Любительский перевод игр: анатомия процесса, часть первая
 Любительская локализация — явление, затронувшее многих игроманов, и порой даже сыгравшее не последнюю роль в формировании их интересов и отношения к игровой индустрии в целом. Наверное, благодаря тому, что оно издавна преследовало в основном благие цели, у большинства любителей интерактивных развлечений при его упоминании возникают преимущественно положительные ассоциации, а порой даже и ностальгические эмоции.
Любительская локализация — явление, затронувшее многих игроманов, и порой даже сыгравшее не последнюю роль в формировании их интересов и отношения к игровой индустрии в целом. Наверное, благодаря тому, что оно издавна преследовало в основном благие цели, у большинства любителей интерактивных развлечений при его упоминании возникают преимущественно положительные ассоциации, а порой даже и ностальгические эмоции.
В прошлый раз я излагал свой взгляд на явления как любительской, так и официальной локализации. Поскольку нашлись люди, которым эта тема близка или интересна, а также не обошлось и без желающих побольше узнать о технических деталях процесса, то мне ничего не остаётся, как об этом рассказать, пусть и в несколько специфичном стиле.
На картинке изображён логотип российского ромхакинг-сообщества по версии проекта Russian Romhacking.
Перед прочтением
Прежде всего, хочу сказать, что я обозреваю только тот опыт, который я имел возможность наблюдать или практиковать лично. Так что далеко не факт, что все неофициальные локализаторы придерживались описанных ниже методик и уж тем более это касается упомянутого инструментария. В первую очередь я буду рассказывать о подходе, который применял сам. Я считаю, что он в достаточной степени показателен и выигрывает у многих других методик, практикуемых иными энтузиастами. Впрочем, понятие методики тут довольно расплывчато и у многих оная отсутствует вовсе.
На всякий случай упомяну и о том, что мои действия, на которых основывается весь описанный опыт, никогда не преследовали корыстных целей и не носили деструктивный характер. Всё это делалось, в первую очередь, ради самого процесса и саморазвития, и было просто моим хобби.
Честно говоря, я долго думал, как именно структурировать статью и что именно в неё включить — сперва я хотел рассказать не только о технических особенностях процесса, но и расписать суть социальной составляющей. Однако, в какой-то момент я поймал себя на мысли, что из-за обилия критики статья пригодна скорей для несколько другого места, нежели для Хабра — корить большинство непрофессионалов за проявление непрофессионализма и отсутствие стремления к совершенствованию техник несколько цинично.
В итоге я решил описать только техническую часть и только в общем виде — подробного описания с примерами хватило бы на десяток таких статей, а то и на очередную бесполезную книгу, так что пока отложим это в долгий ящик. Несмотря на это, статья даже в незавершённом виде получилась довольно большая, и я решил разбить её на несколько постов. Насколько она вышла интересной или полезной — судить вам.
Техническая сторона вопроса
- Обратная разработка — процесс, многим более известный под термином реверс-инжиниринг. Игру исследуют, разбирают форматы, определяют алгоритмы, находят нужные данные.
- Извлечение ресурсов — преобразование необходимых для перевода ресурсов в удобный для редактирования вид. Текст — в текстовые файлы, графику — в распространённые форматы изображений и т.п. Всё это может осуществляться как вручную (неисповедимы пути дилетантские), так и посредством инструментария — в лучшем случае написанного самими переводчиками.
- Перевод и редактирование — самая суть процесса. Результат именно этих трудов оценивают игроки.
- Сборка перевода — конвертирование ресурсов обратно в игровые форматы и замена ими оригинальных данных игры. В идеале этот процесс должен заключаться только лишь в запуске инструментария для автоматической сборки, но, к сожалению, у большинства переводчиков он заключается в ручном редактировании каждый раз при необходимости внести изменения.
- Тестирование — обязательный этап, позволяющий выявить многие ошибки и порой улучшить перевод. Среди вожделеющих поиграться в любимую игру на родном языке отбираются наиболее ответственные и грамотные, затем им вручается бета-версия перевода с просьбой воспроизвести как можно больше игровых ситуаций. Да и свежий взгляд со стороны — всегда хорошо, многие ошибки команда может просто не видеть.
Если углубляться в детали, то не существует одинаковой для всех случаев последовательности действий, которую необходимо выполнить, чтобы подготовить игру к переводу. Так же не существует универсальных методов, с помощью которых можно выполнить те или иные шаги. По сути это всегда импровизация, но всё же есть список задач, которые встречаются практически всегда.
Я постараюсь выделить наиболее часто возникающие и важные задачи, рассказав про каждую из них отдельно. В качестве платформы не будем рассматривать ничего конкретного — т.е. всё описанное ниже справедливо как для PC, так и для любой другой платформы — будь то любая из PlayStation, XBOX, да хоть Sega или Dendy (NES).
Поскольку в данном контексте большинство задач по реверс-инжинирингу можно решить средствами отладчика или дизассемблера, я буду упоминать о них только в отдельных случаях.
Определение кодировки текста
 Казалось бы, вполне тривиальная задача — определить, в какой кодировке хранится текст. И в большинстве случаев это и правда не составляет труда, но и здесь мысль разработчиков не знает предела.
Казалось бы, вполне тривиальная задача — определить, в какой кодировке хранится текст. И в большинстве случаев это и правда не составляет труда, но и здесь мысль разработчиков не знает предела.
Далеко не всегда выводимый текст хранится именно как текст, чаще это просто набор индексов символов в шрифте, которые необходимо отобразить. Нередко их делают совместимыми или частично совместимыми с какой-либо кодировкой, преимущественно это первые 256 символов юникода. Как бы там ни было, всё равно надо установить точное соответствие между символами и их кодами. Впрочем, в современных играх всё чаще вместо индексов используют обыкновенные кодировки и сериализуют текст в форматы вроде XML — о производительности давно никто особо не задумывается.
Для представления кодировки используются «таблицы кодировки» — текстовые файлы, где в каждой строке некой последовательности байт сопоставлена определённая последовательность символов. Выглядит это примерно так:
Например, текст «Hero obtains Item!» был бы закодирован следующим образом: « 1E 20 20 6F 62 74 61 69 6E 73 20 1E 21 21 ». Однако, если оказывается, что полученная кодировка в достаточной мере совместима с какой-либо пригодной для использования кодировкой (скажем, с юникодом), то таблица в общем-то не нужна и этот шаг можно пропустить.
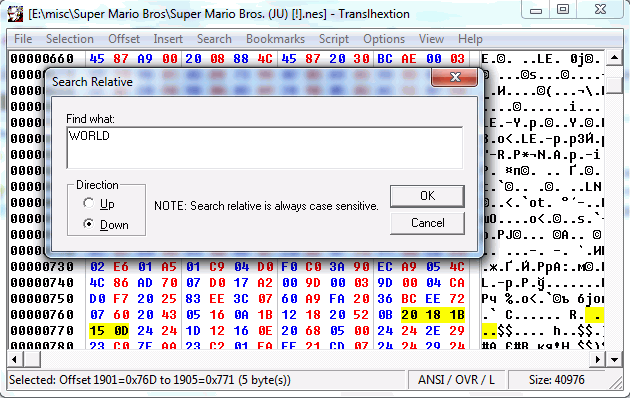
Самым распространённым способом определить кодировку и найти текст является так называемый «относительный поиск» (relative search). Суть его в том, что ищутся не какие-то абсолютные значения: критерием поиска служит разница между значениями искомой последовательности. Для этого достаточно взять какое-нибудь не слишком короткое слово, встречающееся в игре, и будут найдены все последовательности байт, в которых разница между элементами равна разнице между кодами символов исходного слова.
Например, для слова «WORLD» найдётся как последовательность «57 4F 52 4C 44», так и «77 6F 72 6C 64». Да хоть «13 0B 0E 08 00»! Найдя такие последовательности и убедившись, что это именно закодированное слово, мы может запросто составить таблицу кодировки. Самой известной программой, обладающей таким функционалом, является хекс-редактор Translhexion. Имеется и куча специализированных утилит вроде Search Relative. Да и многие из технически грамотных переводчиков писали для себя подобные утилиты.
Типичный случай: если сравнить данный скриншот с полотном шрифта, то видно, что найденная последовательность — это индексы символов в шрифте: 
В целом, такая методика хоть и применима в подавляющем большинстве случаев, но без некоторых ухищрений действует далеко не всегда. Ведь никто не гарантирует, что коды символов в кодировке идут в том же порядке, что и буквы в алфавите.
Например, в переизданиях многих частей Final Fantasy для GameBoy Advance и Nintendo DS символы в шрифте отсортированы по частоте встречаемости, а для кодирования индексов используется способ, напоминающий UTF-8. Т.е. любой символ с кодом больше 0x7F кодируется двумя байтами, в то время как первые 128 символов кодируются всего одним:
Более суровый случай на моей памяти — это Final Fantasy: 20th Anniversary Edition для PlayStation Portable. Для каждой локации там существовал свой шрифт, свой текст и, как следствие, своя кодировка. Шрифт состоял только из встречаемых в тексте символов, которые так же были упорядочены по частоте встречаемости. Впору бы использовать нейронные сети для распознавания кодировки каждой локации, но благо хватило попиксельного сравнения масок прозрачности символов.
В этих случаях относительный поиск тоже подходит для решения задачи, но необходимо искать не по разнице между номерами букв, а по разнице между индексами их символов в шрифте. Т.е. можно просто записать последовательность индексов — это вполне сгодится для такого поиска.
Как и другие ресурсы, текст может быть запакован или зашифрован. В таком случае поиск среди данных игры поможет только в случаях, когда в запакованных или зашифрованных данных всё же присутствуют хотя бы обрывки слов (такое часто бывает при использовании алгоритмов вроде LZ77 или RLE). Поэтому выходом может быть поиск в дампе оперативной памяти. Возможность добычи дампа зависит от платформы, для которой делается перевод. Для эмулируемых консолей и PC трудностей быть не должно — есть куча средств для получения доступа к памяти игры. А вот в других случаях нужна возможность во время игры запустить на консоли необходимый код, для чего, как правило, консоль должна быть «взломана». Про методики разбора самих алгоритмов я расскажу в следующей статье.
Поиск указателей
 Если данные хранятся в сериализованном виде, этот пункт можно смело пропускать. Если же ресурсы хранятся в исполняемом файле (что практически всегда верно для консолей, использующих картриджи) в готовом для использования виде, то, как правило, на каждый такой ресурс есть указатель. Естественно, текста это тоже касается. Тем более, чтобы стало возможным свободно модифицировать текст, надо найти все указатели и ссылки на каждую из изменяемых строк.
Если данные хранятся в сериализованном виде, этот пункт можно смело пропускать. Если же ресурсы хранятся в исполняемом файле (что практически всегда верно для консолей, использующих картриджи) в готовом для использования виде, то, как правило, на каждый такой ресурс есть указатель. Естественно, текста это тоже касается. Тем более, чтобы стало возможным свободно модифицировать текст, надо найти все указатели и ссылки на каждую из изменяемых строк.
Забавно, что для ряда новичков понимание концепции указателей является одним из самых сложных препятствий в освоении искусства любительского перевода. Как правило, такие люди долгое время не утруждают себя технической стороной процесса и переводят текст так, чтобы он вмещался в длину оригинальной строки. Ещё более забавно то, что для совершенствования навыков многие из них в итоге осваивают программирование. Стоило бы это сделать в обратном порядке — и всё было бы гораздо проще. Хотя стоит заметить, что люди, ставшие полноценными IT-специалистами, часто уходят с этой сцены и начинают заниматься вещами посерьёзней.
Очень часто все указатели хранятся в едином месте, которое обычно называют «таблицей указателей» — оно представляет собой массив из указателей или элементов, их содержащих. В таких случаях игра обращается к строкам по индексам, по которым, в свою очередь, из такой таблицы берётся указатель. Тогда достаточно найти указатель на любую строку в блоке текста — и таблица найдена!
Но не всё так просто… вернее, не всегда всё так просто. Одна из сложностей, мешающих искать указатели, называется «разницей смещений». Дело в том, что указатель может быть не только абсолютным (указывающим на логический или физический адрес ресурса), но и относительным (указывающим на смещение относительно какого-то адреса). Или же, скажем, на старых дисковых консолях вроде PlayStation данные часто хранятся в подготовленном для загрузки в память виде — т.е. пока они лежат в файле, невозможно просто так вычислить, на что будет указывать указатель, не зная адреса, куда будет происходить загрузка.
Пока не известна разница смещений, нельзя однозначно вычислить указатель. Поэтому первым делом обычно проверяют наличие таблицы — для этого может помочь тот же самый относительный поиск. В качестве элементов искомой последовательности берутся расстояния между началами строк — разница между значениями указателей будет точно такой же. Если таблица не находится — поиск повторяют, перебирая возможные размеры указателей и возможные расстояния между ними (если помимо указателей в таблицах содержатся другие данные).
Однако, не всё коту масленица — некоторые игры обращаются к строке прямиком по указателю без использования таблиц. Тогда уже разницу вычисляют как могут: например, путём визуального анализа данных или с помощью дизассемблера. Есть ещё один «дедовский» способ: участки данных «поганят», подменяя байты, и смотрят, отразилось ли это как-нибудь на игре. Таким образом, сокращая диапазон поиска методом исключения, можно локализовать участок кода, отвечающий за вывод какой-либо строки, и найти указатель. Для таких целей даже существуют целые специализированные инструменты вроде Поганка или Visual Poganka.
Без использования таблиц указатели будут раскиданы по всему пространству кода в исполняемом файле, и порой далеко не в единичном экземпляре. Если текст складирован в одном месте, эту проблему можно решить, просканировав его и найдя все указатели на начало каждой строки. И в большинстве случаев это не составляет труда — из-за особенностей адресного пространства вероятность коллизии значения указателя с другим значением минимальна (например, память адресуется в диапазоне 0x08000000-0x09FFFFFF или секция данных начинается с адреса 0x00472000).
Но бывает и так, что память адресуется менее удачным для переводчика способом: например, начиная с нулевого адреса. И тогда коллизий уж точно не избежать… Придётся вручную проверять каждое значение, встречающееся более одного раза, на предмет того, является ли оно указателем или же данными с таким же значением. А если ещё и сам текст разбросан по файлу, то автоматизировать процесса поиска указателей можно разве что написав какой-нибудь скрипт или плагин к IDA Pro.
Так или иначе, терпение и труд всё перетрут. Достаточно найти указатели один раз и дальше с этой задачей можно не заморачиваться, переходя к следующему шагу.
Извлечение текста
 Способ «выемки» текста по таблицам зависит от уровня организации переводчиков. Так, самые неорганизованные ребята (как правило, новички) вообще не заморачиваются и переводят текст прямо в хекс-редакторах. Чуть посерьёзней — используют для извлечения программы-всёделалки вроде PokePerevod или тот же Translhexion. Люди с более глубокими познаниями используют более специализированные средства автоматизации вроде Kruptar. Самые продвинутые специалисты обычно пишут для этого свои скрипты или инструменты, что и вовсе позволяет им контролировать процесс полностью.
Способ «выемки» текста по таблицам зависит от уровня организации переводчиков. Так, самые неорганизованные ребята (как правило, новички) вообще не заморачиваются и переводят текст прямо в хекс-редакторах. Чуть посерьёзней — используют для извлечения программы-всёделалки вроде PokePerevod или тот же Translhexion. Люди с более глубокими познаниями используют более специализированные средства автоматизации вроде Kruptar. Самые продвинутые специалисты обычно пишут для этого свои скрипты или инструменты, что и вовсе позволяет им контролировать процесс полностью.
В любом случае, в чаще всего процесс сводится к преобразованию потока байт в пригодный к чтению и редактированию вид, используя информацию о кодировках, бинарных тегах и применяемом игрой байткоде, если он имеет место быть.

Но вовсе не факт, что разработчики изначально хранили текст отдельно и в чистом виде. Очень часто он является лишь частью других данных — карт уровней, сценариев и т.п. Если кто-нибудь знаком с игровыми редакторами вроде TES Construction Set, то он поймёт, о чём речь. В таких случаях, поскольку текст хранится совместно с другими данными, необходимо «распарсить» их структуру и аккуратно извлечь текст и прочую необходимую информацию — например, иногда помимо текста необходимо изменять ещё и такие данные, как координаты его вывода и размеры диалоговых окон. Порой для этого пишутся целые редакторы, которые частично воспроизводят функционал средств, которыми пользовались разработчики.
В целом, к извлечению текста у меня свой подход. Начнём с того, что стандартный формат таблиц кодировки довольно прост и не покрывает все случаи. Например, иногда важно знать, какие последовательности байт служат для индикации конца текста, переноса строки или очистки экрана. Также в игре могут быть использованы, к примеру, коды разметки, где определённая часть битов выступает в качестве параметра. В таком случае пришлось бы записывать всё это дело примерно так:
Поэтому существует множество надстроек над этим форматом — я даже разрабатывал своё собственное расширение, которое позволяло описать даже коды разметки и прочие байты с параметрами, а также поддерживало директивы вроде include (удобно, когда есть таблицы для разных языков, но в них есть одинаковые элементы).
Рассмотрим пример таблицы в расширенном формате:
Несмотря на некоторую кашу в таблице, на выходе получался довольно опрятный для игрового скрипта текст:
О роли опрятности будет сказано чуть ниже, а сейчас рассмотрим проблему байткода. В некоторых играх используются даже свои скриптовые языки, и хорошо, если текст в них используется в качестве внешних ресурсов. Но порой всё же приходится разгребать мешанину из текста и кода.
Если невозможно отделить код от текста, то обычно для каждой инструкции придумывают мнемонику и форму записи исходя из её назначения. Составив базу с информацией о всех инструкциях, несложно написать транслятор. Но чтобы не писать такие вещи каждый раз, я придумал ещё одно расширение для таблицы кодировки.
Инструкция в байткоде идентифицируется по определённым значениям некоторых битов. Допустим, у нас есть две инструкции размером с байт. У одной инструкции биты с первого по четвёртый равны 0101 , т.е. выглядит она как 0101nnnn ; у другой — первые два бита равны 11 , т.е. запишем её как 11nnnnnn . Самым простым способом идентифицировать инструкцию является сравнение по маске — т.е. надо произвести логическое умножение опознаваемого кода на битовую маску, выделив тем самым нужные биты, и сравнить результат с эталонными данными (далее по тексту будем называть это идентификатором инструкции). Таким образом, для первой инструкции маской будет 11110000 , поскольку мы должны взять только первые 4 бита, а идентификатором, соответственно, будет 01010000 . Для второй инструкции и маска, и идентификатор равны 11000000 .
Суть расширения в том, что для инструкций можно прямо в таблице записать битовые маски и идентификаторы, которые нужны для их определения и чтения параметров. А вместо простой последовательности символов можно использовать специальную строку, которая будет говорить о том, как форматировать и конвертировать текстовое представление инструкции обратно в байткод. Т.е. по таким таблицам можно было бы даже примитивно дизассемблировать исполняемые файлы.
Форма такой записи инструкции в таблице кодировки такова:
Где OpcodeMask — маска, OpcodeID — идентификатор, ValueMasks — перечисленный через запятую список битовых масок параметров, а FormatString — строка для форматирования текстового представления инструкции и конвертации её обратно в байткод (представляет из себя модифицированный эквивалент форматных строк для функции printf).
Например, у нас есть инструкция вида 1010iiii cccccccc , показывающая во всплывающем окне цвета с предмет с номером i. Назовём её «popup(item, color)». Маска данной инструкции равна 11110000 00000000 , что в шестнадцатеричном представлении будет F000 . Идентификатор инструкции будет равен 10100000 00000000 , т.е. C000 , а маски параметров — 00001111 00000000 и 00000000 11111111 , то бишь 0F00 и 00FF соответственно.
Пусть у нас имеется такой вот закодированный текст:
0000: 4F 62 74 61 69 6E 65 64 20 61 6E 20 69 74 65 6D Obtained an item
0010: 21 C1 0F 0A 4E 6F 77 20 79 6F 75 20 63 61 6E 20 !##\nNow you can
0020: 6F 70 65 6E 20 74 68 65 20 64 6F 6F 72 2E open the door.
Попробуем декодировать его с помощью таблицы, в которой есть такая запись:
Получаем такой результат:
Не совсем удачно сочетается с текстом. Поэтому попробуем прибегнуть к помощи тегов. Пусть это будут XML-теги:
Уже гораздо лучше:
Но ещё лучше было бы, если бы вместо «магических констант» мы видели текстовое представление параметров. Для этого я ввёл возможность объявления перечислений в виде:
Допустим, такая инструкция применяется только для трёх предметов: бомбы с номером 0, ключа с номером 1 и монеты с номером 10:
Как видно, заодно и для цвета я применил более привычную запись. Конечно, глупо поступать таким образом с восьмибитным представление цвета, но это лишь пример, взятый из головы для наглядности.
Дальше нам остаётся только включить подсветку тегов и можем получить более-менее читабельный текст:
Если семантика инструкций не так важна (т.е. перевод не подразумевает их редактирования), то лучше прибегнуть к более краткой записи, а то в некоторых местах кода может получиться больше, чем текста. Например, так:
Для инструкций с ровно одним параметром я предусмотрел укороченную форму записи. Ниже следует две эквивалентных по смыслу строки:
Как видно из записи, вопросительными знаками я выделил биты параметра, остальные биты считаются единичными битами маски, а идентификатор получается путём замены вопросительных знаков на нули. К сожалению, такая запись возможна только для инструкций, где размеры параметра и идентификатора кратны четырём битам, т.е. размеру одного шестнадцатеричного символа.
Представление текста
 Это одна из самых важных частей процесса, потому что извлечённый текст попадёт прямиком к переводчикам, и от того, насколько он опрятен, зависит не только продуктивность их работы, но и количество структурных и семантических ошибок, которые они допустят. По сути этот процесс — доработка механизма извлечения текста таким образом, чтобы максимально упростить работу переводчиков.
Это одна из самых важных частей процесса, потому что извлечённый текст попадёт прямиком к переводчикам, и от того, насколько он опрятен, зависит не только продуктивность их работы, но и количество структурных и семантических ошибок, которые они допустят. По сути этот процесс — доработка механизма извлечения текста таким образом, чтобы максимально упростить работу переводчиков.
Если рассматривать описанный в предыдущем пункте текст, то для переводчика достаточно краткого экскурса о назначении тегов и прочей белиберды, особо его напугать ничего не должно. Но, надо заметить, что основной, на мой взгляд, ошибкой в представлении текста является зашкаливающее количество технической информации. У большинства дилетантов такой текст выглядел бы совсем по-другому:
На месте переводчика я бы сказал: «и как прикажете это переводить?»
Увы, судя по обрывочным сведениям, такое встречается и в процессе официальных локализаций: вот дадут текст в формате XML или INI с «\n» в качестве переноса строк, и переводи как хочешь. При этом многие люди даже в таких случаях не изменяют Word’у, который какой-нибудь автозаменой способен убить структуру практически любого подобного формата или ещё чего хуже.
Это, конечно же, запросто может быть чревато тотальными ошибками, ибо обычно весь контроль качества производится вручную, несмотря на простор для его автоматизации. Как-то раз у «коллег» в релиз укатился очень крупный перевод без единого тире — все их молча скушал Word, подменив на «правильные», которые конвертору текста были не знакомы.
К сожалению, порой от трудно читаемого текста не спасает ничего. К тому же, в некоторых играх теги не компилируются в байткод, а так и хранятся в текстовом виде, т.е. игра обрабатывает их при выводе текста. Да что там говорить, вот вам пример:
&push;&main-color=#E67E00FF;Status:&pop;
&if=hasitem:Fuse7Used;Used&else;&if=hasitem:Fuse7;Acquired&else;Unknown&endif;&endif;&if=scan:SCAN,0x6479E69556A56AC8;
&if=(hasitem:Fuse7Used)|(hasitem:Fuse7);
&push;&main-color=#E67E00FF;Previous Coordinates:&pop;&else;
&push;&main-color=#E67E00FF;Coordinates:&pop;&endif;
&if=mapped:PirateCommand;04P-MET, Pirate Homeworld&else;04P-MET, Unknown&endif;
&just=left;Data indicates Energy Cell is connected to &push;&main-color=#FF6705B3;processing&pop; containment core.&endif;
Согласитесь, глаза сломать можно, что уж говорить о неустойчивости к ошибкам (легко сделать, трудно заметить). Выходом из ситуации мог бы послужить WYSIWYG-редактор, или, по крайней мере, конвертация текста в формат любого такого редактора и последующая конвертация обратно. Но это довольно дорогостоящее (в плане человекочасов) решение, да и от тегов и инструкций оно не сильно-то и спасает.
Раньше я пытался производить декомпозицию (разделение на две сущности) текста и других данных настолько, насколько позволяет конкретный случай. Например, теги можно группировать, заменяя на один тег вроде «» или «<<group_number>>», при этом вынося в отдельный файл. Но, поскольку теги тесно связаны с текстом, да и головной боли от такого решения только прибавляется, я впоследствии от этого отказался.
Но какой-никакой выход всё-таки нашёлся, и заключается он в подсветке синтаксиса. Т.к. все технические данные обычно легко обрабатываются автоматически, то и выделить их среди остального текста тоже не проблема.
Для этих целей я использовал возможности всем известного Notepad++ — в нём есть инструмент для создания своего механизма подсветки. Мне повезло с тем, что переводчик, с которым я работал, сам использовал Notepad++, поэтому уговаривать никого не пришлось. Несмотря на ограниченность в создании правил подсветки, этой возможности оказалось вполне достаточно, хоть и приходилось порой прибегать к разнообразным костылям. 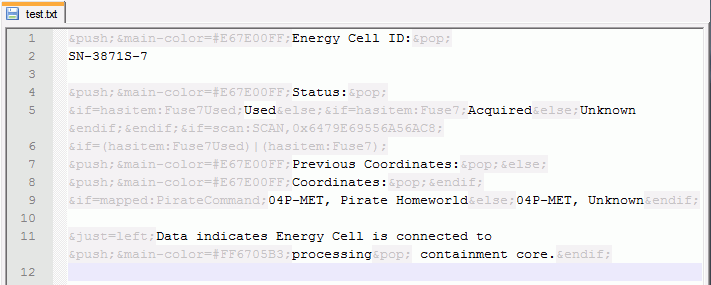
С этим уже вполне можно жить. А иногда я заходил ещё дальше и писал визуализаторы — программы, которые отображали текст так же, как бы он выглядел в игре. Ну, или почти так же… 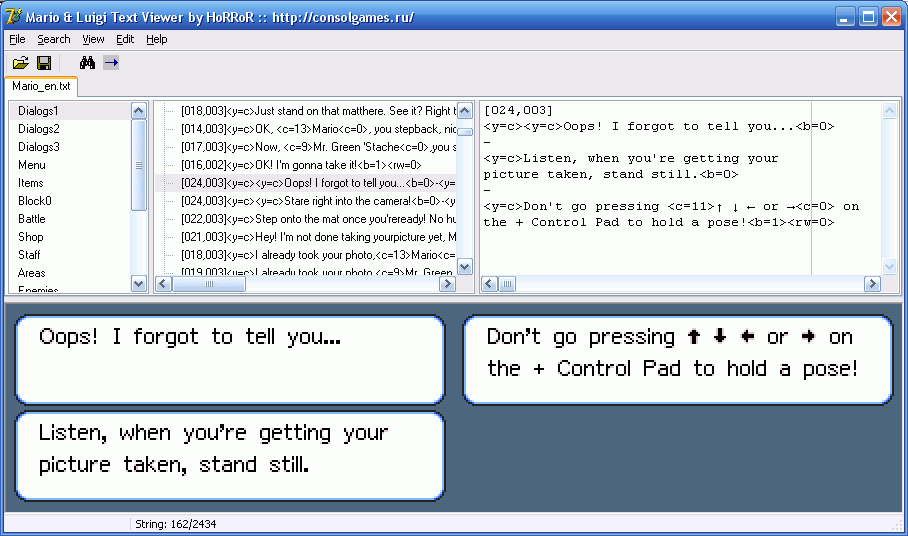
Впрочем, это обычно касалось случаев, когда необходим был жёсткий контроль качества на предмет корректного вывода текста в диалоговых окнах. А гораздо проще контролировать это ещё на этапе перевода, чем потом отлавливать тысячи косяков, связанных с выходом текста за отведённые ему рамки. Хорошо, что во многих играх всё же существует автоперенос.
Как создать русификатор?

Недавно установила игру Legacy of Kain: Revive. Но она на английском, и т.к. она фанатская, для неё, скорее всего, нет русификаторов, поэтому я решила создать свой, но столкнулась с некоторыми проблемами. В папке с игрой, помимо .exe файла есть только 3 файла .dll. При их открытии любой программой (я пробовала их открыть с помощью Restorator, Resource Hacker и Resource Tuner) отображается только информация о версии. В .exe файле помимо нее содержится только иконка и что-то, напоминающее код. Все. Никаких картинок, кода, и прочих игровых ресурсов. Как мне в таком случае сделать русификацию и есть ли какие-нибудь другие программы для этого? Или я просто что-то не так делаю?


Игровой текст с большой вероятностью находится в экзешнике. И с большой вероятностью он находится не в виде обычного теста, а в виде неких тайлов, поэтому от всяких ресурсе хакеров толку будет ровно ноль. Игра создана с помощью Scrolling Game Development Kit 2. скачай эту штуку и попробуй поиграться с ней (хотя я сомневаюсь, что она откроет готовый экзешник). Ну или попробуй как вариант какие-нибудь тайловые редакторы, может, чего и выйдет. Удачи.
- пожаловаться
- скопировать ссылку
Антисоциал
Я скачала несколько тайловых редакторов, но все они предназначены в первую очередь для ромхакинга, и работают с соответствующими форматами (при попытке открыть .exe файл отображаются просто хаотичный набор пикселей). Я почитала, что это (ромхакинг) и зачем он нужен(для лучшего понимания ситуации). В принципе, это именно то, что мне нужно, но была проблема в том, что ромхакинг подразумевает изменение ресурсов консольных игр, преимущественно старых. Несмотря на схожесть этих игр и той, которую я хочу перевести, из-за разницы форматов воспользоваться тайловыми редакторами не получилось. Но благодаря этому я поняла, какие программы мне нужно искать. Сейчас скачала одну программу, благодаря которой мне удалось извлечь ресурсы из игры. Осталось изменить шрифт на русские буквы и с помощью HEX-редактора заменить буквы на соответствующие русские.
Meceas
Я рад, что всё получилось. В большинстве случаев создать русификатор не так просто, как кажется на первый взгляд.

Meceas
Так какая программа для перевода была скачана ? Тоже хотелось бы заняться русификацией игры.
Sider999
Было использовано несколько программ.
Сначала с помощью программы Extractor (можешь найти на этом сайте) я вытащила из игры все изображения и нашла среди них картинку со шрифтом (английским). Затем я английские буквы заменила русскими (т.к. английский алфавит меньше, некоторыми буквами пришлось пренебречь), предварительно записав, что чем заменяю, и с помощью той же программы заменила изначальное изображение на новое, с русскими буквами. Затем с помощью любого Hex редактора нужно открыть .exe файл (все предыдущие манипуляции проводятся так же с ним), найти текст (в моем случае он в конце), перевести и заменить оригинальные буквы другими, соответствующими русским (именно для этого нужно было записать, что чем заменяешь). В принципе все, НО!
По большей части все зависит от того, что именно ты хочешь перевести. В моем случае игра крайне небольшая и малоизвестная, без огромного кол-ва файлов. Поэтому и способ такой. Если игра более известная, хотя бы на уровне гарри поттера (именно игр по нему), то там скорее всего больше файлов разных форматов, и текст скорее всего будет уже в них, а не в .exe файле. В таком случае есть специальные программы по взлому той или иной игры. Это либо какие-то большие программы с кучей форматов разных игр(к примеру, Dragon Unpacker), либо, если игра малоизвестна, то скорее всего есть специальная программа для открытия файлов только этой игры. Возможно придется использовать несколько программ (тот же Hex-редактор). А возможно принцип будет отличаться от слова совсем. Все от игры зависит.
Как сделать русификатор для игры самому


| 2,839 | уникальных посетителей |
| 49 | добавили в избранное |

Создание русификатора с нуля - дело трудоемкое и долгое, однако несложное (при достаточном уровне английского), но таким заниматься нет смысла. Все перевели до вас, поэтому серьезно делать полный перевод не надо, ну только если и правда какой-то мод новый. Если вас что-то не устраивает в установленном у вас переводе, можно просто изменить его под себя.
- Использовать созданную для этого программу Mouse&Brain [rusmnb.ru]
- Использовать текстовый редактор (например Notepad++ [notepad-plus-plus.org] ).
Как текстовый редактор он, несомненно, могет. Однако, перевод файлов игры через него очень геморный. Если программа дает вам сразу две строки и с одной вы переводите, а в другую пишете, то через Notepad так не выйдет. Вам придется стирать английскую версию фразы и вписывать вместо нее русскую. Так вы можете прямо на ходу печати забыть/перепутать/пропустить слово и т.д. Ну и еще выделять в нем очень длинные фразы, ♥♥♥♥♥♥♥♥♥♥♥♥, какая трудная задача. Строка не переносится на начало следующей при упоре в край экрана, а бесконечно тянется вправо. Одно случайное движение мышью вверх/вниз и вы выделили полфайла сразу.
Все это знаю по себе. Но тут уж вам решать. Хотите помучаться, значит есть зачем.
Переводить M&B через Notepad, все равно что кодить на стандартном Блокноте.
Лучше всего изменять/переводить не оригинальные файлы, а их копии. Чтобы получить их выполняем следующие действия:
Запускаем игру в оконном режиме. Ставьте галочку "Запускать в окне".
После запуска игры, находясь на глобальной карте, смотрим в верхний левый угол экрана и жмякаем View - Create Language Template - Default
Теперь копии файлов, в которых хранится весь текст игры находятся по пути
Steam Library - steamapps - common - Mount and Blade Warband - new_language
Менять будем именно их, чтобы не накосячить в основных файлах, которые пока еще используются игрой.
После скачивания программы, открываем наши скопированные файлы.
Чтобы сделать полный русификатор с нуля придется перевести и отпечатать вручную весь список файлов на картинке. В некоторых файлах больше двух тысяч строк. Не дай Бог, таким заниматься.
Вот так выглядит открытый в программе текстовый файл. Строка "Оригинальный текст" не редактируется и служит для перевода с нее. Строка "Ваш перевод" соответственно редактируется вами. После ввода вашего перевода в строку не забывайте нажимать "Заменить".
Когда закончите с файлом сохраните его. Можно сохранить его как копию открытого, в любой закоулок памяти ПК, а можно сразу назвать его как оригинал и заменить в той же папке.
Когда вы закончите со всеми файлами, то назовите папку с ними ru и закиньте ее с заменой по пути Steam Library - steamapps - common - Mount and Blade Warband - Modules - тот модуль, который вы меняли - languages
Все, теперь вы можете открывать игру и выбирать русский язык для нужного вам модуля.
Как я уже говорил, переводить всю игру не нужно. Используйте эту программу для того чтобы поправить ошибки в фразах, перевести какую-то забытую строчку и изменить то, что вас раздражает.
К примеру, для себя я изменил манеру речи посредников в тавернах, убрав им немецкий акцент. Еще перевел вступительный отрывок при создании новой игры и исправил несколько опечаток в словах.
Работа непыльная, но способна доставить вам удовольствие на выходе.
Если вас заинтересовали мои гайдики, вы можете увидеть весь их список через менюшку или через обсуждения.
Чем я пользуюсь для русификации
Привет! На связи Теодорррро. О том, чем я занимаюсь — в предыдущем посте.
В прошлый раз я обещал рассказать о программах и сайтах, которыми я пользуюсь для русификации программ и руководств.
Шаблонные редакторы
Начну с шаблонных редакторов. Это программы, которые предназначены для перевода других программ и руководств к ним. Обычно они достаточно универсальны и позволяют делать перевод и локализацию мобильных приложений, приложений для Windows (MAC OS X у меня нет) и сопутствующей документации.
Опишу их вкратце, только плюсы и минусы.
Мой абсолютный фаворит для перевода справок CHM.
Большую часть времени я провожу именно в нём, ибо локализация руководств — дело небыстрое.
+ идеален для перевода справок CHM + ни один другой редактор не оставляет указатель нетронутым в том порядке, в котором он был;
+ поддерживает память переводов;
+ позволяет импортировать перевод из уже переведённых файлов, в том числе из предыдущих версий исполняемых файлов и из файлов проектов, настройки импорта достаточно гибкие;
+ в целом этот редактор очень легко и гибко можно настроить «под себя»;
+ поддерживает много исходных форматов для перевода.
— очень не хватает функции «нестрогий перевод» или «похожий перевод» — когда в памяти перевода ищутся не только 100 % совпадения, но и похожие строки. Эта функция очень ускорила бы процесс перевода, поскольку часто встречаются исходные строки, различающиеся буквально одним словом или даже символом. Этот редактор считает такие строки совершенно разными)))
— не работает с жёстко-закодированными строками (текстом, который разработчики программы не вывели в отдельные ресурсы, из-за чего их нужно выискивать в исполняемом файле вручную);
— не обновлялся уже 3 года, а за это время вышло много изменений форматов + новые форматы для перевода;
— не поддерживает глоссарии (вид памяти переводов);
— встроенная функция памяти перевода ограничена длиной строки не более 512 байт, то есть нельзя хранить достаточно длинные строки текста.
SDL Passolo
В нём мне привычнее и удобнее всего переводить приложения для Windows.
Процесс перевода программы для лазерных дальномеров.
+ постоянно обновляется — регулярно выходят новые версии с поддержкой новых форматов и настроек;
+ поддерживает глоссарии и память перевода любой длины, без ограничений;
+ имеет функцию «нестрогий перевод», которая очень сильно ускоряет перевод похожих строк;
+ поддерживает интеграцию с SDL Trados, мощнейшей системой автоматизированного перевода;
+ поддерживает множество исходных форматов;
+ поддерживает плагины, макросы + настраиваемые парсеры (правила считывания и разбора исходных файлов, чтобы «выцепить» из них строки для перевода).
Несмотря на кажущуюся идеальность, для меня Passolo имеет и минусы:
— не работает с жёстко-закодированными строками;
— некорректно работает с CHM — портит указатель и некорректно обрабатывает русскую кодировку.
Использую редко, да метко. Иногда без него просто не обойтись!
Открывает скомпилированные файлы перевода QT!
+ единственный (!) из всех мне известных редакторов, который позволяет редактировать уже скомпилированные файлы перевода QT — *.qm;
+ для меня это лучший редактор, который работает с жёстко-закодированными строками (с помощью IDA Pro, об этом позже);
+ имеет не так много настроек, как предыдущие, но их ровно столько, сколько нужно — ничего лишнего;
+ поддерживает функцию «нестрогий перевод»;
Имеет и большие минусы:
— морально устарел, не обновляется с 2012 (!) года, хотя до сих пор способен удивлять своими возможностями;
— не может работать с CHM;
— периодически Radialix выдаёт критические ошибки или просто внезапно закрывается.
Текстовые редакторы для документации
В них я работаю, в основном, с документами и справками в формате PDF.
Help & Manual
Предназначен для написания документации, но я им пользуюсь исключительно для быстрого автоматического преобразования CHM в PDF (если быть точным, CHM > DOCX > PDF) с использованием шаблонов оформления.
Infix PDF Editor
Позволяет локализовать документы PDF с сохранением исходного форматирования. Если он не справляется с этой задачей, я создаю документ заново в Microsoft Word.
Microsoft Word
Да, обычный Word. В нём я создаю полные копии исходных документов PDF (в плане форматирования), затем экспортирую в PDF. Для экспорта пользуюсь Acrobat, а не встроенным функционалом Word, который сильно снижает разрешение иллюстраций и не имеет некоторых настроек.
Удобный редактор с подсветкой синтаксиса, когда нужно на скорую руку перевести небольшие текстовые файлы, не создавая проект в шаблонном редакторе.
Бюджетный аналог Фотошопа.
Простой и быстрый графический редактор с поддержкой слоёв. В нём я перевожу иллюстрации.

Выделяю буквы…

…и удаляю их!
Специальный графический редактор, с помощью которого я удаляю текст со сложного фона, чтобы разместить поверх него текст перевода.
Утилиты в помощь переводчику
Различные программы, которыми я пользуюсь для русификации.
Restorator 2007
Верните мой 2007-й! Ностальгииииия. С него всё начиналось.
Отображает ресурсы (значки, курсоры, текстовые строки, меню и окна) исполняемых файлов и библиотек Windows. Я работаю в шаблонных редакторах, а Restorator 2007 до сих пор пользуюсь для быстрого просмотра ресурсов.
Punto Switcher (Caramba Switcher)
Программы этого рода помогают в ситуации, когда, увлёкшись, набираешь текст в неправильной раскладке. Здесь я автоматику отключаю и исправляю раскладку только по нажатию клавиши.
Программа, в которой собрано несколько онлайн-систем перевода и словарей на разных вкладках. В ней удобно переключаться по вкладкам и сравнивать переводы.
Smart Install Maker
В этой программе я создаю установочные файлы для русификаторов. Эта утилита умеет читать путь из реестра, что очень важно для того, чтобы русификатор смог правильно определить папку, в которой установлена русифицируемая программа. К сожалению, у Smart Install Maker уже несколько лет не было новых версий.
PatchWise Free
Позволяет создавать крохотные русификаторы-патчи. Патч содержит не весь файл, а только изменения в нём, из-за чего русификатор сильно выигрывает в размере. Из минусов — настроек у этой утилиты крайне мало, и морально она давно уже устарела.
Быстрый и удобный редактор значков *.ico. В нём создаю значки для установщиков русификаторов.
Проверяю изменения в новой версии справки
Мой главный инструмент для сравнения файлов. С его помощью я могу понять, какие файлы изменились в новой версии той или иной программы.
Дизассемблер, которым изредка пользуюсь только в связке с Radialix для перевода жёстко-закодированных строк. Radialix устанавливает в IDA Pro специальный плагин, с помощью которого можно отыскать все ЖЗ-строки и отправить их в Radialix для перевода, не опасаясь нарушить структуру исполняемого файла или библиотеки.
Очень быстрый поиск по именам файлов на компьютере.
Утилита для поиска текста в файлах. Если в программе, которую я хочу локализовать, вижу какой-то текст, но при этом не могу понять, в каком файле программы этот текст находится, я пользуюсь этой утилитой.
Поиск текста в файлах также можно делать с помощью Notepad++:
Быстрый и удобный скриншотер. В нём я создаю скриншоты-иллюстрации для руководств и справок. Поддерживает автоматическое применение эффектов при создании скриншота — тени под изображением или водяного знака, к примеру.
Сайты в помощь русификаторщику
Самый полный онлайн-словарь, превосходит по объёму даже ABBYY Lingvo. Постоянно пополняется пользователями. Я и сам вносил туда переводы терминов.
Онлайн-словарь и память переводов. Постоянно пополняется. Можно найти готовые переводы шаблонных фраз и даже целых стандартных документов. Например, перевод страницы по безопасному обращению с электроприборами для руководства к электронной гитаре я взял оттуда, сделав небольшие коррективы.
Онлайн-словарь и термины для всех программ и продуктов, выпущенных корпорацией Майкрософт.
Также на этом портале можно скачать официальные руководства Майкрософт по локализации программ. Начинающим переводчикам будет крайне полезно ознакомиться с ними. Там есть рекомендации не только по технической стороне вопроса, но и по стилистике языка и по особенностям культуры страны, для которой делается перевод.
Крупнейшая онлайн-база данных русификаторов. На нём я выкладываю свои работы. Есть форум, на котором можно пообщаться на тему русификации.
Сообщество русификаторщиков. Здесь делятся своими работами по русификации и обмениваются опытом.
В следующий раз я расскажу о каком-нибудь из своих проектов по русификации или подробнее объясню, как работать в шаблонных редакторах, например. И задавайте вопросы, с удовольствием на них отвечу!
Ознакомиться с данной статьёй можно в моём сообществе ВКонтакте, посвящённом русификации.
До новых встреч!
Как пользователь весьма сложного оборудования скажу. Все переведённые мануалы (положенные по закону при поставке) аккуратно складываю стопочкой в шкафу и читаю англоязычные исходники. Во-первых, там всё более однозначно, во-вторых гораздо меньше ляпов и переводческой отсебятины. Особенно "радуют" переводы терминов и сокращений от наших надмозгов. Бывают и просто ошибки, переворачивающие смысл с ног на голову.
я QTranslate использую если очень надо, а в остальном не требуется, в играх некоторых типа старого варкрафта 3 фт пока переведешь все устанешь, а там надо типа шмотка какая для чего и что дает, ctrl+t выделил и перевела программа, удобно кстати ))
Что любопытно, на перевод каких программ может быть спрос в 2021?
Сейчас крупные пакеты почти повсеместно русифицированы или вообще работают как веб-приложения, на которые патч не накатишь. А всякая мелочевка - простая и интуитивная вплоть до уровня интеллекта инфузории-туфельки.
А есть ли бесплатные программы переводов интерфейса программ и справок?
Перевод справок желательно наглядно, как если использовать в браузере contentEditable=true . Делаю это так на иностранных сайтах, перевожу с помощью "Qtrranslate" и потом сохраняю в MHT, чтоб форматирование не подевалось, и русский язык остался. При этом заметил, если сохранять как HTML, то часто русский язык не фиксируется.

R.G. MVO полностью озвучит Dead Space Remake на русский язык
Всем доброго времени суток, друзья! Многие наверняка уже отгадали, о чём будет пост. Это было не просто ожидаемо, а скорее долгожданно)
Да, мы объявляем об открытии сборов на ПОЛНУЮ русскую локализацию Dead Space Remake! Как вы знаете, игра не получила перевода на русский вообще в каком-либо виде, а значит мы возьмёмся как за дубляж речи, так и за текст.
Сборы проходят на Бусти - https://boosty.to/mvo_team (раздел "ЦЕЛИ" слева)
А если кому-то удобнее, то можно поддержать на DonationAlerts (ОБЯЗАТЕЛЬНО напишите, на какую именно игру совершаете донат) - https://www.donationalerts.com/r/rg_mvo
Первое демо постараемся показать уже в марте. Текстовую локализацию стоит ожидать ближе к апрелю, а саму озвучку уже летом.
По поводу самой игры и локализации.
Диалоги заметно прибавили в размерах, причём не только из-за заговорившего Айзека Кларка, но и из-за расширенной сюжетной линии многих второстепенных персонажей. Текстовые логи эволюционировали до АУДИОлогов. А персонажи, которые раньше просто оставляли предсмертный аудиолог, отныне напрямую взаимодействуют с нашим героем, прямо как Кендра и Хэммонд.
Ну и весь этот сыр-бор мы будем озвучивать с привлечением профессиональных актёров дубляжа, как широко известных, так и молодых, но не менее талантливых ребят и девчат.
Да, возможность вернуть голоса из старой озвучки есть, первым делом пригласим Петра Гланца и Рамилю Искандер на роли Хэммонда и Кендры соответственно. Нону Виноградову (голос Ишимуры, а также Присцилла из Ведьмака и Доктор Вален из XCOM) также постараемся привлечь, так как нашлось не малое число желающих вновь услышать её голос.
А вот остальные персонажи получили заметные изменения. В характере, во внешности и в голосе. К примеру, Доктор Терренс Кейн стал выглядеть моложе, в то время как Александр Груздев, озвучивший его в те времена, стал звучать старше. Но не исключены камео старых актёров на других ролях.
А ещё многие успели пожаловаться на "повесточку" в игре, мы пока что заметили лишь фразу Кендры в самом начале. Если это в дальнейшей вообще никак более не упоминается, то мы не понимаем всеобщей паники, но коли многих это так волнует, то вполне можно ОПЦИОНАЛЬНО внести вариант озвучки без упоминания меньшинств, во имя спокойствия игроков.

The Suffering - Анонс русской озвучки

Всем привет! Мы тройку месяцев назад анонсировали локализацию культового хоррора The Suffering, вот теперь и демонстрацию дубляжа его интро выкладываем.
Мы давно заметили, что игры середины нулевых страдают кучей болячек в плане звука, и этот проект не стал исключением. Игра встретила нас скачками громкости голосов персонажей + порой внезапно возникающим на переднем плане эмбиентом, который по изначальной задумке должен был тихонечко звучать где-то на заднике. С одним лишь вступительным интро мы возились длительное время, и результат наших стараний вы можете оценить сами.
Куратор проекта после такого даже подумывает больше не мучаться со старенькими играми нулевых и перейти полностью на. Нет, не новинки, а на игры 90-ых.
Также, помимо вступления, уже были записаны три основные роли, но показывать вам мы их не будем! Пока что.
А благодаря вашей поддержке, за что огромнейшее спасибо, в феврале состоится запись ещё некоторых персонажей, однако озвучивание самых главных и объёмных ролей будет завершено не скоро ввиду довольно большого количества реплик у них.
Наверняка все знают, что у игры была одноголосая озвучка в исполнении Леонида Володарского. Для тех, кто не в курсе о "крутости" этой локализации от Нового Диска, на ютубе есть её хороший разбор: https://youtu.be/65tHEu9kmU0
Так что даже если вы фанат одноголосой озвучки, то как минимум впервые появившийся адекватный перевод текста должен будет вас заинтересовать.
Оставляйте ваше мнение, да и вообще всячески показывайте вашу заинтересованность в тех или иных проектах. Приятного просмотра!

Руководство по парольной политике. Часть 1
Первая часть практического руководства по созданию эффективных паролей от коллектива иностранных авторов, переведённого экспертами Origin Security специально для наших читателей
1. Примечание переводчика
Пароли повсеместно используются в современном мире. Если у вас есть учетная запись на компьютере, то наверняка будет хотя бы один пароль. Пароли использовались в компьютерах с момента появления вычислительной техники. Первой операционной системой с реализованным механизмом аутентификации на основе пароля стала Compatible Time-Sharing System (CTSS), представленная в Массачусетском технологическом институте в 1961 году.
Пароли – это самая простая форма реализации информационной безопасности. В течение многих лет эксперты пробовали сделать пароли более сложными для взлома, применяя различные правила создания и использования паролей (т.н. парольные политики).
Однако, при всей технической простоте реализации, парольная политика нередко оказывает спорное влияние на уровень безопасности информационных систем. Необоснованно завышенные требования к сложности и сменяемости паролей часто приводят к тому, что пользователи их просто забывают, после чего надоедливо отвлекают безопасников просьбами сменить пароль. Распространенными среди пользователей практиками являются также запись сложного пароля на стикере, который виден всем окружающим, или изменение только последнего символа пароля при появлении требования об установке нового пароля.
Поэтому, чтобы эффективно противодействовать злоумышленнику, парольная политика должна иметь реальное обоснование и не приводить пользователей в замешательство и расстройство. Некоторые крупные игроки в области стандартизации информационных технологий (NIST, Microsoft и пр.) недавно разработали новые парольные политики, основанные на двух базовых принципах:
1. Использование данных о техниках и тактиках действий злоумышленников.
2. Облегчение пользователям создания, запоминания и использования надежных паролей (учет человеческого фактора).
Цель этого документа – не изобретать велосипед, но объединить новые руководства по парольной политике в одном месте. Создать универсальную парольную политику, которую можно использовать везде, где это потребуется.
2.1 Обзор лучших практик
Каким бы стойким ни был пароль, эффективная защита может быть достигнута только при комплексном подходе с применением разнообразных механизмов. Подходы к реализации парольной политики можно ранжировать следующим образом (от более предпочтительных к менее):
2.1.1. Многофакторная аутентификация (МФА)
МФА – это самый эффективный метод защиты, и, хотя в руководстве ему посвящён отдельный раздел, здесь он заслуживает особого упоминания. МФА должна быть приоритетным вариантом при проектировании системы аутентификации для всех пользователей и везде, где это возможно. Особенно она необходима для безопасности доступа администраторов и других привилегированных учетных записей. Понятно, что МФА сама по себе не является панацеей хотя бы потому, что далеко не во всех информационных системах возможна её техническая реализация. Кроме того, даже при использовании МФА иметь стойкий пароль полезно, поскольку он используется как один из факторов.
2.1.2 Менеджер паролей
Инструмент позволяет создавать и хранить уникальные и сложные пароли для каждой учетной записи. Использование менеджеров паролей может значительно повысить безопасность и удобство авторизации пользователей.
2.1.3 Политика создания и применения паролей пользователями
Этот подход наиболее полно описан в данном руководстве, поскольку он является самым распространенным в настоящее время. Вместе с тем, большая часть рекомендаций актуальна для всех трех методов.
3. Обзор рекомендаций
Краткое описание рекомендаций по парольной политике представлено в таблице ниже. Детальная информация по каждой рекомендации раскрыта в главе 5.
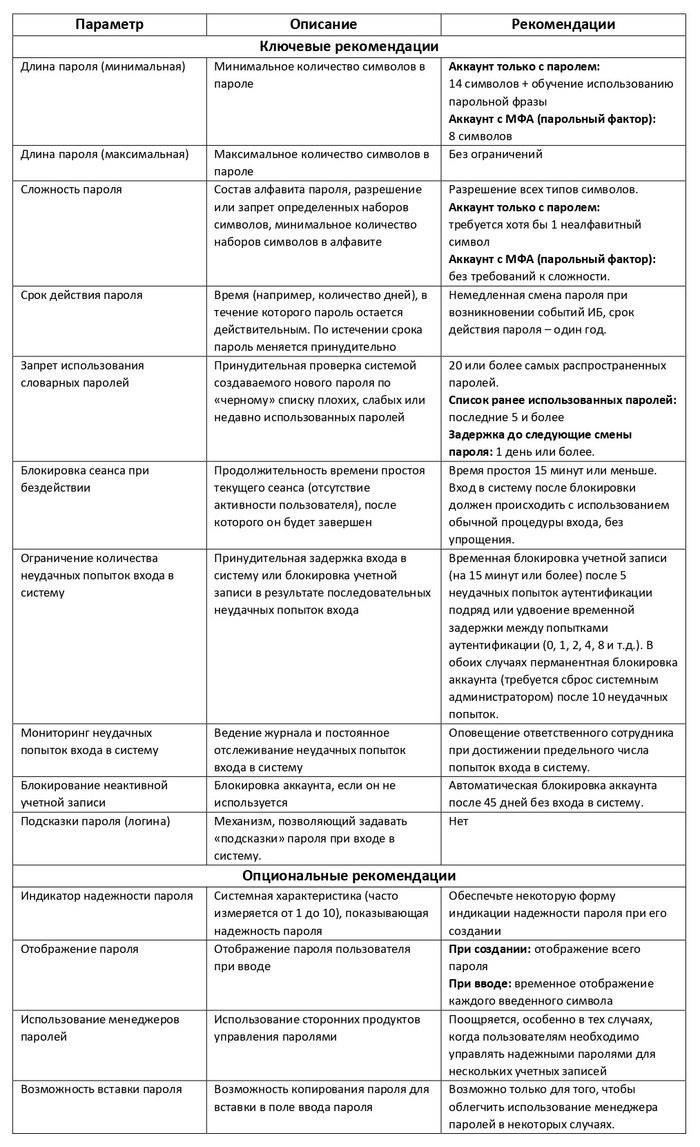
Общая цель эффективной парольной политики – позволить пользователям легко создавать достаточно надежные пароли для доступа к системе, а затем отслеживать и ограничивать попытки доступа для обнаружения/предотвращения их несанкционированного использования.
4. Насколько важен пользовательский пароль?
Ввиду повсеместного использования паролей для доступа к компьютерным системам всех типов, очевидно, что пароли очень важны. Но существует ли компромисс между безопасностью и удобством использования? Не привели ли попытки разработать политику, чтобы сделать более безопасными применяемые пароли, к фактическому снижению уровня безопасности системы из-за человеческого фактора? В известной статье Алекса Вайнерта (Microsoft) «Your Pa$word doesn’t matter» приведено описание реальных атак на пользовательские пароли, развеяны распространенные мифы о надежности паролей и поведении пользователей. Обобщенная информация представлена в следующей таблице:
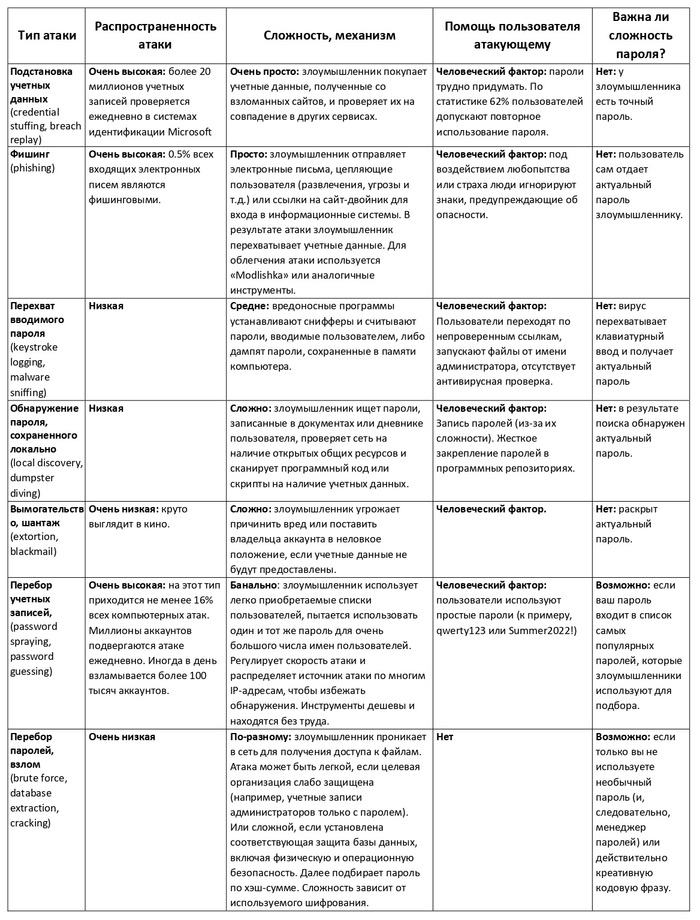
Из всех распространенных атак, перечисленных выше, надежность пароля имеет значение только в двух случаях:
✧ проводимые онлайн: перебор учетных записей (password spraying, password guessing);
✧ проводимые офлайн: перебор паролей, взлом (brute force, database extraction, cracking).
Давайте рассмотрим их подробнее.
4.1 Атаки, проводимые онлайн
Password Guessing или Hammering – это систематический подбор пароля злоумышленником к одной целевой учетной записи. Перебор проводится преимущественно по словарям и по утечкам, найденным в Интернете.
Password Spraying – это вариант атаки, при котором злоумышленник использует те же списки паролей, но нацеливается на множество общедоступных или легко определяемых (например, общий формат имени учетной записи) учетных записей пользователей.
В случае с Password Guessing кажется, что здесь важна надежность пароля, но на самом деле гораздо важнее мониторинг и ограничение неудачных попыток входа. При наличии разумных ограничений и мониторинга тот факт, что современные технологии позволяют перебирать миллиарды паролей в секунду, не имеет значения, поскольку учетная запись будет заблокирована, а администратор безопасности – уведомлен об инциденте. Именно поэтому более распространенной формой атаки стал Password Spraying, но чтобы он был эффективным, злоумышленнику необходимо избегать блокировки учетных записей. Добиться этого можно, если узнать формат имени учетной записи, принятый в целевой организации. В таком случае атака заключается в переборе ограниченного словаря паролей, но в отношении множества учетных записей, что не приводит к их блокировке и позволяет злоумышленнику не попадать в поле зрения команды защитников.
Даже в этих случаях более сложный пароль не является лучшим решением. Гораздо более эффективным и простым для пользователей вариантом будет использование более длинных, сложных и разнообразных имен учетных записей. Действенным способом обнаружения атак типа Password Spraying является использование специальных сигнальных учетных записей. Это действительные аккаунты с минимальными привилегиями, которые соответствуют принятой парольной политике, но не предназначены для доступа. Попытки авторизации с их помощью свидетельствуют о компьютерной атаке, расследование которой позволяет администраторам информационной безопасности заранее обнаружить угрозу и не допустить компрометации паролей настоящих учетных записей.
4.2 Атаки, проводимые офлайн
Это единственный вариант, когда сложность пароля по-настоящему имеет значение. При такой атаке злоумышленник уже завладел базой данных учетных записей/паролей целевой компании, в которой пароли хранятся в хэшированном виде (вместо обычных текстовых паролей, что было бы слишком просто). В дальнейшем злоумышленник восстанавливает настоящие пароли из найденных хэш-сумм методом перебора с применением одного из множества свободно распространяемых инструментов (например, John the Ripper или L0phtCrack) или специальной программой, разработанной для этого самим злоумышленником.
Мы не будем подробно описывать принцип работы этих программ (существует множество открытых источников по взлому паролей), но в общем случае злоумышленник может сделать следующее:
1. Создать «брут-машину»: стандартное компьютерное оборудование с высокопроизводительной видеокартой, которое может вычислять и проверять несколько миллиардов несложных хэшей (MD5, SHA1, NTLM и т.д.) в секунду. Легкодоступные установки для добычи криптовалют (майнеры) могут без труда достичь скорости перебора в 100 миллиардов хэшей в секунду, а хорошо финансируемые злоумышленники (прогосударственные группировки) могут достичь скорости и в 100-1000 раз выше.
2. Перебрать все возможные пароли. При использовании майнера и предположении, что мощность словаря пароля составляет 96 символов, бездумное перебирание всех вариантов пароля займёт следующее время:
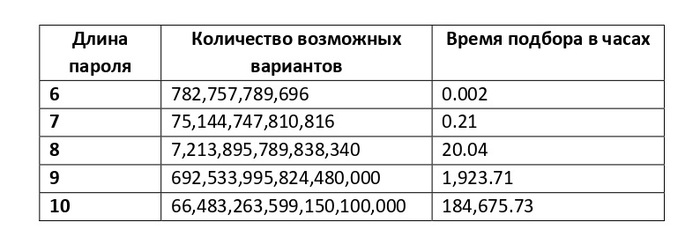
3. Ускорить перебор, используя дополнительные техники и знания:
✧ изучив целевую организацию, злоумышленник может выяснить алгоритм хэширования и специфичные для неё правила генерации паролей (минимальная/максимальная длина, сложность и т. д.);
✧ использовать списки паролей, полученные в результате предыдущих взломов (огромное количество паролей уже находятся в свободном доступе). После хеширования проводится проверка на совпадение с хэшами в целевой базе данных. По статистике, это позволяет взломать около 70% паролей пользователей;
✧ если это не сработает, злоумышленник может составить список всех популярных фраз, текстов песен, заголовков новостей, частых запросов поисковых систем, википедии, популярных статей и т.д. Или взять готовый — подобные списки доступны в различных сообществах «хэшбрейкеров». Таким образом можно подобрать еще 5-7% паролей пользователей;
✧ наконец, злоумышленник может использовать предугаданные шаблоны (например, пароль всегда начинается с заглавной буквы, затем 3-6 строчных букв, 2-4 цифры и восклицательный знак в конце) и подобрать более длинные пароли (до 12 символов). Это позволяет вскрыть еще 5-7% пользовательских паролей.
4. В случае использования «соли» для хранения паролей в базе (применения к хэшу дополнительного преобразования, усложняющего автоматический перебор), данные техники применяются не для всех хэшей, а для одного. Вместе с тем, атака проводится с высокой вероятностью успеха почти в 85% и за относительно короткий промежуток времени, что позволяет злоумышленнику перейти к следующей учетной записи и последовательно перебрать их все.
Здесь стоит отметить следующее:
✧ данный метод перебора работает только в том случае, когда у атакующего есть база учетных записей/паролей. Как злоумышленник получил ее? Если уровень доступа атакующего достаточен, чтобы получить базу данных, то целью он, скорее всего, уже владеет;
✧ если база данных учетных записей/паролей, полученная злоумышленником, не относится к цели, то взломанный пароль все равно нужно попробовать на реальной учетной записи в целевой системе;
✧ человек вряд ли сможет создать надежный пароль, который выдержит описанные попытки взлома. Если противодействие им необходимо, используйте длинный и сложный пароль, сгенерированный автоматически. Например, созданный и управляемый менеджером паролей;
✧ технические возможности для взлома хэшей постоянно растут. Неужели мы будем постоянно гнаться за ними, делая пароли всё длиннее, сложнее и труднее для запоминания, пытаясь справиться с одним-единственным сценарием атаки? Очевидно, будет лучше использовать более комплексный подход.
Таким образом, необходимости использования паролей со сложностью выше определенного разумного уровня нет. Так почему бы не разработать политику, поощряющую достаточно надежные пароли, которые легко создавать, запоминать и использовать? Данное руководство призвано помочь с этим, и мы продолжим в следующей части