Работа со строками
Довольно большое количество задач, которые могут встретиться при разработке приложений, так или иначе связано с обработкой строк — парсинг веб-страниц, поиск в тексте, какие-то аналитические задачи, связанные с извлечением нужной информации из текста и т.д. Поэтому в этом плане работе со строками уделяется особое внимание.
В языке C# строковые значения представляет тип string , а вся функциональность работы с данным типом сосредоточена в классе System.String . Собственно string является псевдонимом для класса String. Объекты этого класса представляют текст как последовательность символов Unicode. Максимальный размер объекта String может составлять в памяти 2 ГБ, или около 1 миллиарда символов.
Создание строк
Создавать строки можно, как используя переменную типа string и присваивая ей значение, так и применяя один из конструкторов класса String:
Конструктор String имеет различное число версий. Так, вызов конструктора
6 раз повторит объект из первого параметра, то есть фактически создаст строку «aaaaaa».
Еще один конструктор принимает массив символов, из которых создается строка
Третий использованный выше в примере конструктор позволяет создать строку из части массива символов. Второй параметр передает начальный индекс, с которого извлкаются символы, а третий параметр указывает на количество символов:
Строка как набор символов
Так как строка хранит коллекцию символов, в ней определен индексатор для доступа к этим символам:
Применяя индексатор, мы можем обратиться к строке как к массиву символов и получить по индексу любой из ее символов:
Используя свойство Length , как и в обычном массиве, можно получить длину строки.
Перебор строк
Класс String реализует интерфейс IEnumerable, благодаря чему строку можно перебрать в цикле foreach как набор объектов char. Также можно с помощью других типов циклов перебрать строку, применяя обращение к символам по индексу:
Сравнение строк
В отличие от других классов строки сравниваются по значению их символов, а не по ссылкам:
Многострочные строки
Начиная с C# 11 с помощью трех пар двойных кавычек можно оформить многострочный текст, в том числе с применением интерполяции:
Основные методы строк
Основная функциональность класса String раскрывается через его методы, среди которых можно выделить следующие:
Compare : сравнивает две строки с учетом текущей культуры (локали) пользователя
CompareOrdinal : сравнивает две строки без учета локали
Contains : определяет, содержится ли подстрока в строке
Concat : соединяет строки
CopyTo : копирует часть строки, начиная с определенного индекса в массив
EndsWith : определяет, совпадает ли конец строки с подстрокой
Format : форматирует строку
IndexOf : находит индекс первого вхождения символа или подстроки в строке
Insert : вставляет в строку подстроку
Join : соединяет элементы массива строк
LastIndexOf : находит индекс последнего вхождения символа или подстроки в строке
Replace : замещает в строке символ или подстроку другим символом или подстрокой
String c что это
String in C programming is a sequence of characters terminated with a null character ‘\0’. Strings are defined as an array of characters. The difference between a character array and a string is the string is terminated with a unique character ‘\0’.
Example of C String:
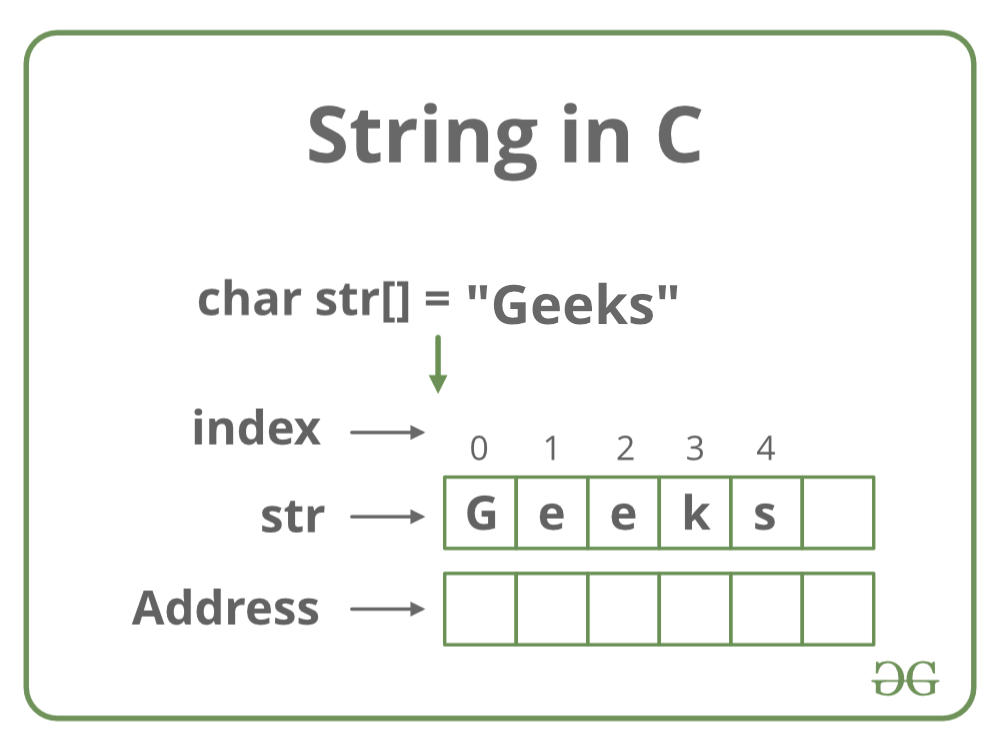
Declaration of Strings
Declaring a string is as simple as declaring a one-dimensional array. Below is the basic syntax for declaring a string.
In the above syntax str_name is any name given to the string variable and size is used to define the length of the string, i.e the number of characters strings will store.
Note: There is an extra terminating character which is the Null character (‘\0’) used to indicate the termination of a string that differs strings from normal character arrays. When a Sequence of characters enclosed in the double quotation marks is encountered by the compiler, a null character ‘\0’ is appended at the end of the string by default.
Initializing a String
A string can be initialized in different ways. We will explain this with the help of an example. Below are the examples to declare a string with the name str and initialize it with “GeeksforGeeks”.
4 Ways to Initialize a String in C
1. Assigning a string literal without size: String literals can be assigned without size. Here, the name of the string str acts as a pointer because it is an array.
2. Assigning a string literal with a predefined size: String literals can be assigned with a predefined size. But we should always account for one extra space which will be assigned to the null character. If we want to store a string of size n then we should always declare a string with a size equal to or greater than n+1.
3. Assigning character by character with size: We can also assign a string character by character. But we should remember to set the end character as ‘\0’ which is a null character.
4. Assigning character by character without size: We can assign character by character without size with the NULL character at the end. The size of the string is determined by the compiler automatically.
Below is the memory representation of the string “Geeks”.
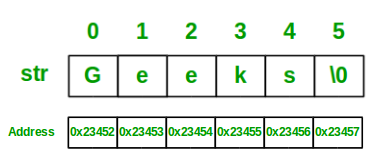
Let us now look at a sample program to get a clear understanding of declaring, initializing a string in C, and also how to print a string with its size.
Строки в C# и .NET

От переводчика: Джон Скит написал несколько статей о строках, и данная статья является первой, которую я решил перевести. Дальше планирую перевести статью о конкатенации строк, а потом — о Юникоде в .NET.
Тип System.String (в C# имеющий алиас string) является одним из наиболее часто используемых и важных типов в .NET, и вместе с тем одним из самых недопонимаемых. Эта статья описывает основы данного типа и развенчивает сложившиеся вокруг него мифы и непонимания.
Так что же такое string
Строка в .NET (далее — string, я не буду использовать полное имя System.String каждый раз) является последовательностью символов. Каждый символ является символом Юникода в диапазоне от U+0000 до U+FFFF (будет рассмотрено далее). Строковый тип имеет следующие характеристики:
Строка является ссылочным типом
Существует распространённое заблуждение о том, что строка является значимым типом. Это заблуждение истекает из свойства неизменяемости строки (см. следующий пункт), так как для неискушенного программиста неизменяемость часто по поведению кажется схожей со значимыми типами. Тем не менее, string — ссылочный тип, со всеми присущими ссылочным типам характеристиками. Я более детально расписал о различиях между ссылочными и значимыми типами в своих статьях «Parameter passing in C#» и «Memory in .NET — what goes where».
Строка является неизменяемой
Никак невозможно изменить содержимое созданной строки, по крайней мере в безопасном (safe) коде и без рефлексии. Поэтому вы при изменении строк изменяете не сами строки, а значения переменных, указывающих на строки. Например, код s = s.Replace («foo», «bar»); не изменяет содержимое строки s, которое было до вызова метода Replace — он просто переназначает переменную s на новообразованную строку, которая является копией старой за исключением всех подстрок «foo», заменённых на «bar».
Строка может содержать значение null
В языке C строки являются последовательностями символов, оканчивающимися символом ‘\0‘, также называемым «nul» или «null». Я называю его «null», так как именно такое название имеет символ ‘\0’ в таблице символов Юникода. Не путайте символ «null» с ключевым словом null в C# — тип System.Char является значимым, а потому не может принимать значение null . В .NET строки могут содержать символ «null» в любом месте и работать с ним без каких-либо проблем. Тем не менее, некоторые классы (к примеру, в Windows Forms) могут расценивать «null»-символ в строке как признак конца строки и не учитывать всё содержимое строки после этого символа, поэтому использование «null»-символов таки может стать проблемой.
Строка переопределяет оператор равенства ==
При вызове оператора == для определения равенства двух строк происходит вызов метода Equals , который сравнивает именно содержимое строк, а не равенство ссылок. К примеру, выражение «hello».Substring(0, 4)==»hell» возвратит true , хотя ссылки на строки по обеих сторонах оператора равенства разные (две ссылки ссылаются на два разных строковых экземпляра, которые, при этом, содержат одинаковые значения). Вместе с тем необходимо помнить, что равенство значений, а не ссылок происходит только тогда, когда оба операнда на момент компиляции являются строго строковым типом — оператор равенства не поддерживает полиморфизм. Поэтому если хотя бы один из сравниваемых операндов будет иметь тип object , к примеру (хотя внутренне и будет оставаться строкой), то будет выполнено сравнение ссылок, а не содержимого строк.
Интернирование
В .NET существует понятие «пула интернирования» (intern pool). По своей сути это всего лишь набор строк, но он обеспечивает то, что когда вы в разных местах программы используете разные строки с одним и тем же содержимым, то это содержимое будет храниться лишь один раз, а не создаваться каждый раз по-новому. Вероятно, пул интернирования зависит от конкретного языка, однако он определённо существует в C# и VB.NET, и я бы был очень удивлён, увидев язык на платформе .NET, не использующий пул интернирования; в MSIL пул интернирования очень просто использовать, гораздо проще, нежели не использовать. Наряду с автоматическим интернированием строковых литералов, строки можно интернировать вручную при помощи метода Intern , а также проверять, является ли та или иная строка уже интернированной при помощи метода IsInterned . Метод IsInterned не интуитивен, так как вы ожидаете, что он возвратит Boolean , а вот и нет — если текущая строка уже существует в пуле интернирования, то метод возвратит ссылку на неё, а если не существует, то null . Подобно ему, метод Intern возвращает ссылку на интернированную строку, причём вне зависимости от того, была ли текущая строка в пуле интернирования до вызова метода, или же она была туда занесена вместе с вызовом метода, или же пул интернирования содержит копию текущей строки.
Литералы
- \’ — одинарная кавычка, используется для объявления литералов типа System.Char
- \» — двойная кавычка, используется для объявления строковых литералов
- \\ — обратный слеш
- \0 — null-символ в Юникоде
- \a — символ Alert (№7)
- \b — символ Backspace (№8)
- \f —смена страницы FORM FEED (№12)
- \n — перевод строки (№10)
- \r — возврат каретки (№13)
- \t — горизонтальная табуляция (№9)
- \v — вертикальная табуляция (№11)
- Uxxxx — символ Юникода с шестнадцатеричным кодом xxxx
- \xn[n][n][n] — символ Юникода с шестнадцатеричным кодом nnnn, версия предыдущего пункта с переменной длиной цифр кода
- \Uxxxxxxxx — символ Юникода с шестнадцатеричным кодом xxxxxxxx, используется для вызова суррогатных пар.
Строки и отладчик
Довольно часто при просмотре строк в отладчике (используя VS.NET 2002 и VS.NET 2003) люди сталкиваются с проблемами. Ирония в том, что эти проблемы чаще всего создаёт отладчик, пытаясь быть полезным. Иногда он отображает строку в виде стандартного литерала, экранируя обратными слешами все спецсимволы, а иногда он отображает строку в виде дословного литерала, оглавляя её @. Поэтому многие спрашивают, как удалить из строки @, хотя его там фактически нет. Кроме этого, отладчики в некоторых версиях VS.NET не отображают строки с момента первого вхождения null-символа \0, и что ещё хуже, неправильно вычисляют их длины, так как подсчитывают их самостоятельно вместо запроса к управляемому коду. Естественно, всё это из-за того, что отладчики рассматривают \0 как признак окончания строки.
Учитывая такую путаницу, я пришел к выводу, что при отладке подозрительных строк их следует рассматривать множеством способов, дабы исключить все недоразумения. Я предлагаю использовать приведённый ниже метод, который будет печатать содержимое строки в консоль «правильным» способом. В зависимости от того, какое приложение вы разрабатываете, вы можете вместо вывода в консоль записывать строки в лог-файл, отправлять в трассировщики, выводит в модальном Windows-окне и т.д.
Использование памяти и внутренняя структура
В текущей реализации .NET Framework каждая строка занимает 20+(n/2)×4 байт, где n — количество символов в строке или, что одно и то же, её длина. Строковый тип необычен тем, что его фактический размер в байтах изменяется им самим. Насколько я знаю, так могут делать только массивы. По факту, строка — это и есть массив символов, расположенный в памяти, а также число, обозначающее фактический размер массива в памяти, а также число, обозначающее фактическое количество символов в массиве. Как вы уже поняли, длина массива не обязательно равна длине строки, так как строки могут перераспределяться со стороны mscorlib.dll для облегчения их обработки. Так само делает, к примеру, StringBuilder . И хотя для внешнего мира строки неизменяемые, внутри mscorlib они ещё как изменяемые. Таким образом, StringBuilder при создании строки выделяет несколько больший символьный массив, нежели того требует текущий литерал, а потом прибавляет новые символы в созданный массив до тех пор, пока они «влезают». Как только массив заполняется, создаётся новый, ещё больший массив, и в него копируется содержимое из старого. Кроме этого, в числе, обозначающем длину строки, первый бит отведён под специальный флаг, определяющий, содержит ли строка не-ASCII символы или нет. Благодаря этому флагу исполняющая среда в некоторых случаях может проводить дополнительные оптимизации.
Хотя со стороны API строки не являются null-терминированными, внутренне символьные массивы, представляющие строки, являются. А это значит, что строки из .NET могут напрямую передаваться в неуправляемый код безо всякого копирования, предполагая, что при таком взаимодействии строки будут маршаллированы как Юникод.
Кодировки строк
Если вы не знакомы с кодировками символов и Юникодом, пожалуйста, прочтите сначала мою статью о Юникоде (или её перевод на Хабре).
Как я уже сказал вначале статьи, строки всегда хранятся в Юникод-кодировке. Всякие домыслы о Big-5-кодировках или UTF-8-кодировках являются ошибкой (по крайней мере, по отношению к .NET) и являются следствием незнания самих кодировок или того, как .NET обрабатывает строки. Очень важно понять этот момент — рассматривание строки как такой, которая содержит некий валидный текст в кодировке, отличной от Юникода, почти всегда является ошибкой.
Далее, набор символов, поддерживаемых Юникодом (одним из недостатков Юникода является то, что один термин используется для разных вещей, включая кодировки и схемы кодировок символов), превышает 65536 символов. А это значит, что один char (System.Char) не может содержать любой символ Юникода. А это приводит к понятию суррогатных пар, где символы с кодом выше U+FFFF представляются в виде двух символов. По сути, строки в .NET используют кодировку UTF-16. Возможно, большинству разработчиков и не нужно углубляться касательно этого в детали, но по крайней мере это стоит знать.
Региональные и интернациональные странности
Некоторые странности в Юникоде ведут к странностям при работе со строками и символами. Большинство строковых методов зависимы от региональных настроек (являются culture-sensitive — регионально-чувствительными), — другими словами, работа методов зависит от региональных настроек потока, в котором эти методы выполняются. Например, как вы думаете, что возвратит этот метод «i».toUpper() ? Большинство скажут: «I», а вот и нет! Для турецких региональных настроек метод вернёт «İ» (код U+0130, описание символа: «Latin capital I with dot above»). Для выполнения регионально-независимой смены регистра вы можете использовать свойство CultureInfo.InvariantCulture и передать его как параметр в перегруженную версию метода String.ToUpper , которая принимает CultureInfo .
Есть и другие странности, связанные со сравнением и сортировкой строк, а также с нахождением индекса подстроки в строке. Некоторые из этих операций регионально-зависимы, а некоторые — нет. Например, для всех регионов (насколько я могу видеть) литералы «lassen» и «la\u00dfen» (во втором литерале шестнадцатеричным кодом указан символ «S острое» или «эсце́т») определяются как равные при передачи их в методы CompareTo или Compare , но вот если передать их в Equals , то будет определено неравенство. Метод IndexOf будет учитывать эсцет как «ss» (двойное «s»), но вот если вы используете одну из перегрузок CompareInfo.IndexOf , где укажете CompareOptions.Ordinal , то эсцет будет обработан правильно.
Некоторые символы Юникода вообще абсолютно невидимы для стандартного метода IndexOf . Однажды кто-то спросил в группе новостей C#, почему метод поиска и замены уходит в бесконечный цикл. Этот человек использовал метод Replace для замены всех сдвоенных пробелов одним, а потом проверял, окончилась ли замена и нет ли больше сдвоенных пробелов в строке, используя IndexOf . Если IndexOf показывал, что сдвоенные пробелы есть, строка снова отправлялась на обработку к Replace . К сожалению, всё это «ломалось», так как в строке присутствовал некий «неправильный» символ, расположенный точно между двумя пробелами. IndexOf сообщал о присутствии сдвоенного пробела, игнорируя этот символ, а Replace не выполнял замену, так как «видел» символ. Я так и не узнал, что это был за символ, но подобная ситуация легко воспроизводится при помощи символа U+200C, который является «не-связующим символом нулевой ширины» (англ. zero-width non-joiner character), что бы это не значило, чёрт возьми! Поместите такой или ему подобный в вашу строку, и IndexOf будет его игнорировать, а Replace — нет. Снова-таки, чтобы заставить оба метода работать одинаково, вы можете использовать CompareInfo.IndexOf и указать ему CompareOptions.Ordinal . Мне кажется, что уже написано достаточно много кода, который будет «валиться» на таких «неудобных» данных. И я даже не намекаю, что мой собственный код застрахован от подобного.
Microsoft опубликовала некоторые рекомендации касательно обработки строк, и хотя они датируются 2005-м годом, их всё ещё сто́ит прочесть.
Строки
С точки зрения регулярного программирования строковый тип данных string относится к числу самых важных в C#. Этот тип определяет и поддерживает символьные строки. В целом ряде других языков программирования строка представляет собой массив символов. А в C# строки являются объектами. Следовательно, тип string относится к числу ссылочных.
Построение строк
Самый простой способ построить символьную строку — воспользоваться строковым литералом. Например, в следующей строке кода переменной ссылки на строку str присваивается ссылка на строковый литерал:
В данном случае переменная str инициализируется последовательностью символов «Пример строки». Объект типа string можно также создать из массива типа char. Например:
Как только объект типа string будет создан, его можно использовать везде, где только требуется строка текста, заключенного в кавычки.
Постоянство строк
Как ни странно, содержимое объекта типа string не подлежит изменению. Это означает, что однажды созданную последовательность символов изменить нельзя. Но данное ограничение способствует более эффективной реализации символьных строк. Поэтому этот, на первый взгляд, очевидный недостаток на самом деле превращается в преимущество. Так, если требуется строка в качестве разновидности уже имеющейся строки, то для этой цели следует создать новую строку, содержащую все необходимые изменения. А поскольку неиспользуемые строковые объекты автоматически собираются в «мусор», то о дальнейшей судьбе ненужных строк можно даже не беспокоиться.
Следует, однако, подчеркнуть, что переменные ссылки на строки (т.е. объекты типа string) подлежат изменению, а следовательно, они могут ссылаться на другой объект. Но содержимое самого объекта типа string не меняется после его создания.
Скомпилируем приложение и загрузим результирующую сборку в утилиту ildasm.exe. На рисунке показан CIL-код, который будет сгенерирован для метода void addNewString():

Обратите внимание на наличие многочисленных вызовов кода операции ldstr (загрузка строки). Этот код операции ldstr в CIL предусматривает выполнение загрузки нового объекта string в управляемую кучу. В результате предыдущий объект, в котором содержалось значение «This is my stroke», будет в конечном итоге удален сборщиком мусора.
Работа со строками
В классе System.String предоставляется набор методов для определения длины символьных данных, поиска подстроки в текущей строке, преобразования символов из верхнего регистра в нижний и наоборот, и т.д. Далее мы рассмотрим этот класс более подробно.
Поле, индексатор и свойство класса String
В классе String определено единственное поле:
Поле Empty обозначает пустую строку, т.е. такую строку, которая не содержит символы. Этим оно отличается от пустой ссылки типа String, которая просто делается на несуществующий объект.
Помимо этого, в классе String определен единственный индексатор, доступный только для чтения:
Этот индексатор позволяет получить символ по указанному индексу. Индексация строк, как и массивов, начинается с нуля. Объекты типа String отличаются постоянством и не изменяются, поэтому вполне логично, что в классе String поддерживается индексатор, доступный только для чтения.
И наконец, в классе String определено единственное свойство, доступное только для чтения:
Свойство Length возвращает количество символов в строке. В примере ниже показано использование индексатора и свойства Length:
Операторы класса String
В классе String перегружаются два следующих оператора: == и !=. Оператор == служит для проверки двух символьных строк на равенство. Когда оператор == применяется к ссылкам на объекты, он обычно проверяет, делаются ли обе ссылки на один и тот же объект. А когда оператор == применяется к ссылкам на объекты типа String, то на предмет равенства сравнивается содержимое самих строк. Это же относится и к оператору !=. Когда он применяется к ссылкам на объекты типа String, то на предмет неравенства сравнивается содержимое самих строк. В то же время другие операторы отношения, в том числе =, сравнивают ссылки на объекты типа String таким же образом, как и на объекты других типов. А для того чтобы проверить, является ли одна строка больше другой, следует вызвать метод Compare(), определенный в классе String.
Как станет ясно дальше, во многих видах сравнения символьных строк используются сведения о культурной среде. Но это не относится к операторам == и !=. Ведь они просто сравнивают порядковые значения символов в строках. (Иными словами, они сравнивают двоичные значения символов, не видоизмененные нормами культурной среды, т.е. региональными стандартами.) Следовательно, эти операторы выполняют сравнение строк без учета регистра и настроек культурной среды.
Методы класса String
В следующей таблице перечислены некоторые наиболее интересные методы этого класса, сгруппированные по назначению:
public static int Compare(string strA, string strB, bool ignoreCase)
public static int Compare(string strA, string strB, StringComparison comparisonType)
public static int Compare(string strA, string strB, bool ignoreCase, CultureInfo culture)
Статический метод, сравнивает строку strA со строкой strB. Возвращает положительное значение, если строка strA больше строки strB; отрицательное значение, если строка strA меньше строки strB; и нуль, если строки strA и strB равны. Сравнение выполняется с учетом регистра и культурной среды.
Если параметр ignoreCase принимает логическое значение true, то при сравнении не учитываются различия между прописным и строчным вариантами букв. В противном случае эти различия учитываются.
Параметр comparisonType определяет конкретный способ сравнения строк. Класс CultureInfo определен в пространстве имен System.Globalization.
public static int Compare(string strA, int indexA, string strB, int indexB, int length, bool ignoreCase)
public static int Compare(string strA, int indexA, string strB, int indexB, int length, StringComparison comparisonType)
Сравнивает части строк strA и strB. Сравнение начинается со строковых элементов strA[indexA] и strB[indexB] и включает количество символов, определяемых параметром length. Метод возвращает положительное значение, если часть строки strA больше части строки strB; отрицательное значение, если часть строки strA меньше части строки strB; и нуль, если сравниваемые части строк strA и strB равны. Сравнение выполняется с учетом регистра и культурной среды.
Делает то же, что и метод Compare(), но без учета локальных установок
Сравнивает вызывающую строку со строковым представлением объекта value. Возвращает положительное значение, если вызывающая строка больше строки value; отрицательное значение, если вызывающая строка меньше строки value; и нуль, если сравниваемые строки равны
Сравнивает вызывающую строку со строкой strB
Возвращает логическое значение true, если вызывающая строка содержит ту же последовательность символов, что и строковое представление объекта obj. Выполняется порядковое сравнение с учетом регистра, но без учета культурной среды
Возвращает логическое значение true, если вызывающая строка содержит ту же последовательность символов, что и строка value. Выполняется порядковое сравнение с учетом регистра, но без учета культурной среды. Параметр comparisonType определяет конкретный способ сравнения строк
Возвращает логическое значение true, если строка a содержит ту же последовательность символов, что и строка b . Выполняется порядковое сравнение с учетом регистра, но без учета культурной среды. Параметр comparisonType определяет конкретный способ сравнения строк
Возвращает логическое значение true, если вызывающая строка начинается с подстроки value. В противном случае возвращается логическое значение false. Параметр comparisonType определяет конкретный способ выполнения поиска
Возвращает логическое значение true, если вызывающая строка оканчивается подстрокой value. В противном случае возвращает логическое значение false. Параметр comparisonType определяет конкретный способ поиска
Находит первое вхождение заданной подстроки или символа в строке. Если искомый символ или подстрока не обнаружены, то возвращается значение -1
public int IndexOf(string value, int startIndex)
public int IndexOf(char value, int startIndex, int count)
Возвращает индекс первого вхождения символа или подстроки value в вызывающей строке. Поиск начинается с элемента, указываемого по индексу startIndex, и охватывает число элементов, определяемых параметром count (если указан). Метод возвращает значение -1, если искомый символ или подстрока не обнаружен
То же, что IndexOf, но находит последнее вхождение символа или подстроки, а не первое
public int IndexOfAny(char[] anyOf, int startIndex)
Возвращает индекс первого вхождения любого символа из массива anyOf, обнаруженного в вызывающей строке. Поиск начинается с элемента, указываемого по индексу startIndex, и охватывает число элементов, определяемых параметром count (если они указаны). Метод возвращает значение -1, если не обнаружено совпадение ни с одним из символов из массива anyOf. Поиск осуществляется порядковым способом
Возвращает индекс последнего вхождения любого символа из массива anyOf, обнаруженного в вызывающей строке
Метод, возвращающий массив string с присутствующими в данном экземпляре подстроками внутри, которые отделяются друг от друга элементами из указанного массива char или string.
В первой форме метода Split() вызывающая строка разделяется на составные части. В итоге возвращается массив, содержащий подстроки, полученные из вызывающей строки. Символы, ограничивающие эти подстроки, передаются в массиве separator. Если массив separator пуст или ссылается на пустую строку, то в качестве разделителя подстрок используется пробел. А во второй форме данного метода возвращается количество подстрок, определяемых параметром count.
public string[] Split(string[] separator, StringSplitOptions options)
public string[] Split(params char[] separator, int count, StringSplitOptions options)
В двух первых формах метода Split() вызывающая строка разделяется на части и возвращается массив, содержащий подстроки, полученные из вызывающей строки. Символы, разделяющие эти подстроки, передаются в массиве separator. Если массив separator пуст, то в качестве разделителя используется пробел. А в третьей и четвертой формах данного метода возвращается количество строк, ограничиваемое параметром count.
Но во всех формах параметр options обозначает конкретный способ обработки пустых строк, которые образуются в том случае, если два разделителя оказываются рядом. В перечислении StringSplitOptions определяются только два значения: None и RemoveEmptyEntries. Если параметр options принимает значение None, то пустые строки включаются в конечный результат разделения исходной строки. А если параметр options принимает значение RemoveEmptyEntries, то пустые строки исключаются из конечного результата разделения исходной строки.
Строит новую строку, комбинируя содержимое массива строк.
В первой форме метода Join() возвращается строка, состоящая из сцепляемых подстрок, передаваемых в массиве value. Во второй форме также возвращается строка, состоящая из подстрок, передаваемых в массиве value, но они сцепляются в определенном количестве count, начиная с элемента массива value[startIndex]. В обеих формах каждая последующая строка отделяется от предыдущей разделительной строкой, определяемой параметром separator.
Метод, который позволяет удалять все вхождения определенного набора символов с начала и конца текущей строки.
В первой форме метода Trim() из вызывающей строки удаляются начальные и конечные пробелы. А во второй форме этого метода удаляются начальные и конечные вхождения в вызывающей строке символов из массива trimChars. В обеих формах возвращается получающаяся в итоге строка.
Позволяет дополнить строку символами слева.
Позволяет дополнить строку символами справа.
Используется для вставки одной строки в другую, где value обозначает строку, вставляемую в вызывающую строку по индексу startIndex. Метод возвращает получившуюся в итоге строку.
Используется для удаления части строки. В первой форме метода Remove() удаление выполняется, начиная с места, указываемого по индексу startIndex, и продолжается до конца строки. А во второй форме данного метода из строки удаляется количество символов, определяемое параметром count, начиная с места, указываемого по индексу startIndex.
Используется для замены части строки. В первой форме метода Replace() все вхождения символа oldChar в вызывающей строке заменяются символом newChar. А во второй форме данного метода все вхождения строки oldValue в вызывающей строке заменяются строкой newValue.
Делает заглавными все буквы в вызывающей строке.
Делает строчными все буквы в вызывающей строке.
В первой форме метода Substring() подстрока извлекается, начиная с места, обозначаемого параметром startIndex, и до конца вызывающей строки. А во второй форме данного метода извлекается подстрока, состоящая из количества символов, определяемых параметром length, начиная с места, обозначаемого параметром startIndex.
Пример следующей программы использует несколько из вышеуказанных методов:

Немного о сравнении строк в C#
Вероятно, из всех операций обработки символьных строк чаще всего выполняется сравнение одной строки с другой. Прежде чем рассматривать какие-либо методы сравнения строк, следует подчеркнуть следующее: сравнение строк может быть выполнено в среде .NET Framework двумя основными способами:
Во-первых, сравнение может отражать обычаи и нормы отдельной культурной среды, которые зачастую представляют собой настройки культурной среды, вступающие в силу при выполнении программы. Это стандартное поведение некоторых, хотя и не всех методов сравнения.
И во-вторых, сравнение может быть выполнено независимо от настроек культурной среды только по порядковым значениям символов, составляющих строку. Вообще говоря, при сравнении строк без учета культурной среды используется лексикографический порядок (и лингвистические особенности), чтобы определить, является ли одна строка больше, меньше или равной другой строке. При порядковом сравнении строки просто упорядочиваются на основании невидоизмененного значения каждого символа.
В силу отличий способов сравнения строк с учетом культурной среды и порядкового сравнения, а также последствий каждого такого сравнения настоятельно рекомендуется руководствоваться лучшими методиками, предлагаемыми в настоящее время корпорацией Microsoft. Ведь выбор неверного способа сравнения строк может привести к неправильной работе программы, когда она эксплуатируется в среде, отличающей от той, в которой она разработана.
Выбор способа сравнения символьных строк представляет собой весьма ответственное решение. Как правило и без всяких исключений, следует выбирать сравнение строк с учетом культурной среды, если это делается для целей отображения результата пользователю (например, для вывода на экран ряда строк, отсортированных в лексикографическом порядке). Но если строки содержат фиксированную информацию, не предназначенную для видоизменения с учетом отличий в культурных средах, например, имя файла, ключевое слово, адрес веб-сайта или значение, связанное с обеспечением безопасности, то следует выбрать порядковое сравнение строк. Разумеется, особенности конкретного разрабатываемого приложения будут диктовать выбор подходящего способа сравнения символьных строк.
В классе String предоставляются самые разные методы сравнения строк, которые перечислены в таблице выше. Наиболее универсальным среди них является метод Compare(). Он позволяет сравнивать две строки полностью или частично, с учетом или без учета регистра, способа сравнения, определяемого параметром типа StringComparison, а также сведений о культурной среде, предоставляемых с помощью параметра типа CultureInfo.
Те перегружаемые варианты метода Compare(), которые не содержат параметр типа StringComparison, выполняют сравнение символьных строк с учетом регистра и культурной среды. А в тех перегружаемых его вариантах, которые не содержат параметр типа CultureInfo, сведения о культурной среде определяются текущей средой выполнения.
Тип StringComparison представляет собой перечисление, в котором определяются значения, приведенные в таблице ниже. Используя эти значения, можно организовать сравнение строк, удовлетворяющее потребностям конкретного приложения. Следовательно, добавление параметра типа StringComparison расширяет возможности метода Compare() и других методов сравнения, например, Equals(). Это дает также возможность однозначно указывать способ предполагаемого сравнения строк.
В силу имеющих отличий между сравнением строк с учетом культурной среды и порядковым сравнением очень важно быть предельно точным в этом отношении.
| Значение | Описание |
|---|---|
| CurrentCulture | Сравнение строк производится с использованием текущих настроек параметров культурной среды |
| CurrentCultureIgnoreCase | Сравнение строк производится с использованием текущих настроек параметров культурной среды, но без учета регистра |
| InvariantCulture | Сравнение строк производится с использованием неизменяемых, т.е. универсальных данных о культурной среде |
| InvariantCultureIgnoreCase | Сравнение строк производится с использованием неизменяемых, т.е. универсальных данных о культурной среде и без учета регистра |
| Ordinal | Сравнение строк производится с использованием порядковых значений символов в строке. При этом лексикографический порядок может нарушиться, а условные обозначения, принятые в отдельной культурной среде, игнорируются |
| OrdinalIgnoreCase | Сравнение строк производится с использованием порядковых значений символов в строке, но без учета регистра |
В любом случае метод Compare() возвращает отрицательное значение, если первая сравниваемая строка оказывается меньше второй; положительное значение, если первая сравниваемая строка больше второй; и наконец, нуль, если обе сравниваемые строки равны. Несмотря на то что метод Compare() возвращает нуль, если сравниваемые строки равны, для определения равенства символьных строк, как правило, лучше пользоваться методом Equals() или же оператором ==.
Дело в том, что метод Compare() определяет равенство сравниваемых строк на основании порядка их сортировки. Так, если выполняется сравнение строк с учетом культурной среды, то обе строки могут оказаться одинаковыми по порядку их сортировки, но не равными по существу. По умолчанию равенство строк определяется в методе Equals(), исходя из порядковых значений символов и без учета культурной среды. Следовательно, по умолчанию обе строки сравниваются в этом методе на абсолютное, посимвольное равенство подобно тому, как это делается в операторе ==.
Несмотря на большую универсальность метода Compare(), для простого порядкового сравнения символьных строк проще пользоваться методом CompareOrdinal(). И наконец, следует иметь в виду, что метод CompareTo() выполняет сравнение строк только с учетом культурной среды.
В приведенной ниже программе демонстрируется применение методов Compare(), Equals(), CompareOrdinal(), а также операторов == и != для сравнения символьных строк. Обратите внимание на то, что два первых примера сравнения наглядно демонстрируют отличия между сравнением строк с учетом культурной среды и порядковым сравнением в англоязычной среде: