭФР по следующим данным: 1; 2; 1; 3; 1; 5; 1; 3.
Выпишите формулу для функции распределения нормального закона (равномерного, экспоненциального).
Можно ли утверждать, что ЭФР является состоятельной оценкой истинной функции распределения? Что сие означает?
Можно ли утверждать, что ЭФР является несмещенной оценкой истинной функции распределения? Что сие означает?
Докажите несмещенность ЭФР.
Можно ли по значению максимального расхождения между ЭФР и ожидаемой функцией распределения принять или отвергнуть гипотезу о виде истинной функции распределения?
Эмпирическая функция распределения в excel как построить
Построим эмпирическую функцию распределения для нашей задачи. Чтобы было нагляднее, отложу варианты и их количество на числовой оси: 
На интервале – по той причине, что левее ЛЮБОЙ точки этого интервала вариант нет. Кроме того, функция равна нулю ещё и в точке . Почему? Потому, что значение определяет количество вариант (см. определение), которые СТРОГО меньше двух, а это количество равно нулю.
Накопленные относительные частоты удобно заносить в отдельный столбец таблицы, при этом алгоритм вычислений очень прост: сначала сносим слева частоту (красная стрелка), и каждое следующее значение получаем как сумму предыдущего и относительной частоты из текущего левого столбца (зелёные обозначения): 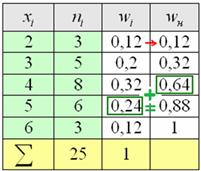
Вот ещё, кстати, один довод за вертикальную ориентацию данных – справа по надобности можно приписывать дополнительные столбцы.
а её график представляет собой ступенчатую фигуру: 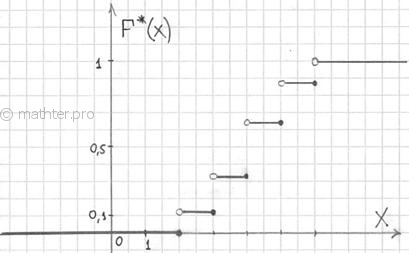
Эмпирическая функция распределения не убывает и принимает значения лишь из промежутка , и если у вас вдруг получится что-то не так, то ищите ошибку.
Дано статистическое распределение совокупности: 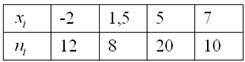
Как построить эмпирическую функцию распределения в excel
Из таблицы n=40, т.е.
n=4+10+6+8+7+5=40
Вычислим функцию распределения выборки 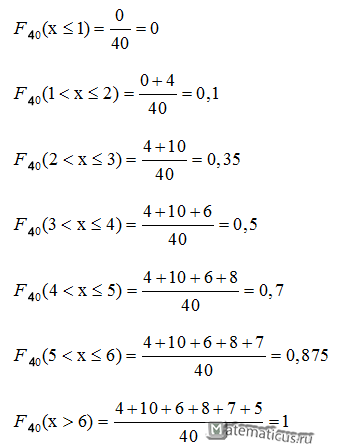
4. Рассмотрим любой из критериев оценки качеств педагога-профессионала, например, «успешное решение задач обучения и воспитания». Ответ на этот вопрос анкеты типа «да», «нет» достаточно груб. Чтобы уменьшить относительную ошибку такого измерения, необходимо увеличить число возможных ответов на конкретный критериальный вопрос. В табл. 1 представлены возможные варианты ответов.
Обозначим этот параметр через х. Тогда в процессе ответа на вопрос величина х примет дискретное значение х, принадлежащее определенному интервалу значений. Поставим в соответствие каждому из ответов определенное числовое значение параметра х (см. табл. 1).
VII Международная студенческая научная конференция Студенческий научный форум — 2015

ВАРИАЦИОННЫЕ РЯДЫ. ВЫБОРОЧНАЯ ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ
Краткая теория
Для решения задач, связанных с анализом данных при наличии случайных непредсказуемых воздействий, разработан математический аппарат ‒ математическая статистика, что позволяет выявлять закономерности на основе случайностей, делать на их основе обоснованные выводы и прогнозы.
Важнейшими понятиями математической статистики являются понятия генеральной совокупности и выборки.
Генеральной совокупностью наблюдаемого признака (случайной величины) Х называют множество всевозможных значений, принимаемых наблюдаемым признаком Х.
Часть отобранных объектов из генеральной совокупности называется выборочной совокупностью, или выборкой. Результаты измерений изучаемого признака nобъектов выборочной совокупности порождают nзначений х1, х2, … , хn случайной величины X . Число nназывается объемом выборки.
Выборку можно рассматривать двояко:
а) как случайный вектор длины n, каждая компонента которого имеет такое же распределение, как и наблюдаемый признак;
б) как на результаты измерений, т.е. набор n чисел.
Случайная величина Х называется дискретной случайной величиной, если она принимает свое значение из некоторого конечного фиксированного набора, например, случайная величина Х ‒ число появления шестерки при двух бросках игрального кубика
Случайная величина Х называется непрерывной случайной величиной, если она принимает любое значение из некоторого интервала (в том числе ‒ ∞ и +∞), например, рост человека.
После получения выборки имеем данные, которые представляют собой множество чисел, расположенных в беспорядке. Анализ таких данных весьма затруднителен, и для изучения скрытых закономерностей их подвергают определенной обработке.
Простейшая операция – ранжирование опытных данных, результатом которого являются значения, расположенные в порядке неубывания. Если среди элементов встречаются одинаковые, то они объединяются в одну группу. Значение случайной величины, соответствующее отдельной группе сгруппированного ряда наблюдаемых данных, называется вариантом, а изменение этого значения – варьированием. Варианты будем обозначать строчными буквами с соответствующими порядковому номеру группы индексами x (1) , x (2) , . x(N) , где N – число групп. При этом x (1) < x (2) < . < x(N).
Численность отдельной группы сгруппированного ряда данных называется частотой ni , где i – индекс варианта, а отношение частоты данного варианта к общей сумме частот называется частностью (или относительной частотой) и обозначается ωi , i = 1, . N , т.е.
при этом j=1Nnj=n ‒ объему выборки.
Дискретным вариационным рядомназывается ранжированная совокупность вариантов x( i ) с соответствующими им частотами niили частностями ωi .
Если число возможных значений дискретной случайной величины достаточно велико или наблюдаемая случайная величина является непрерывной, то строят интервальный вариационный ряд, под которым понимают упорядоченную совокупность интервалов варьирования значений случайной величины с соответствующими частотами или частностями попаданий в каждый из них значений случайной величины.
Как правило, частичные интервалы, на которые разбивается весь интервал варьирования, имеют одинаковую длину Δ, которая может быть вычислена по следующей формуле
где R – размах варьирования (изменения) случайной величины;
xmax , xmin – наибольшее и наименьшее значения исследуемой случайной величины;
N – число частичных интервалов группировки.
Некоторые авторы рекомендуют пользоваться следующими эмпирическими формулами для определения числа интервалов:
N = 1 + 3,322 . lg(n) ‒ формула Стерджеса.
В рекомендациях по стандартизации Р 50.1.033-2001 "Прикладная статистика. Правила проверки согласия опытного распределения с теоретическим. Часть I. Критерии типа хи-квадрат" рекомендует следующие значения N в зависимости от объема выборки n: