Прототипы функций в С++
Допустим, что в некотором месте в вашем коде происходит вызов определенной функции. Зададимся вопросом, при каких условиях при компилировании этого участка кода компилятор не выдаст ошибки. На этот вопрос существует простой ответ. Где-то в том же файле, в котором осуществляется вызов функции, перед операцией, в которой осуществляется вызов, должны присутствовать прототип или описание функции. Кроме того, аргументы и тип возвращаемого значения в вызове должны соответствовать аргументам и типу возвращаемого значения в прототипе и в описании функции.
Итак, что же такое прототип функции? Прототип имеет следующий вид.
Как видно в прототипе указываются по порядку тип возвращаемого значения (в данном примере void ), название функции (в данном случае function ) и список параметров в скобках. Объявление прототипа должно заканчиваться точкой с запятой.
Для чего нужен прототип функции? Прототип и описание функции используются компилятором для того, чтобы вызов функции происходил правильным образом. Для этого компилятор сначала смотрит имя вызываемой функции и ищет в файле прототип или описание этой функции. Если найден прототип или описание, то проверяются аргументы, передаваемые функции в вызове, и использование возвращаемого значения.
Для чего нужен именно прототип? Почему нельзя ограничиться использованием одного описания функции? Прототип стал необходим после того, как стандарты языка С изменились таким образом, что перед вызовом функции в файле необходимо каким либо образом ее описать. Проблема состоит в том, что имя функции имеет глобальную область видимости (если ее описание находится вне всяких локальных областей). Допустим, что описание функции находится в отдельном исходном файле. Также допустим, что необходимо осуществить вызов этой же функции в нескольких других исходных файлах. Если нет прототипа, то в каждый такой исходный файл необходимо включить полное описание функции. Компилятор будет интерпретировать это как переопределение. Если же мы используем прототип, то мы можем включать этот прототип в столько исходных файлов, сколько нам необходимо.
Как лучше всего использовать прототип функции. Лучше всего описание функции включить в отдельный исходный файл. После этого надо скомпилировать этот файл и получить объектный файл. Прототип следует помесить в заголовочный файл и включать его директивой #include в те исходные файлы, в которых присутствует вызов функции.
Некоторые сведения о Perl 5/Функции и процедуры
Подпрограммы или процедуры играют ту же роль, что и в других языках программирования:
- они позволяют разбить одну большую программу на несколько небольших частей, чтобы сделать ее понятной;
- они объединяют операторы в единый фрагмент, который может повторно вызываться, возможно при разных входных параметрах.
В Perl нет разницы между процедурами и функциями, однако мы условимся называть функциями такие процедуры, которые возвращают некоторый результат той части программы, которая их вызывает.
Содержание
Определение процедуры [ править ]
Процедура может быть объявлена в любом месте основной программы следующим образом:
- <имя-процедуры> — имя процедуры, по которому ее можно вызывать явно.
- (<прототип>) — специальная строка, которая описывает какие парараметры разрешено передавать процедуре.
- <<основной-блок>>— блок операторов, являющийся определением процедуры и выполняющийся при каждом ее вызове.
Подобно языку Си, процедуру можно объявить, но не определить (не предоставить основной блок), возможно потому, что ее определение находится в другом файле. В этом случае объявление должно выглядеть так
Тело процедуры может хранится в разных местах:
- оно может быть определено в том же исходном файле;
- оно может быть определено в отдельном файле и загружаться с помощью do , require и use ;
- текст процедуры может быть передан функции eval() : в этом случае компиляция процедуры будет происходить каждый раз при вызове;
- текст процедуры может быть определен анонимно и вызываться по ссылке.
Вызов процедуры [ править ]
Процедуру можно вызвать, указав ее имя с идентификатором типа & :
Если процедура вызывается со скобками после имени, причем не важно есть ли аргументы у функции на самом деле или нет, идентификатор типа & можно опускать:
Если перед вызовом процедура была определена или импортирована, то можно опустить и & и скобки:
Если процедура анонимная, то идентификатор типа & в вызове обязателен:
Процедура может использоваться в выражениях, если она что-то возвращает. По умолчанию процедура всегда возвращает последнее вычисленное значение в ее блоке. Можно указать возвращаемое значение с помощью функции return() в любой точке процедуры. Возвращать можно как простые скалярные значения, так и массивы.
Если процедура является целым файлом, то ее можно вызвать как perl-подпрограмму с помощью конструкции do <имя-файла>; . Если указываемый файл недоступен для чтения, то do возвращает неопределенное значение, а встроенной переменной $! будет присвоен код ошибки. Если файл может быть прочитан, но возникают ошибки при компиляции или во время исполнения, то do возвращает неопределенное значение, а в специальной переменной $@ будет хранится сообщение об ошибке.
Функция eval() [ править ]
рассматривает параметр <выражение> как текст программы Perl, компилирует его и, если не обнаруживает ошибок, выполняет в текущем вычислительном окружении. Если выражение передано блоком, то оно анализируется и компилируется один раз. Это удобно, так как ошибки обнаруживаются раньше. Если аргумент передается не блоком, то его ошибки будут обнаружены только во время исполнения.
Если <выражение> отсутствует, то по умолчанию используется переменная $_ . Если выражение завершается успешно, то она возвращает последнее вычисленное значение внутри <выражение> .
Если <выражение> содержит синтаксические ошибки или вызывается die() , или при исполнении возникает ошибка, то eval() возвращает неопределенное значение, а в специальную переменную $@ заносится сообщение об ошибке.
Основным применением функции eval() является перехватывание исключительных ситуаций (исключений), т.е. таких ошибок, которые принудительно прерывают исполнение всей программы. К исключению можно отнести, например, ситуацию деления на ноль. Это работает потому, что исключение прервет только исполнение функции eval() и передаст управление вызвавшей части программы.
Иногда по логике программы вам нужно генерировать исключение. Для этого вы должны использовать функцию die() .
Область видимости процедуры [ править ]
Точкой определения переменной в Perl является то место, где она впервые встречается в программе. Область действия большинства переменных ограничена пакетом. Исключение составляют некоторые специальные предопределенные переменные интерпретатора perl. Пакет — это способ порождения пространства имен для части программы. Другими словами, каждый фрагмент кода относится к какому-то пакету.
Переменные, которые встречаются в процедурах, по умолчанию видны всему пакету (т.е. они обладают глобальной видимостью). Иногда это не желательно: обычно мы хотим ограничить время жизни переменных процедур в рамках тела этих процедур, а также не хотим, чтобы процедуры влияли косвенно на уже существующие глобальные переменные.
Перменные, которые видны только конкретной процедуре, называются локальными (говорят что они лексические) и такие переменные обладают локальной видимостью (lexical scope). В Perl существует два способа порождения локальных переменных: при помощи функции my() и local() .
Функция my() [ править ]
Функция my() используется для объявления одной или нескольких переменных локальными и ограничивает область их действия:
- процедурой/функцией;
- блоком;
- выражением, переданным eval() ;
- исходным файлом программы, в зависимости от того, в каком месте была вызвана my() .
Функция local() [ править ]
Функция local() вызывается аналогично my() , но создает не совсем локальные переменные, а временно заменяет текущие значения глобальных переменных локальными значениями внутри:
- процедуры/функции;
- блока;
- выражения, переданного eval() ;
- исходного файла с программой, в зависимости от того, в каком месте вызвана local() .
Если при вызове функции глобальная переменная существует, то ее предыдущее значение сохраняется в стеке и заменяется новым значением. После выхода переменной из области видимости процедуры/блока/функции eval() или файла, ее предыдущее значение восстанавливается из стека. Такие переменные иногда называют динамическими, а их область видимости — динамической областью видимости.
Функция my() появилась в Perl с пятой версии, позже local() , однако для создания истинно локальных переменных рекомендуется использовать именно функцию my() . Впрочем и у local() есть причины для применения.
Рекомендации по использованию my() и local() [ править ]
Функция my() должна использоваться всегда, кроме следующих случаев, когда нужно использовать local() :
- Присваивание временного значения глобальной переменной, в первую очередь это относится к предопределенным глобальным переменным типа $_ , $ARGV и другие.
- Создание локального дескриптора файла, каталога или локального псевдонима или функции.
- Временное изменение массива или хеш-массива. Например, так следует поступать, если нужно временно изменить переменные окружения в предопределенном хеш-массиве %ENV .
Функция our() [ править ]
Чтобы явно обозначить пакетную область видимости переменной, используется функция our() . Данная функция только наделяет переменную видимостью пакета, создавая лексический псевдоним внутри него, поэтому она может применяться как к уже объявленным переменным, так и не объявленным (в этом случае побочным эффектом будет их объявление). Использование our() во многом аналогично описанным выше my() и local() .
Использование этой функции в общем то не обязательно, так как любая переменная получает эту видимость по умолчанию. Данная функция используется в следующих ситуациях:
- Когда включена директива use strict ‘vars’; , которая требует явного указания области видимости переменной в любом месте, где она действует.
- Когда переменная используется в блоках, например
Функция our() наделяет переменную пакетной видимостью на протяжении всего лексического пространства. Сравните
Такое поведение отличает our() от до этого использовавшейся директивы use vars , которая позволяла использовать неквалифицированные имена только внутри текущего пакета. Помните, что с версии 5.6.0 использование use vars считается устаревшим подходом. Используйте только our() .
Передача аргументов в процедуру [ править ]
Данные в процедуру передаются через ее аргументы. Для передачи аргументов используется специальный массив @_ , в котором $_[0] – первый параметр, $_[1] – второй параметр и так далее. Такой механизм позволяет передать в процедуру произвольное число аргументов.
Массив @_ является локальным для процедуры, но его элементы — это псевдонимы действительно переданных параметров (не копии). Изменение параметров в @_ приводит к изменению действительных параметров. Таким образом, в Perl параметры фактически передаются всегда по ссылке.
Чтобы реализовать передачу по значению, вы должны создать внутри процедуры локальные переменные и скопировать в них значения из @_ . Обычно это делается так
или с помощью функции shift , каждый вызов которой возвращает очередной элемент массива @_
Передача аргументов по ссылкам [ править ]
К сожалению массивы не могут быть просто так переданы в процедуру с сохранением их идентичности. Если параметр является массивом или хеш-массивом, все его элементы сохраняются в @_ . При передаче в подпрограмму нескольких массивов, все они будут перемешаны в одном @_ :
Передавать массивы можно одним из двух способов.
Первый подход, более старый, заключается в использовании типа typeglob . При передаче typeglob в процедуру, интерпретатор преобразует его в скаляр, который внутри процедуры может быть уточнен соответствующим идентификатором. Следующий пример демонстрирует это.
В этом примере в процедуру мы передаем не сами массивы, а переменные типа typeglob , которые легко выделить из @_ , так как фактически они являются скалярами. Мы использовали здесь local() вместо my() потому, что typeglob представляет запись в таблице символов и поэтому не может быть локальной. Запись local (*array, *hash) = @_; создает синонимы (псевдонимы), т.е. *array фактически создает псевдоним для *list , а *hash для *person . Таким образом, любые изменения по псевдонимам будут приводить к изменениям в оригиналах.
Второй подход, более новый, связан с передачей ссылок на массивы. Ссылка является скаляром, поэтому ее легко выделить в @_ . Таким образом, внутри процедуры достаточно просто применять операции разыменования ссылок. Вышеприведенный пример может быть переписан:
В данном случае мы скопировали ссылки в локальные переменные при помощи my() . Изменение оригинальных массивов через ссылки должна быть понятна.
Прототипы [ править ]
Встроенные функции Perl всегда имеют строго определенный синтаксис, другими словами, синтаксический анализатор Perl проверяет как они вызываются. По умолчанию, как вызываются пользовательские процедуры никак не проверяется: например, вы можете вызвать функцию и передавать ей аргументы, даже когда она их не ожидает, либо вы можете случайно передать переменные не тех типов и никаких ошибочных действий интерпретатор Perl не выявит.
Чтобы контролировать вызов процедур на этапе компиляции, используются прототипы. Прототип процедуры/функции — это строка из списка символов, определяющая количество и типы передаваемых параметров. Например следуюшая функция
имеет прототип, который говорит, что функция ожидает две скалярные переменные. Следующие символы можно использовать в прототипе, чтобы обозначить передаваемый тип:
- $ (скаляр)
- @ (массив)
- % (хеш-массив)
- & (анонимная процедура)
- * (typeglob)
Если поставить перед символом в прототипе обратный слеш, например sub example (\$) <. >, то имя фактического параметра всегда должно начинаться с идентификатора этого типа. В этом случае внутри процедуры в массиве параметров @_ будет передаваться ссылка на фактический параметр, указанный при вызове. Это позволяет упростить передачу массивов по ссылкам, например, сравните
Обязательные параметры отделяются от необязательных внутри прототипа символом ; . Например
имеет 4 параметра, первые 3 из которых обязательны.
Следует помнить, что прототип не проверяется, когда вызов процедуры начинается с амперсанда & ( &example ).
Контекст выполнения функции [ править ]
Каждая функция может узнать в каком контексте она выполняется и в зависимости от этого отдавать результат в нужном контексте. Для этого используется функция wantarray() , которая возвращает ИСТИНУ, если функция или блок eval<> был вызван в списковом контексте, иначе ЛОЖЬ. Функция возвращает undef значение, если она была вызвана в void-контексте.
Следующий небольшой пример демонстрирует работу этой функции.
Рекурсивные вызовы [ править ]
Язык Perl допускает, чтобы процедура/функция вызывала саму себя. Такие вызовы называются рекурсивными.
Программирование рекурсивных функций мало чем отличается от других языков программирования. Основной рекомендацией является обязательное объявление всех переменных как my() и local() , чтобы создавать новые копии переменных на каждом новом уровне вызова.
Применять рекурсивный подход следует осторожно, так как рекурсивное программирование всегда расточительно в плане ресурсов. Однако, существуют алгоритмы, в которых применение рекурсии оправдано и необходимо. Самой известной задачей, где без рекурсии не обойтись, это проход по дереву каталогов для получения перечня файлов.
Прототипы в JS и малоизвестные факты
Получив в очередной раз кучу вопросов про прототипы на очередном собеседовании, я понял, что слегка подзабыл тонкости работы прототипов, и решил освежить знания. Я наткнулся на кучу статей, которые были написаны либо по наитию автора, как он «чувствует» прототипы, либо статья была про отдельную часть темы и не давала полной картины происходящего.
Оказалось, что есть много неочевидных вещей из старых времён ES5 и даже ES6, о которых я не слышал. А еще оказалось, что вывод консоли браузера может не соответствовать действительности.
Что такое прототип
Объект в JS имеет собственные и унаследованные свойства, например, в этом коде:
у объекта foo имеется собственное свойство bar со значением 1 , но также имеются и другие свойства, такие как toString . Чтобы понять, как объект foo получает новое свойство toString , посмотрим на то, из чего состоит объект:
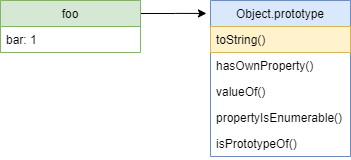
Дело в том, что у объекта есть ссылка на другой объект-прототип. При доступе к полю foo.toString сначала выполняется поиск такого свойства у самого объекта, а потом у его прототипа, прототипа его прототипа, и так пока цепочка прототипов не закончится. Это похоже на односвязный список объектов, где поочередно проверяется объект и его объекты-прототипы. Так реализовано наследование свойств, например, у (почти, но об этом позже) любого объекта есть методы valueOf и toString .
Как выглядит прототип
У всех прототипов имеются два общих свойства, constructor и __proto__ . Свойство constructor указывает на функцию-конструктор, с помощью которой создавался объект, а свойство __proto__ указывает на следующий прототип в цепочке (либо null, если это последний прототип). Остальные свойства доступны через . , как в примере выше.
Да кто такой этот ваш constructor
constructor – это ссылка на функцию, с помощью которой был создан объект:
Не совсем понятна идея зачем он был нужен, возможно, как способ клонирования объекта:
Но я не нашел подходящий пример его использования, если у Вас есть примеры проектов, где это использовалось, то напишите об этом. В остальном же использовать constructor лучше не стоит, так как это writable свойство, которое можно случайно перезаписать, работая с прототипом, и сломать часть логики.
Где живёт прототип
На самом деле, объекты представляют собой не только поля, доступные для JS кода. Интерпретатор также сохраняет некоторые приватные данные объекта для работы с ним, для этого в стандарте определено понятие внутренних слотов, которые обозначены как имя в квадратных скобках [[SlotName]] . Для прототипов отведен приватный слот [[Prototype]] содержащий ссылку на объект-прототип (либо null , если прототипа нет).
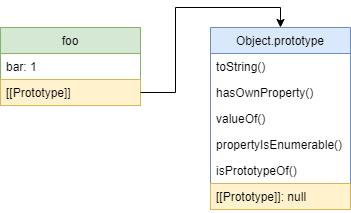
Из-за того, что [[Prototype]] предназначался исключительно для самого JS движка, получить доступ к прототипу объекта было невозможно. Для случаев когда это было нужно, ввели нестандартное свойство __proto__ , которое поддержали многие браузеры и которое по итогу попало в сам стандарт, но как опциональное и стандартизированное только для обратной совместимости с существующим JS кодом.
О чем вам недоговаривает дебаггер, или он вам не прототип
Свойство __proto__ является геттером и сеттером для внутреннего слота [[Prototype]] и находится в Object.prototype :
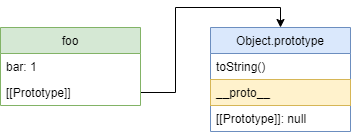
Из-за этого я избегал записи __proto__ для обозначения прототипа. __proto__ находится не в самом объекте, что приводит к неожиданным результатам. Для демонстрации попробуем через __proto__ удалить прототип объекта и затем восстановить его:
Как так получилось? Дело в том, что __proto__ – это унаследованное свойство Object.prototype , а не самого объекта foo . Из-за этого в момент когда в цепочке прототипов пропадает ссылка на Object.prototype , __proto__ превращается в тыкву и перестает работать с прототипом.
А теперь отработаем кликбейт из введения. Представим следующую цепочку прототипов:
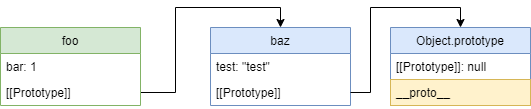
В консоли Chrome foo будет выглядеть следующим образом:

А теперь уберем связь между baz и Object.prototype :
И теперь в консоли Chrome видим следующий результат:
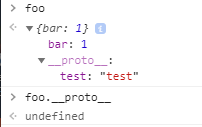
Связь с Object.prototype разорвана у baz и __proto__ возвращает undefined даже у дочернего объекта foo , однако Chrome все равно показывает что __proto__ есть. Скорее всего тут имеется в виду внутренний слот [[Prototype]] , но для простоты это было изменено на __proto__ , ведь если не извращаться с цепочкой прототипов, это будет верно.
Как работать с прототипом объекта
Рассмотрим основные способы работы с прототипом: изменение прототипа и создание нового объекта с указанным прототипом.
Для изменения прототипа у существующего объекта есть всего два метода: использование сеттера __proto__ и метод Object.setPrototypeOf .
Если браузер не поддерживает ни один из этих методов, то изменить прототип объекта невозможно, можно только создать его копию с новым прототипом.
Но есть один нюанс с внутренним слотом [[Extensible]] который указывает на то, возможно ли добавлять к нему новые поля и менять его прототип. Есть несколько функций, которые выставляют этот флаг в false и предотвращают смену прототипа: Object.freeze , Object.seal , Object.preventExtensions . Пример:
А теперь менее категоричный вопрос создания нового объекта с прототипом. Для этого есть следующие способы.
Стандартный способ:
Если нет поддержки Object.create , но есть __proto__ :
И в случае если отсутствует поддержка всего вышеперечисленного:
Способ основан на логике работы оператора new , о которой поговорим чуть ниже. Но сам способ основан на том, что оператор new берет свойство prototype функции и использует его в качестве прототипа, т.е. устанавливает объект в [[Prototype]] , что нам и нужно.
Функции и конструкторы
А теперь поговорим про функции и как они работают в качестве конструкторов.
Функция Person тут является конструктором и создает два поля в новом объекте, а цепочка прототипов выглядит так:
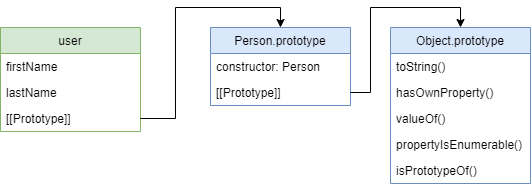
Откуда взялся Person.prototype ? При объявлении функции, у нее автоматически создается свойство prototype для того чтобы ее можно было использовать как конструктор (note 3), таким образом свойство prototype функции не имеет отношения к прототипу самой функции, а задает прототипы для дочерних объектов. Это позволит реализовывать наследование и добавлять новые методы, например так:

И теперь вызов user.fullName() вернет строку «John Doe».
Что такое new
На самом деле оператор new не таит в себе никакой магии. При вызове new выполняет несколько действий:
- Создает новый объект self
- Записывает свойство prototype функции конструктора в прототип объекта self
- Вызывает функцию конструктор с объектом self в качестве аргумента this
- Возвращает self если конструктор вернул примитивное значение, иначе возвращает значение из конструктора
Все эти действия можно сделать силами самого языка, поэтому можно написать свой собственный оператор new в виде функции:
Но начиная с ES6 волшебство пришло и к new в виде свойства new.target, которое позволяет определить, была ли вызвана функция как конструктор с new, или как обычная функция:
new.target будет undefined для обычного вызова функции, и ссылкой на саму функцию в случае вызова через new ;
Наследование
Зная все вышеперечисленное, можно сделать классическое наследование дочернего класса Student от класса Person . Для этого нужно
- Создать конструктор Student с вызовом логики конструктора Person
- Задать объекту `Student.prototype` прототип от `Person`
- Добавить новые методы к `Student.prototype`
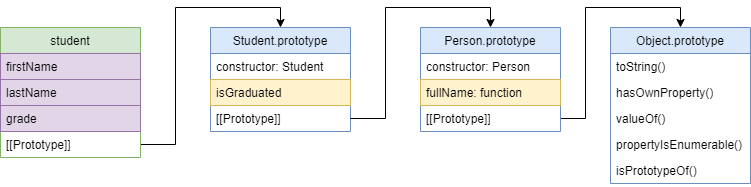
Фиолетовым цветом обозначены поля объекта (они все находятся в самом объекте, т.к. this у всей цепочки прототипов один), а методы желтым (находятся в прототипах соответствующих функций)
Вариант 1 предпочтительнее, т.к. Object.setPrototypeOf может привести к проблемам с производительностью.
Сколько вам сахара к классу
Для того чтобы облегчить классическую схему наследование и предоставить более привычный синтаксис, были представлены классы, просто сравним код с примерами Person и Student:
Уменьшился не только бойлерплейт, но и поддерживаемость:
- В отличие от функции конструктора, при вызове конструктора без new выпадет ошибка
- Родительский класс указывается ровно один раз при объявлении
При этом цепочка прототипов получается идентичной примеру с явным указанием prototype у функций конструкторов.
Наивно было бы ожидать, что одна статья ответит на все вопросы. Если у Вас есть интересные вопросы, экскурсы в историю, аргументированные или беспочвенные заявления о том, что я сделал все не так, либо правки по ошибкам, пишите в комментарии.
P. P. S.
К сожалению главный кликбейт статьи перестал быть актуальным. В данный момент Chrome (версия 93, на момент обновления статьи) перестал использовать __proto__ для обозначения прототипа, и теперь отображает его как слот [[Prototype]] :
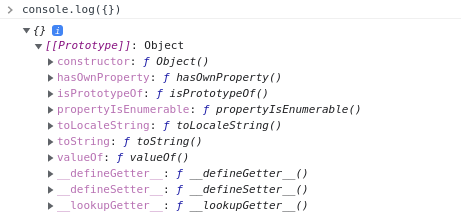
Справедливости ради хочу отметить что в Firefox (92) также не используется обозначение __proto__ :
13.3. Прототип функции.
Функции могут располагаться в исходном файле в любом порядке. А сама исходная программа, как отмечалось вначале, может размещаться в нескольких файлах.
При этом, однако, может возникнуть ошибка компиляции, если компилятор встретит вызов функции раньше, чем ее объявление. Для устранения этого используют описания (прототипы) функций.
Описание функции заключается в приведении в начале программного файла ее прототипа (заголовка). Прототип функции сообщает компилятору о том, что далее в тексте программы будет приведено ее полное определение: в текущем или другом файле исходного текста, либо в библиотеке, содержащей ее скомпилированный (объектный) код.
Прототип функции имеет вид:
тип_результата имя_функции (список) ;
В списке перечисляются типы параметров данной функции, причем имена этих параметров в круглых скобках прототипа указывать не обязательно. Прототип завершается точкой с запятой, в то время как в определении функции за списком параметров идет не точка с запятой, а фигурные скобки с телом функции. Это позволяет компилятору различать их. Описание дает возможность компилятору проверить соответствие типов и количества параметров при фактическом вызове этой функции. В определении и в описании одной и той же функции типы и порядок следования параметров должны совпадать. Тип возвращаемого значения и типы параметров совместно определяют тип функции.
Пример описания функции fun, которая имеет три параметра типа int, один параметр типа double и возвращает результат типа double:
double fun(int, int, int, double);
Пример описания для вышеприведенной функции Min:
int Min (int x, int y);
int Min (int, int);
13.4. Область видимости.
Область видимости (действия) объекта (переменной и др.) – это та часть кода (текста) программы, в которой его можно использовать.
В сложных программах ограничение этой области помогает избежать путаницы, вызванной использованием одинаковых имен в разных местах для разных целей. Например, количество чего-либо удобно обозначать буквой n. При этом в одной функции n может означать количество символов, а в другой — количество штук товара на складе. Присвоение n значения в одной функции тогда может испортить работу второй функции; но если в каждой функции своя, независимая переменная с именем n, такой проблемы не возникнет.
Основное правило видимости в языке Си: объект, объявленный внутри блока (участка программы, заключенного в фигурные скобки), как правило, виден, начиная с места его объявления и заканчивая концом этого блока ( > ). Если объявление данных лежит внутри нескольких входящих друг в друга блоков, оно считается расположенным в самом внутреннем из них. Если же нужно сделать объект видимым за пределами блока, нужно объявить его вне блока. Можно, например, объявить переменные вне всех функций; такие переменные называются глобальными, в отличие от переменных, объявленных внутри функции, называемых локальными и видимых только в пределах своей функции.
Область действия локальных данных – от точки декларации (объявления) до конца функции (блока), в которой произведено их объявление, включая все вложенные в него блоки.
Областью действия глобальных данных считается файл, в котором они определены, от точки описания до его окончания.
Если некоторое место программы входит в область видимости двух и более переменных с одинаковыми именами, объявленных на разном уровне вложенности блоков, действует та из них, которая объявлена на самом глубоком уровне. Объявление в одном и том же блоке на одном и том же уровне (или глобально — в одном и том же файле) переменных с одинаковыми именами вызывает ошибку компиляции.